Proj.CMI Paper Reading: SoK: Sanitizing for Security
1. Intro
memory corruption exploits
- 能绕过Address Space Layout Randomization(ASLR,地址空间布局随机化)和Data Execution Prevention(DEP, 数据执行保护)
- Code reuse attacks:
- corrupt control data + hijack the control flow,破坏函数数据后劫持程序控制流,例如破坏函数指针或者返回地址
- 例如: Return-Oriented Programming(ROP, 返回导向编程)
- Data-Oriented Programming(DOP, 面向数据编程):利用legal control-flow paths上面的指令破坏non-control data
The future direction of sanitizers:
- 现有工具未能捕获的bugs
- improve the compatibility with real-world programs,兼容真实程序
- 高效
2. Exploit mitigations vs. sanitizers
P1. 现有的exploit mitigations和sanitizers的区别
- Exploit Mitigations are to mitigate attacks in the release version of the software. Mitigations can only use a very limited resource, must tolerate benign errors, and cannot accept false alerts. The violation not usually triggered at the locations of bugs leads to termination.
- e.g:
- Control-Flow Integrity, CFI
- Data-Flow Integrity, DFI
- Write Integrity Testing, WIT
- e.g:
- Sanitizers are to find potential vulnerabilities in the pre-release version of the software. Sanitizers can use a relatively higher resource and usually do not tolerate benign errors and can tolerate some false alerts. The violation usually triggered at the locations of bugs does not always lead to termination.
- e.g:
- Bound-checking tools
- sanitizers aim to detect these bugs precisely since their exploitability is unknown.
- e.g:
Q: 关于分类
Some tools selectively apply sanitization techniques, possibly combined with exploit mitigation techniques. Code-Pointer Integrity (CPI), for example, only performs bounds checks (a sanitization technique used in many sanitizers) when the program directly or indirectly accesses sensitive code pointers [14]. We therefore consider CPI an exploit mitigation rather than a sanitizer because CPI only detects a fraction of all bugs that could be detected using bounds checks
不理解为何CPI不是sanitizer
3. Low-level vulnerabilities
A. Memory Safety Violations
原因:A program is memory safe if pointers in the program only access their intended referents
where intended referent
- Position: 指针必须要在其base address派生的地址空间中
- Lifetime:
- heap-allocated: 在allocation和deallocation中
- stack-allocated: 在function call和return之间
- thread-local: 线程创建到析构中
- global: indefinitely
- Spatial Safety Violations空间安全违规:Accessing memory that is not (entirely) within the bounds of the intended referent of a pointer。例如,buffer overflow缓冲区溢出,示例是intra-object overflow.
Example 1:
struct A { char name[7]; bool isAdmin; };
struct A a; char buf[8];
memcpy(/* dst */ a.name, /* src */ buf, sizeof(buf));
- Temporal Safety Violations时间安全违规:Accessing a referent that is no longer valid. 例如use-after-free(Accessing an object through a dangling pointer), 细分还可以有use-after-scope, use-after-return. 可以用来劫持控制流。
B. Use of Uninitialized Variables
原因:对于未初始化的变量,若一对变量都是unsigned narrow char type,那么C++14是允许拷贝的,进而造成数据泄露。(大多数时间这些未初始化的变量内容还是之前被分配的可能包含敏感信息的)
考虑到未初始化变量的值不确定,使用这些未初始化变量会造成未定义行为。
C. Pointer Type Errors
原因:unsafe cast
对于C,C允许指针类型的全部转换,还允许指针类型同整数类型之间的转换。
对于C++,reinterpret_cast不会设置任何限制,static_cast禁止指针到整数之间的转换,允许void*与各类指针的转换,且允许downcasting:即基类到派生类的转换。dynamic_cast则会执行动态检查(runtime type checks),如果动态检查失败则会返回null指针。
Bad casting(type confusion): a downcast pointer has neither runtime type of its referent, nor one of the referent's ancestor types.
Example 4: Bad-casting vulnerability leading to a type- and memory-unsafe memory access
class Base { virtual void func(); };
class Derived : public Base { public: int extra; };
Base b[2];
Derived *d = static_cast<Derived *>(&b[0]); // Bad-casting
d->extra = ...; // Type-unsafe, out-of-bounds access, which
// overwrites the vtable pointer of b[1]
- class/struct Type errors可以是在cast类的时候导致out-of-bounds,数据泄露等问题
- function pointer cast error: 也可以是由于函数指针错误cast导致的。
- union cast error
对于function pointer types casting erros: 由于C语言不对不兼容的函数指针类型之间的转换设置限制,这可能导致错误解读参数类型
对于union casting error:由于C语言允许对union结构做type punning, 如果程序并未正确读取union的member object,又去是存进去的member object小于读取的member object时,会错误读取,而且会读取unspecified values.
D. Variadic Function Misuse
原因:在使用c/c++的可变参数时,很难静态验证va_arg是否访问有效的参数,或者cast是否正确。这会导致type errors, spatial memory safety violations, uses of uninitialized values.
E. Other Vulnerabilities
原因:溢出错误,尤其是这些值被用于内存分配或者指针算数运算时。例如,当攻击者控制的整数与buffer size或者array index的计算有关的时候。例如如果令其overflow,就能得到一个比预料中更小的buffer size,从而使程序崩溃。
未定义行为-有符号整数溢出和回绕(wrap-around)-无符号整数溢出都会带来潜在问题。
在执行compiler optimization时,undefined behavior更会带来很多安全隐患。通常来说编译器在优化时会假设一些引起未定义行为的条件不会被触发,并根据这一点对程序进行重写和优化。产生的程序可能会诱发本不存在的undefined behavior或者是的无害的undefined behavior成为安全漏洞。注意程序优化并不需要静态分析可能存在、诱发的undefined behavior。例如,在CVE-2009-1897中,GCC没有检查一个Linux kernel driver是否为null,这导致priviledge escalation。这些aggressive optimizations又被称为time bombs。
Example 6: Simplified Version of CVE-2017-5029: a signed integer overflow vulnerability that can lead to a spatial memory safety violation
// newsize can overflow depending on len
int newsize = oldsize + len + 100;
newsize *= 2;
// The new buffer may be smaller than len
buf = xmlRealloc(buf, newsize);
memcpy(buf + oldsize, string, len); // Out-of-bounds access
Example 7: Simplified version of CVE-2009-1897; dereferencing a pointer lets the compiler safely assume that the pointer is non-null
struct sock *sk = tun->sk; // Compiler assumes tun is not
// a null pointer
if (!tun) // Check is optimized out
return POLLERR;
IV. Bug Finding Tech
A. Memory Safety Violations
目标: 不指向应使用的referent或者指向不再可用invalid referent的pointer dereferences
Identity-based Access Checkers
目标:detect memory accesses do not target to intended referent
方法:一般会有一个metadata store,内含每个allocated memory object的metadata,如bounds或者allocation status。当使用一个新的指针的时候,就去查询metadata store.
