SpringCloud 网飞系 转换阿里系2
本次内容概述 1. seata集成 2. feign + sentinel +seata + @ControllerAdvice 互相影响产生的事务问题整理
1.seata部署
2.seata配置
这两步可以参考很多部署文档,把比较容易出问题的地方说明下

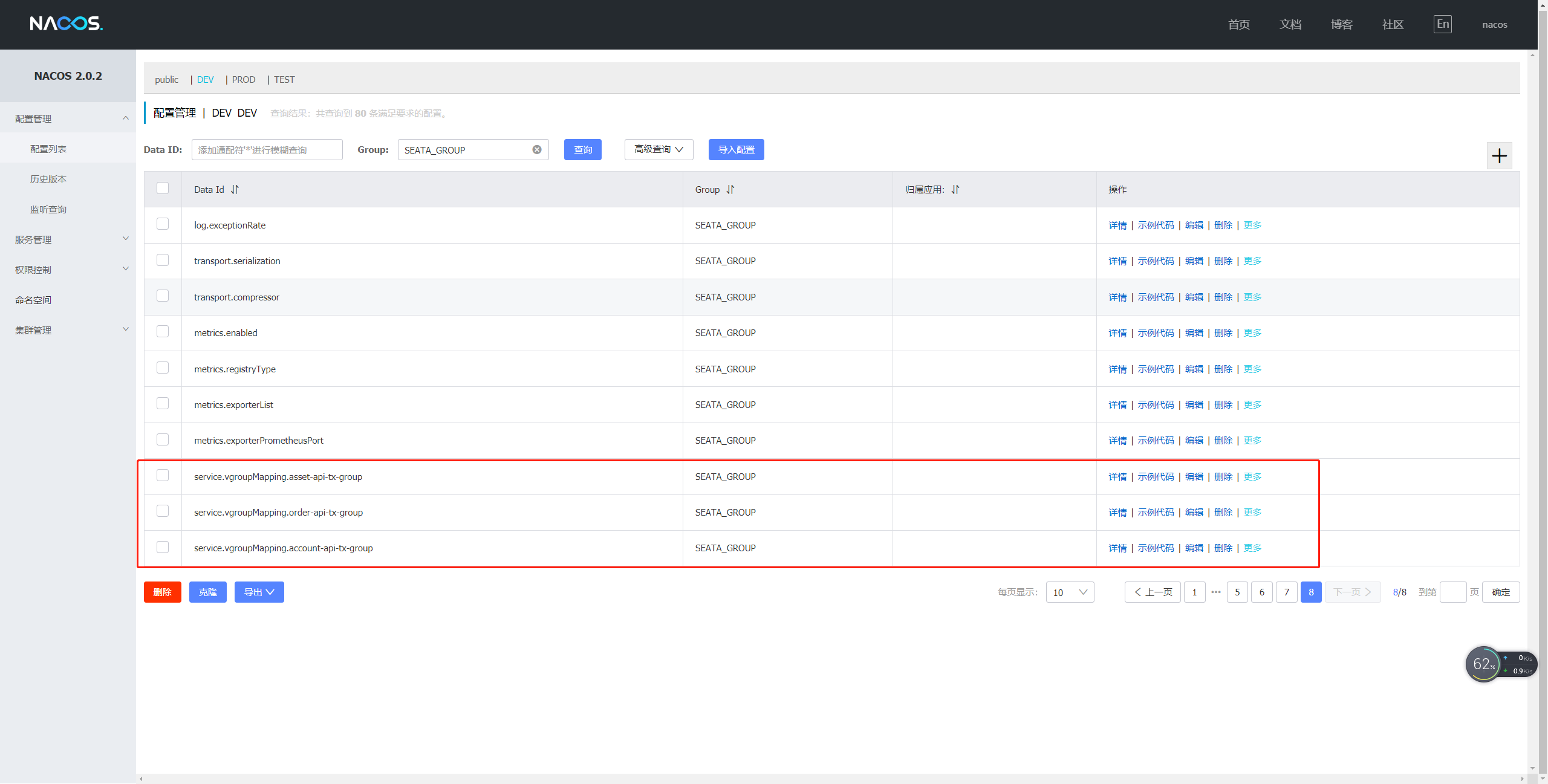
3.测试
一些总结说明:
