Proj. CAR Paper Reading: DOBF: A Deobfuscation Pre-Training Objective for Programming Languages
Abstract
本文
工具: DOBF
任务:pretraining objective to recover the original version of obfuscated source code
方法:利用编程语言的结构信息
实验:
效果:
- 在多个下游任务上显著好过已有成果
- unsupervised code translation: +12.2%
- natural language code search: +5.3%
- 能够deobfuscate fully obfuscated source files,并且能够建议有描述力的variable names(descriptive variable names)
1. Intro
P1: 模型预训练被广泛使用
P2:
- mask, MLM objective。本文认为提到的方法很多都是denoising auto-encoding tasks + 不同的添加噪音方法
- BERT本身是为了自然语言设计的,本文认为对具有语法结构的source code是suboptimal。并且提出了a new objective based on deobfuscation of identifier names
P3: Code obfuscation基本介绍,可能丢掉调试信息的其他情况,比如编译
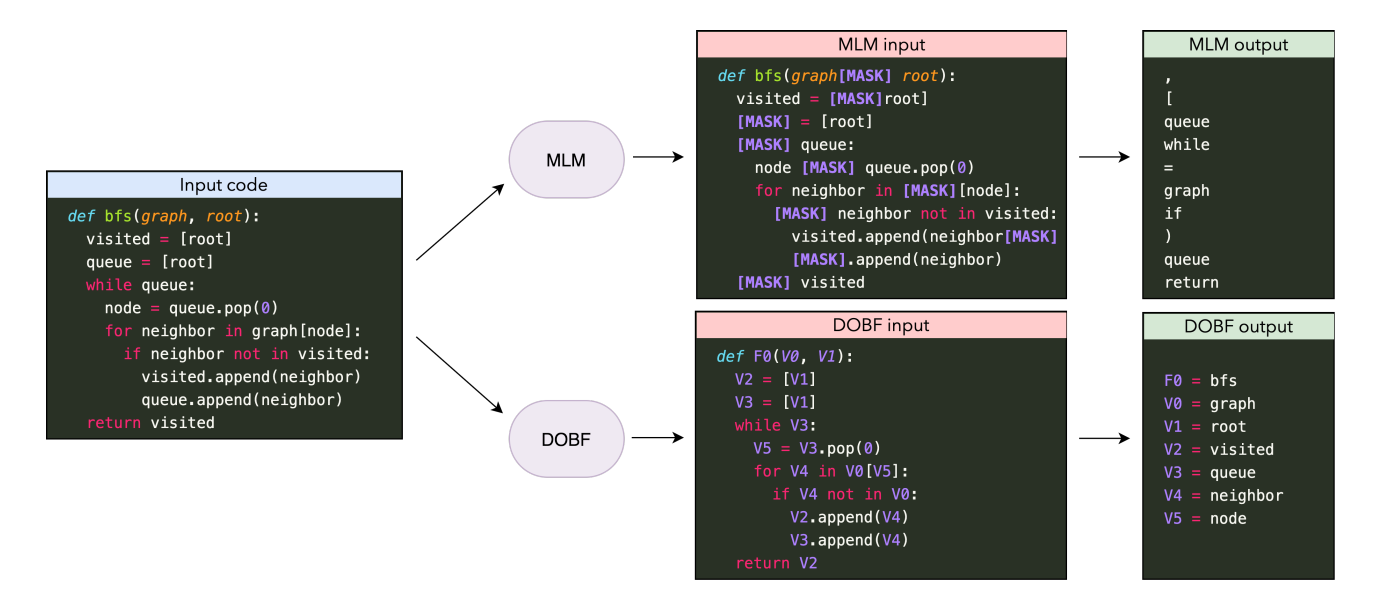
P4: 例子,猜测图1实现了⼴度优先搜索算法。
P5: 本文方法:seq2seq, predict the content of randomly masked tokens
难点:需要理解程序作用
MLM方法弱点:
- language syntax相关的mask能够提供的训练效果很少
- 本文方法:只考虑函数、变量名
- In practice, MLM also masks out variable names, but if a given variable appears multiple times in a function, it will be easy for the model to simply copy its name from one of the other occurrences.
本文方法: 使用VAR_i这个特殊token来替换(提问)input中的Variable names
![]()
5 Results
5.1 Deobfuscation
Training with pobf = 0.5 is a more difficult task that requires the model to learn and understand more about code semantics
5.2 Downstream tasks
objectives such as MLM and DAE that provide unstructured noise are complementary to DOBF.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号