优点:更精确,能同时检查invalid memory regions和intended referent
缺点:1. 更高的运行时时间开销,2. 必须要插桩,3. 误报率更高
例如:
- per-object bounds tracking: 34, 37-43
- per-pointer bounds tracking: 44-55
- reuse-delay + per-object bounds tracking/per-pointer bounds tracking: 55
- lock-and-key checking + per-object bounds tracking/per-pointer bounds tracking: 46,47, 56
- dangling pointer tagging + per-object bounds tracking/per-pointer bounds tracking: 57-60
Red-zone Insertion
Red zone: 代表out-of-bounds memory。当试图访问red zone或者unallocated memory regions时会报错。
优点:运行时时间开销相对较低
缺点:
- 只能检查invalid memory regions,而且只能检查碰触到red zone的
- 会产生极大的memory overhead,并且会改变parent object的内存布局。外部代码可能不知道布局已被改变,因而产生问题。
例如:Purify在每个内存分配位置的前后引入red-zones;并使用一个shadow memory bitmap来存储内存中每个byte中的two bits(是否可读、可写),用以追踪被分配的地址空间。
Valgrind则是为每个bit都存储two bits,这使得Valgrind能够做bit级别(而非Purify byte)级别的,更细致的access error detection
Light-weight Bounds Checking
与red-zone类似,但是插入了一条fast path来加速查询。
fast path的运作原理:使用随机pattern来填充red-zones,每次访问内存时,先与随机pattern比对,如果恰好中了随机pattern,再去做第二级slow path check。接着第二级slow path check中了之后才触发警告。
Guard Pages
方法:在每个被分配的object前后插入inaccessible guard page。Out-of-bounds读写会引发page fault。借助paging hardware, access checkers允许检查在无需插桩load\store指令的情况下进行。但是,这些额外的guard pages的确会带来非常大的内存开销。在PageHeap中,Microsoft用guard memory objects而非一整页guard page缓解过大的内存开销问题。
PageHeap
开发商:Microsoft
PageHeap使用a fill pattern(?)来填充这些guard blocks,并验证这些guard blocks是否在memory object free了之后是否依然还在
缺点:只能检测out-of-bounds write,而且在对应的object被释放之前都无法检查到问题。
Per-pointer Bounds Tracking
方法:每次创建指针,例如调用malloc或者取object地址的操作时,都存下这个指针的base address和size of the referent。每次通过加减计算指针或者通过赋值得到新指针就传播这个metadata。每次dereference指针则检查是否在对应的bounds中。
优点:能提供完整的spatial memory violation detection,包括检查intra-object overflow。
缺点:
- 兼容性不高。未插桩的库不能正确传递或者更新bounds信息
- 需要传递指针信息,这导致运行时时间开销非常高
例如:
SoftBound, Intel Pointer Checker: 允许intra-object overflow detection,每次派生指向subobject的指针的时候,都调整metadata, narrow the pointer bounds。
CCured: 识别安全指针,不需要做bound checking和metadata propagation。
Per-object Bounds Tracking
方法:为每个memory object存储metadata。
优点:能够支持几乎全部spatial safety vulnerability detection。
缺点:
- BBC和LFP都为了运行时性能牺牲了精度(round up allocation sizes)
- 仍然无法做intra-object overflows检测
- 对于外部代码来说,常常不兼容。比如将指针指向OOB object,或者在指针上做标记(BBC),这都使得外部代码无法使用这些OOB pointers。
J&K(Jones and Kelly)方法
方法:为每个memory object存储metadata。对于收集传播metadata,只需要拦截(hijack, intercept)内存的分配和收回。对于检测bugs,只需检查指针的算数运算。查询则是通过range-based lookup(基于范围的查找)查找某个指针对应的intended referent。对于OOB(out-of-bounds)的查询来说,无法从metadata中查找到对应的object。此时,指针会被变为无效-invalidate。之后任何对该无效指针的解引用都会引发报错。
优点:能够解决一些兼容性问题。无需插桩pointer assignment和pointer creation相关操作,只需要拦截(hijack, intercept)内存的分配和收回,甚至可以不用插桩。
缺点:目前许多程序会使用OOB指针来做正常的工作,J&K方法是不适用的。
CRED
CRED: 增补了J&K方法,将合法的OOB pointers与OOB objects进行关联。OOB objects中会存储original referent。
Baggy Bounds Checking
方法:
- Q: 记录OOB pointer和其referent的距离到the pointer's most significant bits。由于将the most significant bits进行标记会使得指针本身失效,那么再去解引用被标记的指针就会引发错误。
- 为了节约额外的内存开销,BBC使用二的对数来记录object对应的allocation size,使得1byte的metadata就能够存住这些bounds.
优点:无需分配CRED的OOB objects
Low-fat pointer(LFP)
方法:
- Q: 基于BBC,但是让allocation size configurable。将heap分割开,每个subheap大小一致且仅仅支持一种allocation size。每个指针的allocation size就与其所在的heap支持的allocation size相同。而基地址则可以通过向下舍入到allocation size来计算。(The base address of the pointer's referent can be calculated by rounding it down to the allocation size)
- LFP不像BBC那样修改指针本身,而是将指针作为函数输入时,无论是显式作为参数,还是隐式从内存加载,都重新计算referent。
缺点:
- memory overhead更大
- LFP假设所有通过函数参数传递的指针都是within bounds,该假设在有潜在bugs时通常并不成立。
Reuse Delay
背景:
现有access checking机制能够检测dangling pointer dereferences,但是如果程序重新用这些memory\identity(重新分配),那么就检测不到这些实际上是dangling pointer dereference。(没有给被释放的指针分配新内存object,但是指针原本对应的内存被分配给了其他合法object)
现有机制举例:
- location-based access checkers能够将最近deallocated object变为red-zones或者guard pages
- Identity-based checkers也能够让这些deallocated object变成invalid状态来探测这些dangling pointer dereference
当前方法-Reuse Delay: delaying the reuse of memory regions until they have "aged"
权衡:longer reuse delays lead to higher memory overhead,但是成功的机率也会更高
D&A Method
方法:使用静态方法来确认何时适合deallocated memory能够重用(reuse),使用Automatic Pool Allocation的技术来将heap划分到pool中。
步骤:
- 为每个memory object分配一个virtual memory page
- 允许多个virtual memory page指向同一个physical page
- 程序释放一个memory object,就将其所对应的virtual page转化为physical page
- 通过Automatic Pool Allocation来将heap划分到pool中,如果一个pool不可访问,那么整个池中的所有virual pages应该都被回收reclaimed
####### Dang et al.