熔断的概念不能和下游服务挂掉,注册中心不可用混淆。熔断应理解为多次超时达到熔断阈值而直接不进入代码块。
结合上一篇sentinel的配置可以得到如下结论
本地事务在不配置blockHandler、fallback情况下,熔断或流控抛出异常可被@Transactional拦截并保证事务;
feign事务在不配置blockHandler、fallback类的情况下,熔断或流控抛出异常可被@Transactional拦截并保证事务;
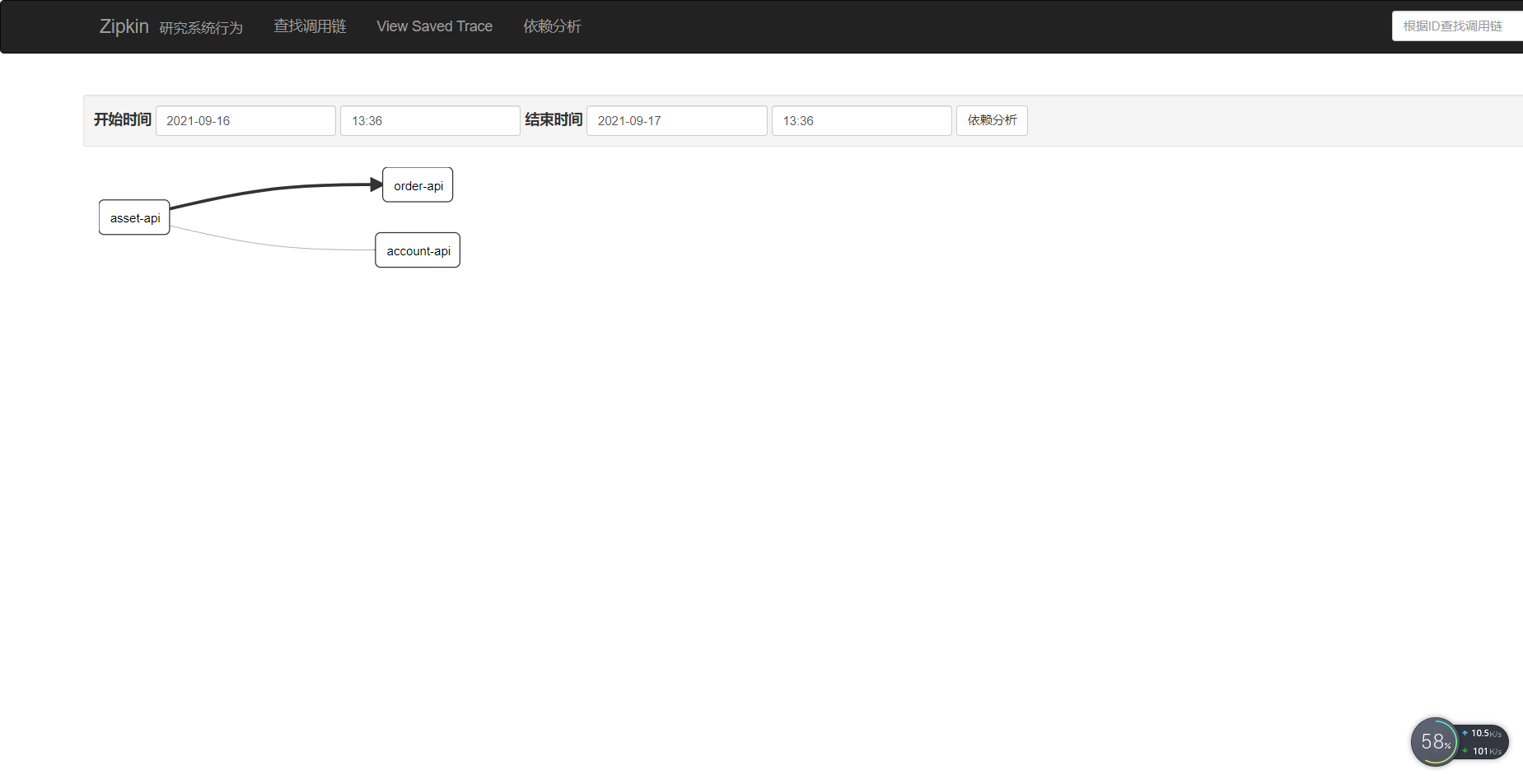
以上述链路为例,分别测试如下几种情况
首先是正常情况下,全部提交;可以看下几个关键日志的地方。
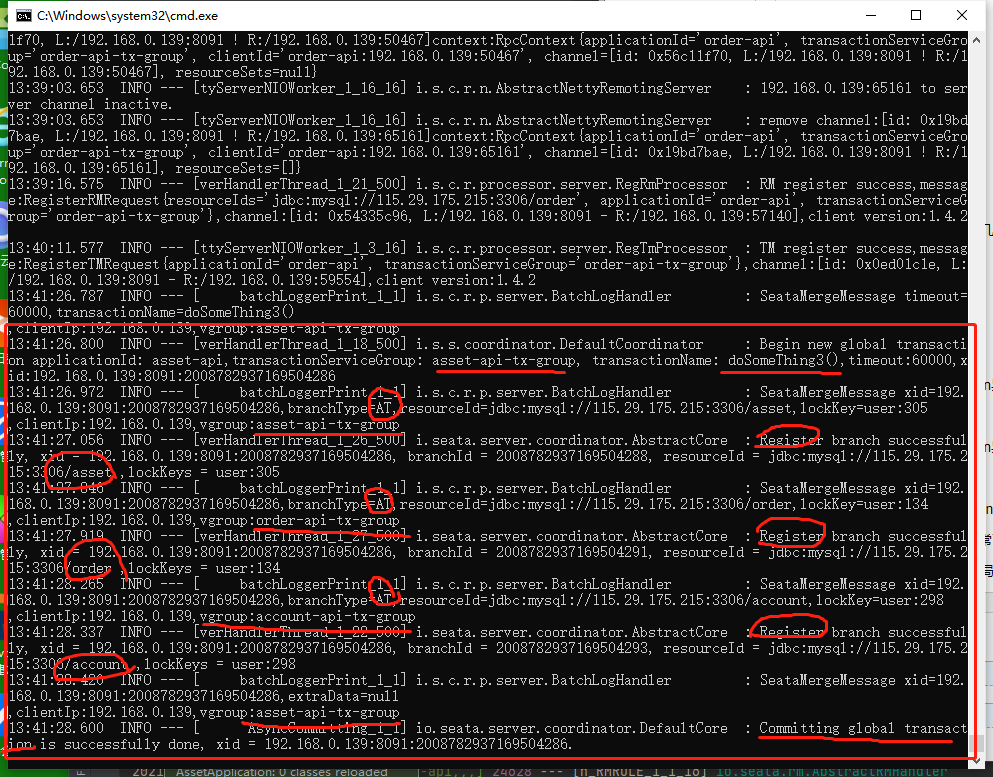
全局事务
场景1 下游服务挂了
直接上游可以拿到ribbon异常并回滚
把order-api停掉。上游服务feign客户端能马上感知到服务不可用的异常。

