Proj. CAR Paper Reading: Dire: A neural approach to decompiled identifier naming
Abstract
本文:
工具:DIRE(Decompiled Identifier Renaming Engine)
任务:variable name recovery
方法:使用词法和结构信息计算概率
提出数据集:164632 unique x86-64 binaries C projs on github
实验
效果:
- 74.3%相符
1. Intro
⼆进制⼤⼩、执⾏时间,甚⾄混淆。注释、变量名、⽤⼾定义类型和惯⽤结构都会在编译时丢失,并且通常在反编译器输出中不可⽤
假设:
- 程序员倾向于编写相似的代码并在相似的上下⽂中使⽤相同的变量名称
- 可以⾃动⽣成⼤量训练数据
已有方法:
- 直接在二进制文件上预测变量名(binary semantics):忽略了能够回复的rich abstraction
- lexical output of the decompiler: lack rich structural information
对齐调试、非调试符号:基于访问每个变量的指令地址集
3 Background
AST, N-Gram, Sentence Piece, RNN, GGNN
4 The Dire Architecture
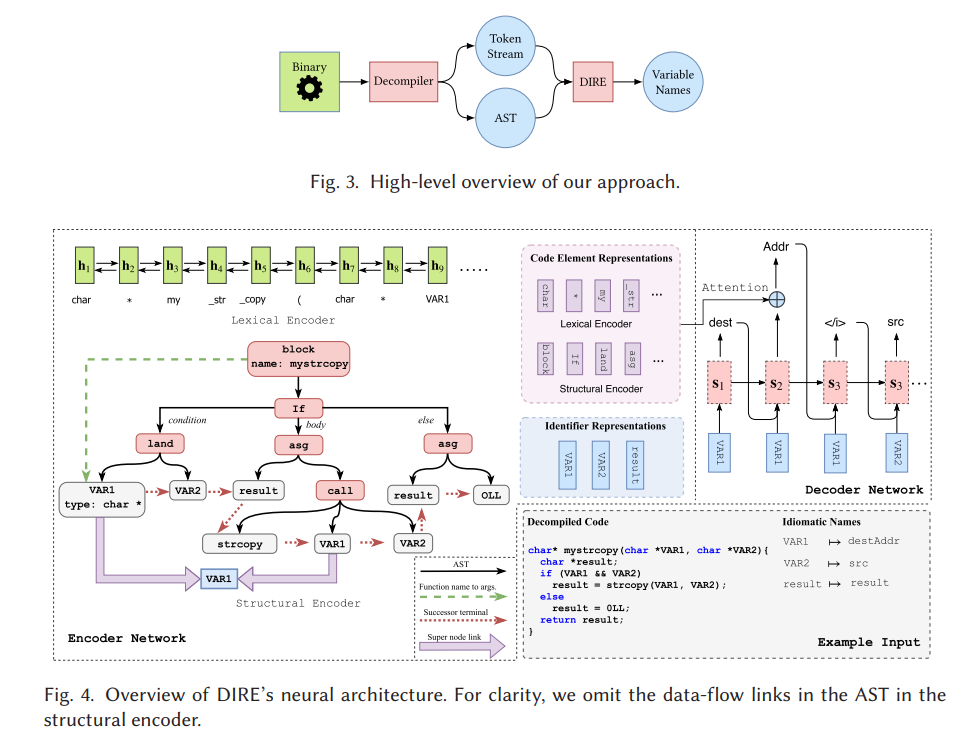
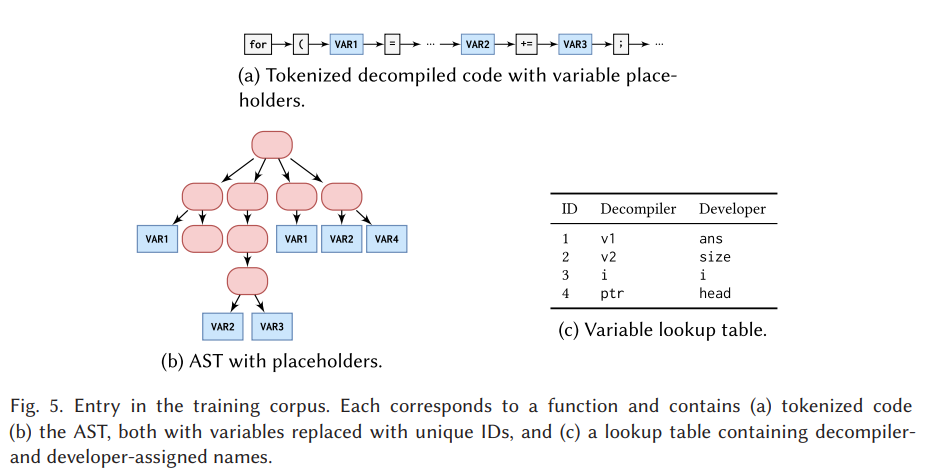
5 Data Preparation
6 Effectiveness
DEBIN:程序中推断的结构和变量的类型因为编译过程发生变化后DEBIN生成的信息不显示返回值。
该⽅法不适⽤于新发布的 Ghidra 反编译器 [12]。主要原因之⼀是 Hex-Rays 和 Ghidra 利⽤调试符号来命名变量的⽅式。 Hex-Rays 以⾮常直接的⽅式使⽤调试符号,并且通常不会在其函数之外传播本地名称。
然⽽,Ghidra 会。例如,如果将未命名的变量作为参数传递给参数具有名称的函数,则在某些情况下 Ghidra 会重命名该变量以匹配参数的名称。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号