基于:D&A方法
优点:
- 不使用pool allocation,因此可以被用在source-less programs上
- 无需保存guard page的meta data,内存占用更小
步骤:
- 为每个memory object分配一个virtual memory page
- 允许多个virtual memory page指向同一个physical page
- 程序释放一个memory object,就取消映射unmap这个virtual page,起到和guard page相同的作用,但是不需要保存metadata。
- Q: 为了防止重用unmapped virtual pages,将新的virtual page映射到有high water mark的physical page上。(pages at the high water mark即具最高的已经被使用的虚拟地址)
- Q: 这是考虑到64-bit地址空间中reuse更不可能发生
Lock-and-key
定义:
key: unique allocation identifiers
lock: lock location
优点:便于与per-pointer bounds连用,探查spatial violations
缺点:
- 无法与uninstrumented code连用
- run-time overhead
方法:
- 为每个allocated memory object赋予一个unique key,并将这个key存储在一个lock location中
- 为每个pointer将lock location和对应的key作为metadata存储起来。
- 当对应的memory object deallocated时,从lock location撤销(revoke)key。
- 当目标程序解引用一个指针时,若当前key与lock location中存储的key不同,则报错temporal memory safety
Dangling Pointer Tagging
背景:最直接的Tag dangling pointer的方式:free后将所有相关指针设置为null。接下来再次使用这个dangling pointer就会引发警告
[57]-[60]: 不仅仅对传给free的指针tag,也对这个指针的其他拷贝tag。
####### Undangle
方法:使用taint tracking跟踪指针的创建。维护object-to-pointer map。当memory object被释放时,Undangle查询这个集合以快速得到全部所有dangling pointers。
注意,Undangle允许配置time window,在time window中的temporary dangling pointer被认为是潜在不安全的,但是被允许且不会报告。(并不认为绝对不安全)例如,在嵌套对象的释放期间出现的transient dangling pointer。
####### DangNull, FreeSentry, DangSan
方法:不是在编译时创建污点跟踪和插桩,而是runtime registration,在运行中注册指针。每当程序释放内存对象时,工具都会查找所有指向被释放对象的指针,并使其无效。这样使得之后对这些dangling pointer的引用都会引发hardware trap。
缺点:
- 需要源代码支持。源代码中含有类型信息,用以确定哪些操作存储了新指针
- 如果程序在拷贝指针时使用了type-unsafe的风格,例如,把指针转换为整数,就难以维持metadata有效性
- 只能够探测内存中的指针是否dangling,不能查看寄存器中的指针。
优点:性能和内存开销较小
B. Use of Uninitialized Variables
Uninitialized Memory Read Detection
方法1: 将uninitialized newly allocated object对应的全部内存区域设置为uninitialized并存在metadata store中
与redzone不同,写入是允许的,只是不允许读,而且会将这些内存区域移除标志。
注意C++14允许传递未初始化的值(例如,允许拷贝部分初始化的struct),所以可能造成许多误报。allows uninitialized values to propagate through the program as long as they are not used.
Uninitialized Value Use Detection
Memcheck
为了减少Memory read detection的误报,Memcheck仅仅汇报以下几种情况的错误
- 对(部分)未初始化的指针的解引用
- Q: branching on a (partially) undefined value
- 将未定义的值传给system calls
- 将未初始化的值传给寄存器
优点:近似模拟了C++14的语义,更准确,召回率也更高
方法:
- 为每个部分初始化的字节都添加1byte shadow state. Q: 这允许Memcheck以bit精度跟踪程序内存
MSan
工作在IR上而非Memcheck的binary上,因此效果更好。准确率、召回率更高,性能损耗比Memcheck低一个数量级
C. Pointer Type Errors
Pointer Casting Monitor
任务:检测C++ static_cast的illegal downcasts
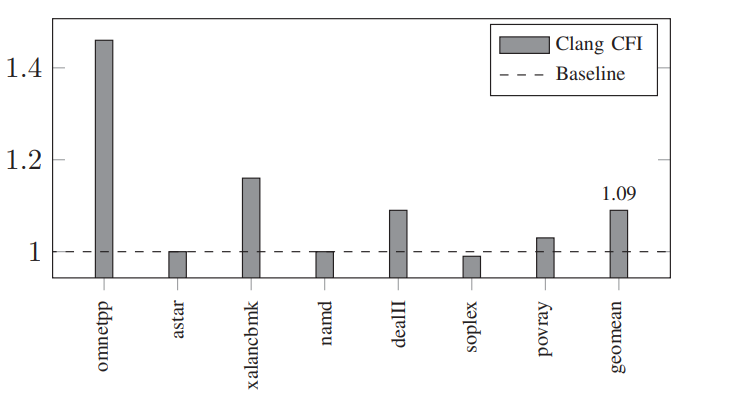
UBSan, Clang CFI
方法:通过将static_cast提供的类型与run-time type information(RTTI)中的信息进行对比
优点:相当于将static_cast转化为dynamic_cast
缺点:对没有RTTI的工具并不适用(有些编译器不支持打开这个开关)
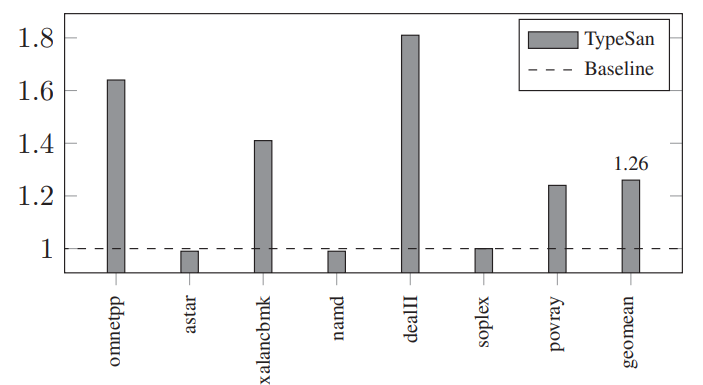
CaVer, TypeSAN
方法:为所有类型和objects维护metadata。
Q: they can extend the type-checking coverage to non-polymorphic types.