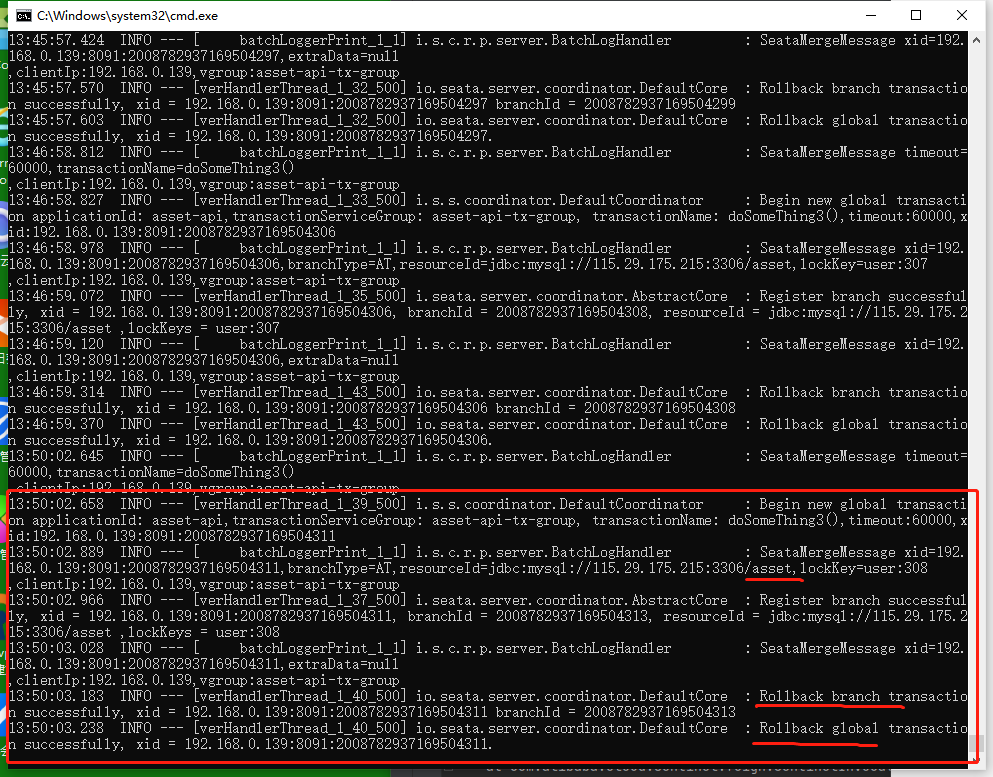
这里我们停order-api还不够明显,account-api还没执行。我们换下,就能发现有一个挂了,其他都能回滚。
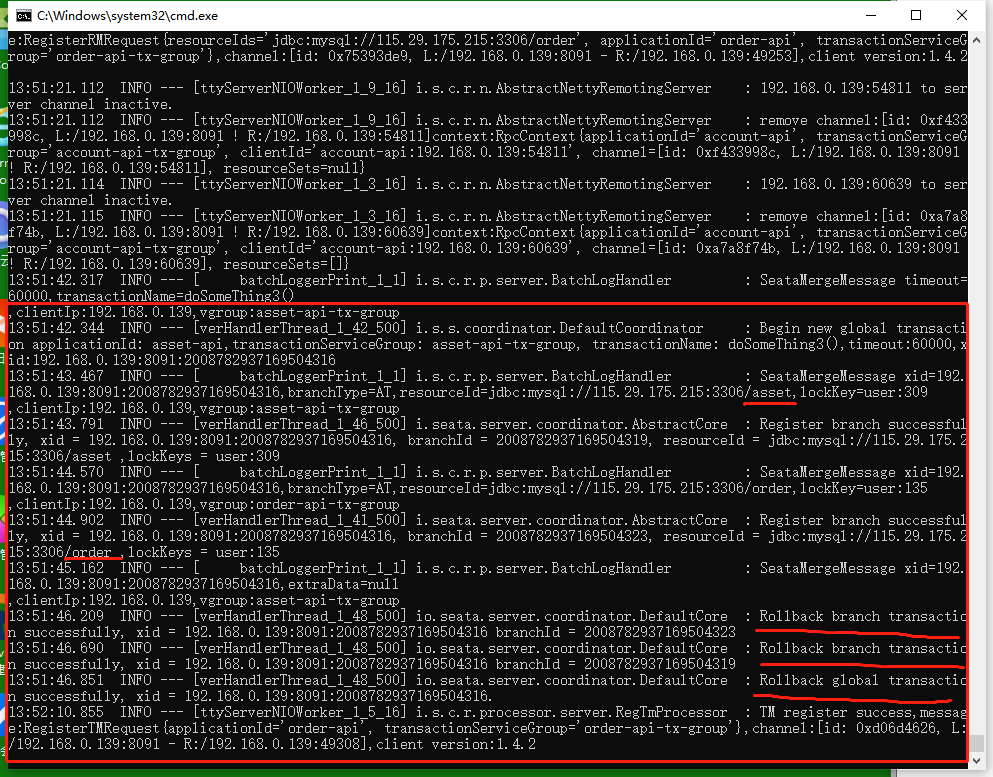
场景2 下游服务超时了
直接上有可以拿到ribbon异常并回滚,通知下游的事务也一起回滚