polymorphic type指具有Virtural function的基类。有时设计错误可能会导致基类并没有虚函数,这可能指non-polymorphic type。
步骤:
- 在编译时,为每个class建立一个metadata table,其中包含给定指针类型可以做cast的全部类型(all the valid type casts),包含全部的继承关系和组合关系。
- 监控memory allocation,并将某个object在分配时的类型记录在metadata store中。
- 当进行downcasting时,从表中查询能否进行转换。
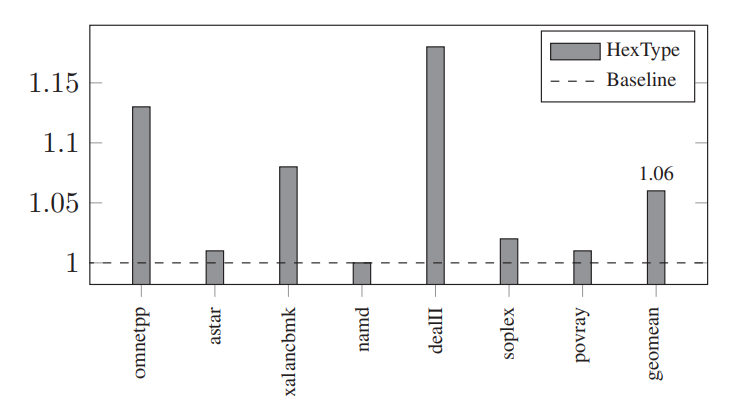
HexType
方法:比起TypeSAN提供了更准确地运行时类型追踪。HexType还将dynamic_cast改为自己优化后的版本。
Pointer Use Monitor
背景:以下都是编译和运行时类型检查无法检测,因而造成潜在麻烦的cast方式 1. C-style casts 2. reinterpret_cast 3. unions
Loginov et al.
方法:监控所有load和store操作,以此维护所有memory location的runtime type tags信息,并进行验证。Tag中包含这个memory location最后一次被写入时的Scalar type信息。每当读取时,都检查读取时的type是否匹配type tag。
TySan(LLVM Type Sanitizer)
方法:同Loginov相似,但是不要求类型绝对匹配,只需要兼容(C/C++标准中的aliasing rule)。
TySan需要编译过程输出的type aliasing relationship。
EffectiveSan
任务:type checks + bounds check。
方法:使用object type tag和type layout metadata。
步骤:
- 为每个allocation site进行插桩,来为每个allocated object 标注上静态确定的类型。(tag each allocated object with its statically-determined type)
- 对于stack\global variables,对C++ new operator申明的objects,使用声明时的variable types; 对于malloc分配到的object,使用该object的第一次作为左值使用时的类型
- 编译时,会生成包括type layout的metadata,metadata还包含所有某个类嵌套的所有子objects的内存布局
- 每次dereference都做bound checking和type checking。由于存储了子objects的内存布局,因此也可以检测intra-object overflow
Detect indirect function calls
任务:检测在调用函数时传递带着不兼容的参数类型的指针
Clang CFI: 方法:Function-signature-based forward edge control flow integrity
优点:Q:无需runtime-tag
D. Variadic Function Misuse
Dangerous Format String Detection
主要是监管printf的formal string参数,例如,禁止%n(能让用户对caller-specied position写信息)
Argument Mismatch Detection
FormatGuard
方法:只允许printf读取caller发送的参数(argument counting)
步骤:
- hijack至一个protected printf
- 这个自定义的printf实现会记录va_arg读取的个数。如果个数超过了caller提供的个数,就会报警
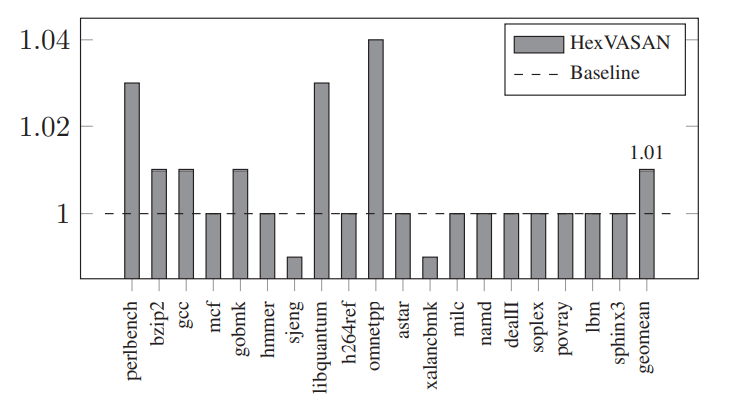
HexVASAN
方法:对所有变参函数进行Argument counting + type checking
步骤:
- 记录参数的数量和类型
- 插桩va_start和va_copy、va_arg类检查
E. Other Vulnerabilities
Stateless Monitoring
UBSan
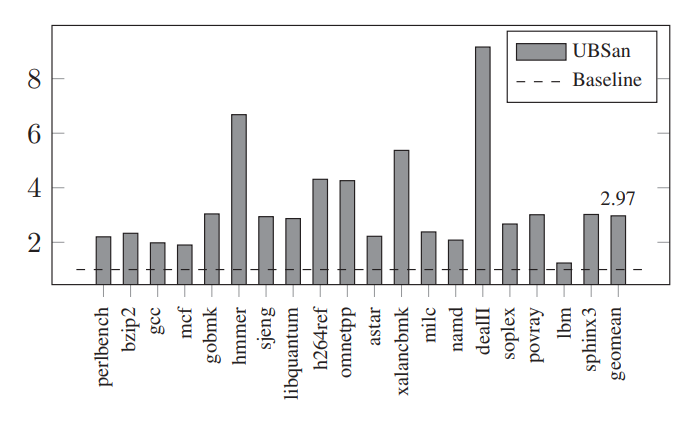
Task: 检测undefined behavior,例如有符号整数overflow, 除以零, invalid bitwise shift operation, floating pointer overflows by casting, misaligned pointers, overflows a pointer, dereference a null pointer, value-returning function without returning a value. 有时也检测那些在c++标准中有详细描述,但是很容易引发bug的行为如unsigned integer overflow
特点:大部分检测是无需保存状态的,不会相互干扰
V. Program instrumentation
keyword:
inlined reference monitors(IRMs): 被插桩的代码,用于监控和调解(mediate)所有可能导致bug的位置。包括memory loads\stores, stack from allocation\deallocation, calls to memory allocation functions, system calls。IRMs可以通过编译器、linker、专用instrumentation framework来被插入程序
A. Language-Level instrumentation
层次:source-code或者AST(abstract syntax tree)
优点:
- 保留了完整的类型信息和语言特性,适用于pointer type errors相关检查
- 保留了较为完整的语义,sanitizer可以察觉一些程序员的意图,例如undefined behavior
缺点:
- 需要源码
- 一般需要局限于特定语言,因此代码需要由特定语言编写
- 对于带有closed-source library或者inline assembly code的程序常不适用
B. IR-Level Instrumentation
层次:IR
优点:
- generic,能支持多种源代码
- 只完成了frontend,backend的静态分析和优化仍可利用来优化调节IMR的性能
缺点:
- 需要源码,对于带有closed-source library或者inline assembly code的程序常不适用
- 例外:ASan为inline x86汇编提供了插桩,但这种类型的支持只对几个architecture有效
C. Binary Instrumentation
keyword:
- Dynamic binary translation framework: 允许在运行时动态插桩。会在程序执行时动态读源码、插桩、翻译为机器码。也会提供多个hooks来影响执行。
- Static Binary Instrumentation: 对binary静态插桩
层次:Binary
优点:
- support closed-source program
- support 3rd party code
- support dynamically generated code
缺点
- 运行时时间开销更大
- 没有type信息,无法做type检查。没有stack frame、global data section layouts,因此也无法做完整的spatial memory safety sanitizer checks
D. Library interposition
keyword: library interposer: a shared library that when preloaded into a program, can intercept, monitor, and manipulate all inter-library function calls in the program。一个用来拦截、监视和操作所有库间函数调用的共享库
层次:库函数调用
优点:适用于binary,粗粒度。开销极少
缺点:
- 无法拦截库内函数对另一个库内函数的调用
- highly platform and target specific。例如对 malloc 的调用的清理程序不适用于具有自己的内存分配器的程序
VI. MetaData Management
metadata存储机制(storage scheme)将决定两种sanitizers能否公用。明显,当两个sanitizers都要修改(例如tag)指针、object representation时,共用是难以实现的。
A. Object Metadata
例如object size, type, state, allocation identifier等。
Embedded Metadata
方法:直接在分配空间时增加object的allocation size,然后在这些附加的空间append或者prepend metadata。这一般通过修改memory allocators完成。e.g., 在实际的buffer前面添加一小块区域用来存储buffer length。
使用这一方法的工具:
- ASan: 存储allocation context
- Oscar: 存储canonical address
Directed-mapped Shadow
方法:将nbytes大小的blocks映射到shadow memory的m bytes metadata上。
一般映射地址: metadata_addr = shadow_base + m * (block_addr / n)
优点:
- 简单易用
- 时间上较为高效,只需要一个memory read指令。
缺点:
- worsen memory fragmentation(and spatial locality)
- 内存开销大
使用这一方法的工具:
- ASan: n=8
Multi-level Shadow
方法:引入directory tables,即additional layers of indirection 以目录表的方式引入额外的间接层?
Step:
- directory tables存储指向metadata tables或者其他directory tables的指针。整体组织方式模仿page tables的组织方式。
- metadata table以类似directed-mapped shadow scheme的机制直接映射一部分memory
- 懒加载metaData table。
目的:减少内存开销
优点:
- 节约内存,在内存空间有限的系统,例如32-bit system上,更为有利(因为直接使用shadow memory会直接耗尽内存)
- Q:可以节约allocation time performance
缺点:
- 时间开销大-需要多次memory access,each level of directory tables needs one access(Q:还是合起来只需要1次?)因为这个特点,更适合不经常查询的那种metadata,例如,TypeSan使用2层variable-compression ratio机制(Q:这里说type data是constant-sized)。
per-object metadata
与shadow memory不同,可以设置variable-compression ratio multi-level shadow mapping schema,将变长objects映射为constant sized metadata(这里应该是说object变长,而非metadata变长)
Custom Data Structure
- splay tree: J&K, CRED, D&A
- hash table: UBSan, CaVer
- red-black tree(thread-safe): DangNull
- per-thread metadata: CaVer
B. Pointer Metadata
Fat Pointers
Fat pointers are structures that contain the original pointer value, as well as metadata associated with the original pointer.
e.g:
struct fat_pointer {
void* value; // Original pointer value
void* base; // Base address of the intended referent
size_t size; // Size of the referent
};
优势:
- 不会造成过大的cache pressure
- 能存储任意大小的metadata
缺点:
- 需要插桩
- 改变了calling conventions,可能无法兼容需要使用指针的外部代码。此外,不能与未插桩的代码连用。
Tagged Pointers
Tagged Pointer: A tagged pointer embeds metadata in the pointer itself, without changing its size.