同理,我们都对account-api下手,给他加个sleep6秒的操作,因为我们ribbon超时设置的5秒。制作超时的场景。

显然也拿到了超时异常,可以直接回滚。

场景3 下游服务熔断了
直接上游可以拿到sentinel异常并回滚,在场景2的基础上,我们多试几次来达到sentinel的阈值模拟熔断。

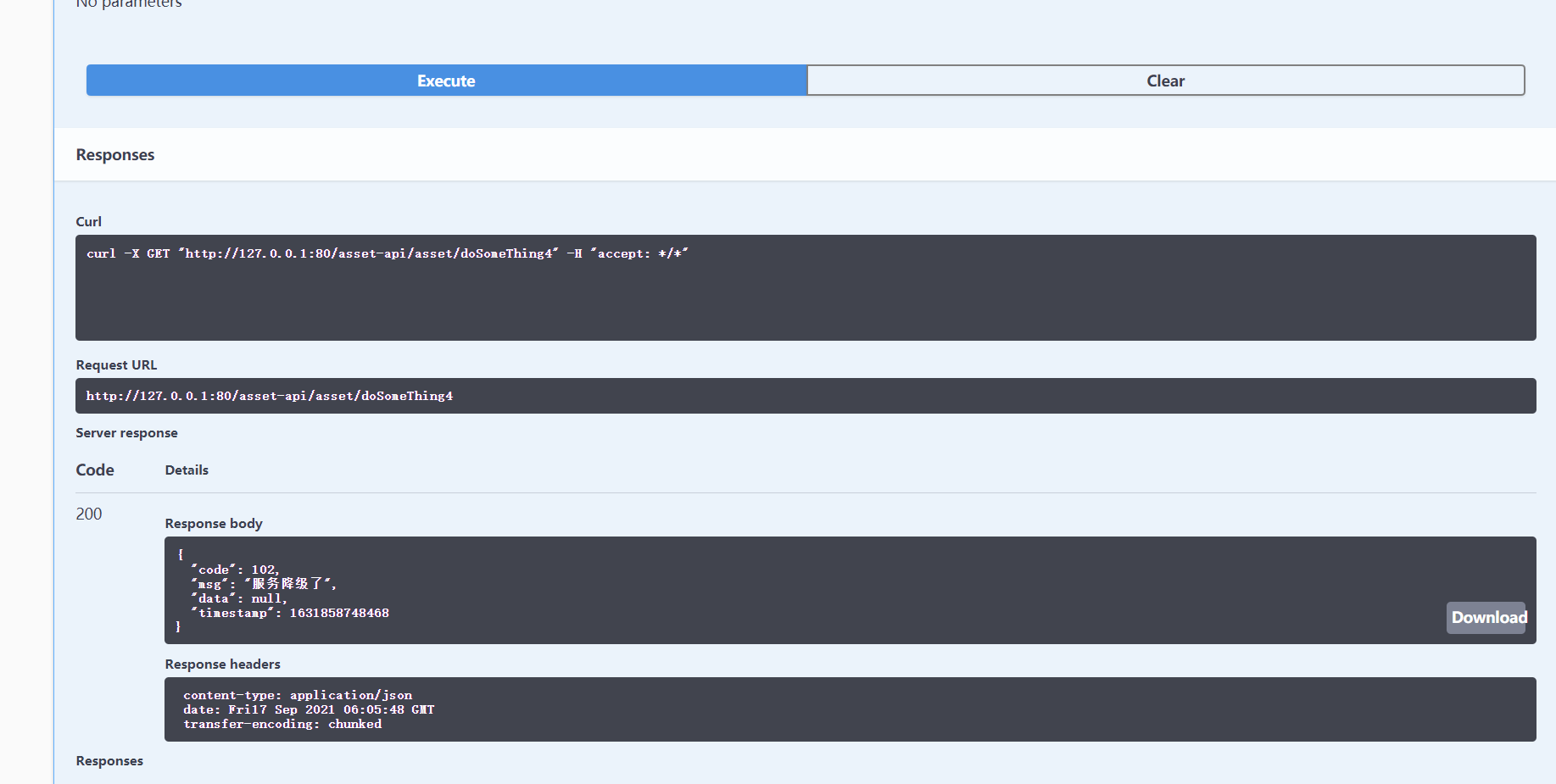