方法:一般将
优点:
- 不会造成cache pressure
- 兼容性更好,能够兼容standard compatibility
缺点:
- 无法容纳很多metadata。其容纳信息的能力根据平台有所不同。例如,对AMD64平台,一般只使用低位256TB的virtual address space,因此,高位16位(一般约定为0)为可以用来存储per-pointer metadata。
- 除了low-fat pointer之外,不能直接对指针解引用,必须要unmask操作或者在metadata table中查找原指针。
e.g:
- Baggy Bounds Checking: 用高位16位存储OOB pointer到intended referent之间的距离
- SGXBounds: 针对64位机器上运行的32位enclaves,因此高32位都可以用来存储referent。
- CUP: 使用整个指针来存储指向metadata table的指针,在metadata table中有真正的指针值以供访问。
Disjoint Metadata
定义: 存在与pointer本体无关的某个数据结构中
优点:
- 能存储任意大小的metadata
缺点:
- 更高的内存开销
- Q:当拷贝指针时,比如memcpy,需要显式传播metadata、更新metadata store中这个structure的全部指针相关信息。
e.g:
- two-level 字典树:CETS存储allocation identifier和lock address of this referent
- two-level structure: Intel Pointer Checker, Intel MPX
C. Static Metadata
常常是编译阶段被舍弃的信息。在运行时被插桩的caller会将这些信息推入custom stack。
e.g:
- bad-casting sanitizer需要记住type hierarchy table
- HexVASAN: 变参函数需要记录每个call site的参数数量和类型
VII. Driving a Sanitizer
与其他测试的关系
- dynamic analysis tools可以由unit test, integration test suites, automated test case generators, alpha\beta testers等测试启动。
- 在与beta testing结合时,
- 优点:可以获取testing load
- 缺点:beta testing一般只关注主要的使用场景;sanitizer可能会带来过大的性能开销,使得程序完全无法运行。
- PartiSan, Lettner等 partitioned sanitization
- 符号执行可以将解答结果放入sanitized program; fuzzing可以执行sanitizer program
VIII. Analysis
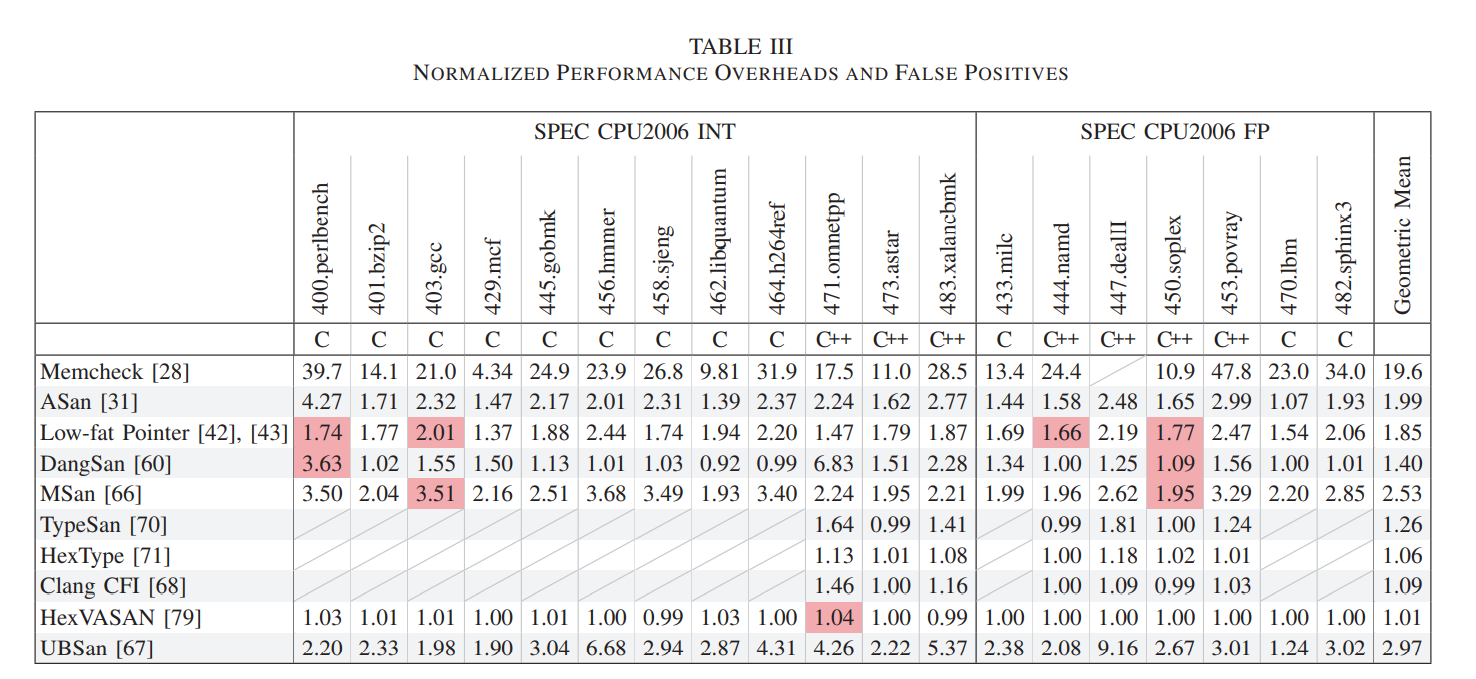
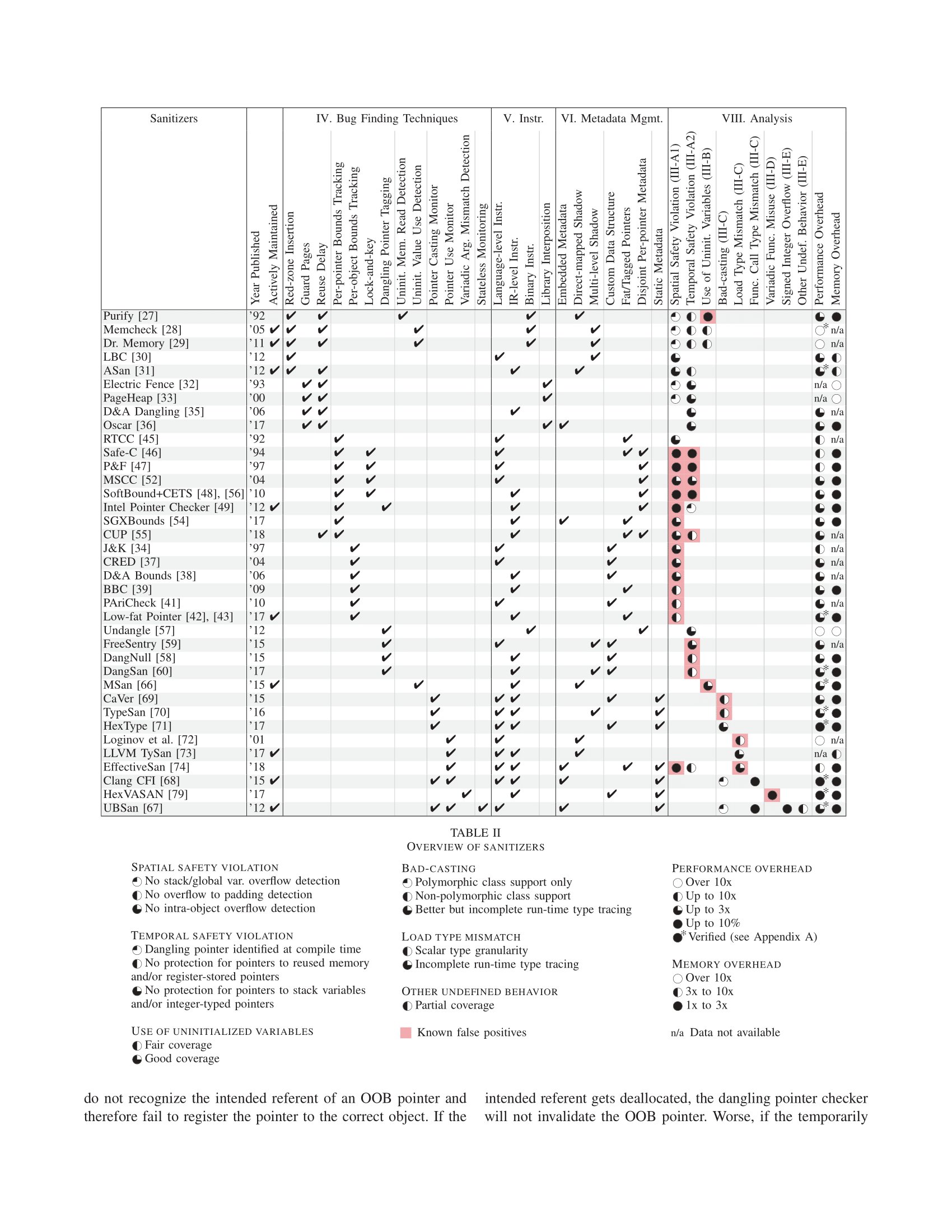
本章节比较了所有发表在会议或者有活跃的维护的,能够标识出错误位置并且结合Debugger一起使用的动态分析工具(一些是exploit mitigation)
Intel Inspector, ParaSoft Insure++, Micro Focus DevPartner, UNICOM Global PurifyPlus等由于缺少公开信息不予收入。
A. FalsePositive
本文认为对于sanitizer来说,准确率比召回率更为重要。
此外,本文认为许多假阳性的原因是因为sanitizer按照过于严格的标准,通常是language standard,来筛选bug。实际上的标准de facto standard,可能与language standard存在一定出入。
e.g:
- J&K方法不允许创建OOB(out-of-bounds)指针,但是实际上只要不解引用,只是创建在正常代码中也是可行的行为。因此CRED就取消了这个限制,允许创建OOB指针。
- dangling pointer checkers: 没有正确识别出OOB pointer的intended referent:1. 因此在intended object被free之后,checker不会invalidate the OOB pointer(Q:造成假阴?)。2. 如果OOB Pointer被赋予恰好指错的object的位置,就会在指错的object被deallocated时被错误invalidate。(但是不是仍然是OOB么,仍然被允许创建但是不允许被解引用)
- Q: low-fat pointer-based bounds checkers + temporary OOB Pointer: 如果OOB指针被传给某个能使得OOB指针转为original in-bounds value得函数,而low-fat bounds checks在指针escapes from a function得时候就执行bounds check,就会引发误报
Pointers that temporarily go OOB can also cause problems in low-fat pointer-based bounds checkers [42], [43], which perform bounds checks whenever a pointer escapes from a function. If an OOB pointer is passed to a function that converts that pointer back to its original in-bounds value, the checker will have raised a false positive warning. - 程序读取未初始化的内存不应当被报警,除非这些未初始化的值被使用。(Q: 是指part-initialize么)The language allows uninitialized memory read as long as the uninitialized values are not used in the program.
- 在某些情况下,一些pointer type error checker可能没有正确识别类型从而导致误报。如果使用new来重新定义一个memory region的用处,这些checkers有的时候会没有及时更新或者没有更新metadata,最终,这些旧数据可能会导致误报。
- aliasing rule过于严格也可能造成误报。对于以下方法,当程序使用char *这种常用指针类型来传递数据时,就会出现误报。
- Loginov等要求被监控的数据只能用runtime-type对应的类型来访问
- HexVASAN要求参数类型与va_arg提供的完全相同
B. False Negative
本文认为False Negative未能被找出的原因通常是因为bug finding policy(oracle?)和实际实现机制的差别。(didn't cover the bugs that are supposed to be covered)
- Spatial Safety violation checkers
- red zone insertion or guard pages: 无法探测以下bugs
1. 不能探测超过red-zone insertion或者guard page的访问
2. 不能查询intra-object overflow - Tagged pointer: 由会把bounds近似为2的幂次,所以不能探测在bound内的
- per-object bounds: 1. 常常不能探测intra-object overflow,尤其是parent object中的first object,因为二者的起始地址都一样。
- Temporal safety violation checkers:
- delay memory reuse for a little period of time
- 使用pool allocation analysis(Q: 什么是pool allocation analysis)决定何时指针不可再访问。
- Note: pool allocation analysis只在编译时可行,因为需要type信息 - Guard page-baed temporal safety violation detectors: 不能处理use-after-scope和use-after-return,因为这些变量存储在stack frames中,而这些stack frames是共享的,无法用guard pages替换。
- dangling pointer tagging: 不能检测register中的pointer
- Uninitialized memory use detectors: 为了避免误报,实际上通常只考虑几种情况下的使用。例如,传递给系统调用,或者在branch condition中被使用。因此,其他情况中的错误使用可能会被漏报。
- Pointer type error detectors: 例如TySan。实际上是在近似语言标准中的type rules,而不是精确的。难以覆盖未知type。
- 一些sanitizers: 无法识别经过整数转换的或者memcpy转换的
- 使用disjoint per-pointer metadata的方法因此经常难以传递pointer bounds
- tag dangling pointers: 影响指针跟踪
C. Incomplete Instrumentation
- 静态插桩方法常常无法对动态代码做分析,改为动态插桩,又不能支持一些类型的sanitizer
- external libraries
- 在IR层次插桩无法对inline assembly插桩
造成结果
- false negative
- meiyouzugouxiaoxi
- 对修改了指针本身的sanitizer,比如tag, fat-pointer,会造成崩溃
D.Thread Safety
- 不能正常更新metadata
- 无法支持multi-thread
- 错报、误报
- 只能原子式执行,可能有锁,可能性能损失或者无法添加复杂的instrumentation
E. Performance overhead
性能开销可接受度
- real-world deployment: 约5%
- sanitizer: 3x
- 测试特殊程序,比如动态生成代码、或者黑盒测试:20x
- 与fuzzing一起用:越小越好
run-time overhead主要分为以下部分:
- checking
- 主要与checking frequency有关:memory checker开销最大,type cast checker次之