进入我们的feign降级熔断。值得一提,这里我们不管对本地还是feign的sentinel都是不直接捕获异常的。所以seata是能感知到
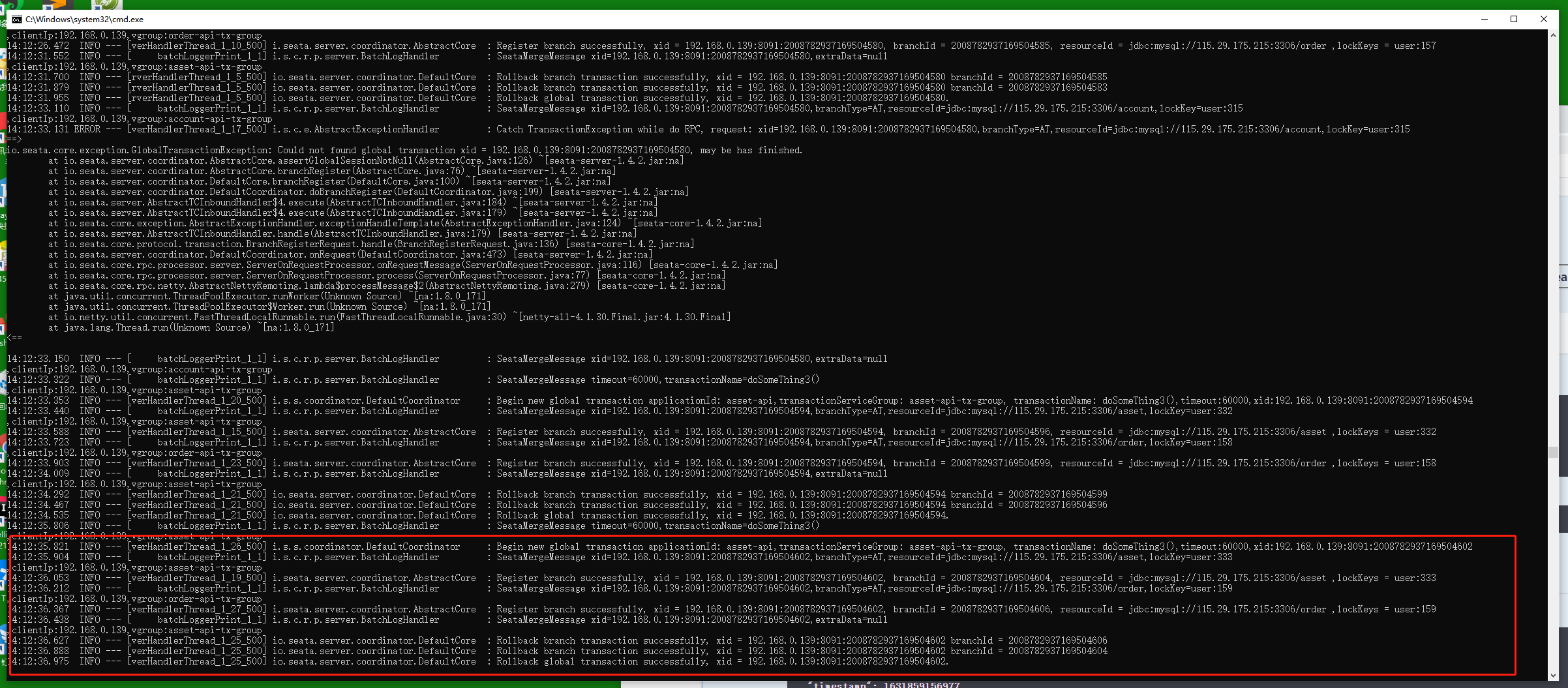
与场景2不同的是,下游熔断以后是直接返回拿到异常而不去尝试请求的,所以seata根本就不需要管理熔断的服务,只要把其他的服务回滚即可。
场景4 下游服务遇到业务异常了
此时如果我们配置了全局异常捕获@ControllerAdvice 对seata服务来说就感知不到异常。我们需要在@ControllerAdvice手动获取xid并回滚,seata通知所有相同的xid事务回滚。

我们给account-api随便给一个异常,观察。
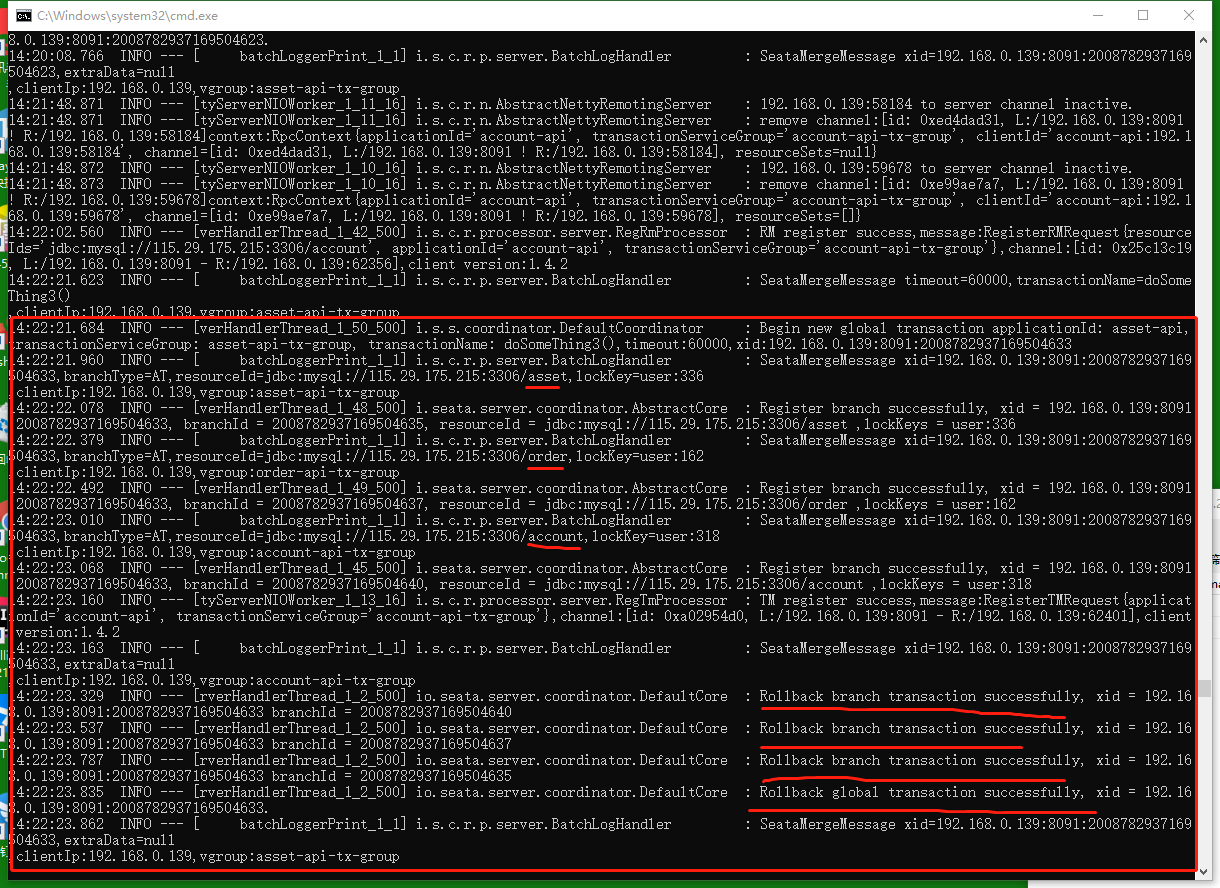
这里实际上seata是没有感知到异常的。只是我们在全局异常捕获的地方手动获取当前xid并手动回滚,seata通知其他一样的xid事务回滚;