- 一些memory error detectors会提供selective instrumentation
- metadata storage and propagation: 最主要的花销
- 主要与metadata storage scheme有关
- embedded metadata、tagged pointer、fat pointers都更为有效,还能自动propagate
- 但是除了low-fat pointer无法兼容uninstrumented library和External code
- disjoint/shadow metadata会带来更大开销,但是更受欢迎
- embedded metadata、tagged pointer、fat pointers都更为有效,还能自动propagate
- run-time instrumentation cost
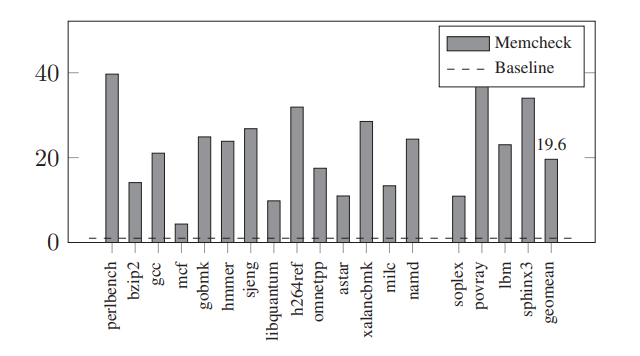
- 大部分sanitizer不需要,但是引入动态插桩的sanitizer就会带来很大开销,例如Valgrind's Memcheck在SPEC2000上会造成大概25.7倍的overhead
F. Memory Overhead
在32位平台尤其突出
e.g:
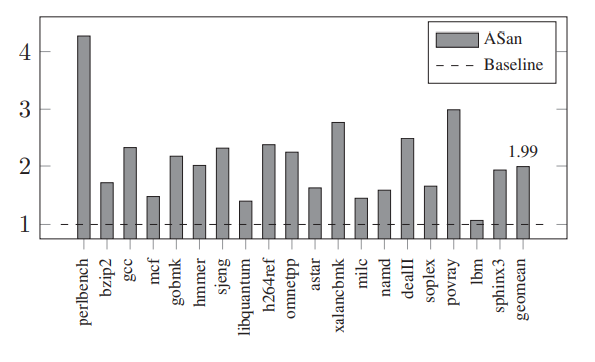
- ASan在SPEC2006 benchmark上会带来3.37倍内存开销
- Guard-page-based sanitizer,例如Electric Fence和PageHeap花费的内存更多
要求:
一般要求在3x以内
IX. Deployment
A. Methodology
在Github的top 100C和top 100 C++上,检查build\test scripts, github issues, commit histories。此外,还会检查sanitizer主页提到的项目, search trends
B. Findings
- ASan最受欢迎
- 对应的bugs最容易与exploit有关
- 兼容性很高
- 假阳性很低
- 能应用在Chromium这种大型项目上
- 但是缺点是会产生漏报
- 在LLVM和GCC中有集成;虽然DBT-based memory safety sanitizers如MemCheck和Dr.Memory也有类似长处,但是没有这么受欢迎
- 其他LLVM-sanitizer应用率比较低
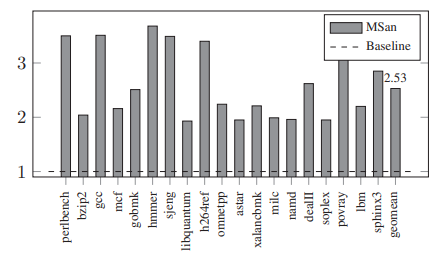
- MSan和UBSan也有应用,但是错报率太高;MSan必须要全部插桩,而UBSan必须要suppression list;在大项目上应用较难。
C. Deployment Direction
- 所有(本文选用的)sanitizer易用性都很高,操作容易,或者能够适应任何binary
- 误报最影响使用率,性能次之。
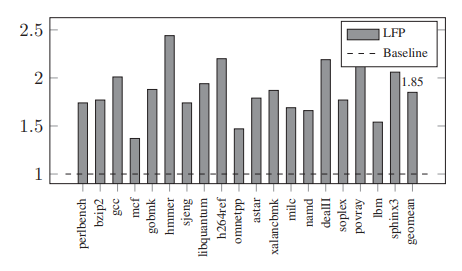
- 在SPEC上:ASan能在全部benchmarks上运行;Memcheck只在447.dealII上不能运行;SoftBound+CETS在许多benchmarks上都因为strictness或者compatibility不能使用;LFP也因为strictness(认为OOB指针不会从creating function中escape)在许多上面不能使用;DangSan有自己的patches
- Asan和Memcheck误报;UBSan和MSan维护麻烦,误报率高;其他类型的vulnerabilities常常缺乏合适的Sanitizer
X. Future Research and Development directions
A. Type Error Detection
使用pointer monitor能够找到因为type punning导致的错误类型解引用,但是带有这一功能的工具很少,而且误报率高,且常常带有严重的时间、空间开销。因此,更高精度、更好的type error detection会是方向
B. Improving Compatibility
- de facto language standard
- partially instrumented programs
C. Composing Sanitizers
同时检查不同bugs,减少运行时间
D. Hardware Support
Q: Hardware features can improve bug detection precision and alleviate certain compatibility issues. 时间可以理解?
- 增加速度:例如Intel MPX(memory protection extension)
- 增进兼容性和准确度:ARMv8的虚拟地址tagging允许tag最高8bit地址,因此可以被Hardware-assisted ASan用来传递指针metadata
E. Kernel and Bare-Metal Support
为了测试非user-space application,如kernel, drivers, hypervisors,需要做特殊改动
此外,kernel的许多特性是为了32位机,如IoT设备,设计的,这要求内存开销不能过大
XI. Conclusion
Appendix A