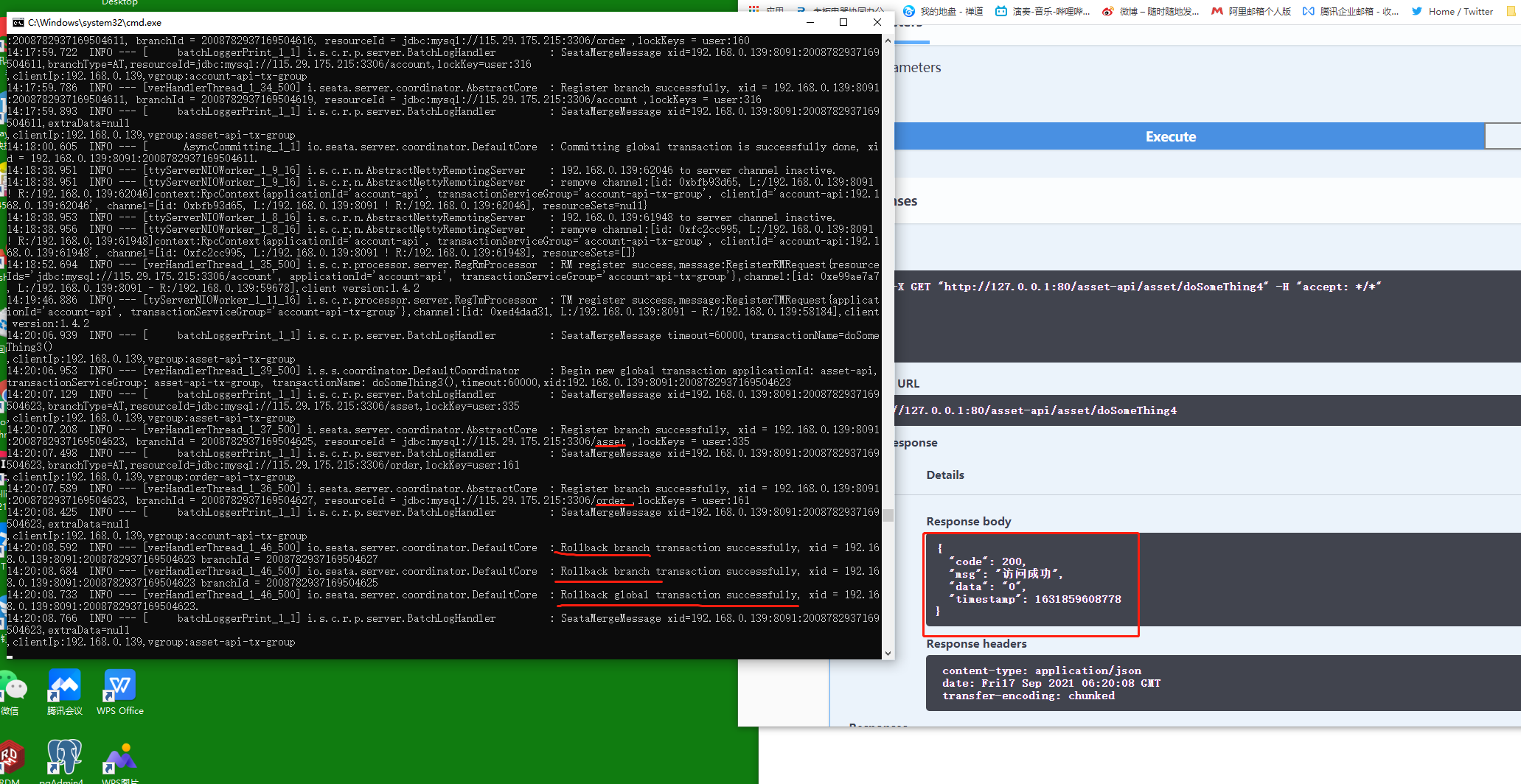
这里有个小细节,如果account-api的地方加了本地@Transactional,则本地自动回滚,seata不去重复操作了。
组件gitee https://gitee.com/xuetieqi/component-alibaba
项目gitee https://gitee.com/xuetieqi/base-server-alibaba

