Proj. CRR Paper Reading: Adaptive Restarts for Stochastic Synthesis
Abstract
- 背景:
- 假设:
- 搜索经常会经历一系列plateus平台期
- 合成时间的分布经常是heavy-tailed(越在后期,进展越慢)
- 假设:
- 方法
- 提出了一种能加快合成速度的算法
- 效果
- 能加快一个数量级
- 实验:
- 从生产代码中提取了新benchmark
1. Intro
Program synthesis:给定一组(输入、输出)对,合成一个程序,为每个输入产生指定的输出
随机合成:对程序进行随机搜索,在每步中,设当前搜索状态从程序p出发,得到下一个状态p',p'比p的损失函数更小,更靠近目标输出。
本文:专注于随机合成的特征行为、出现这些行为的原因、如何利用这些观察结果来设计更高效的综合算法
随机过程可以是做一个马尔可夫过程,其转换概率可以被视为取决于测试用例、随机变化的分布(distribution of random changes)、cost functions, a parameter β 用以控制允许cost继续增长的概率。
定义:搜索的平台周期为以一个确定的代价(cost)为中心的随机分布。
本文使用一个简化的随机模型,这使得可视化成为可能。
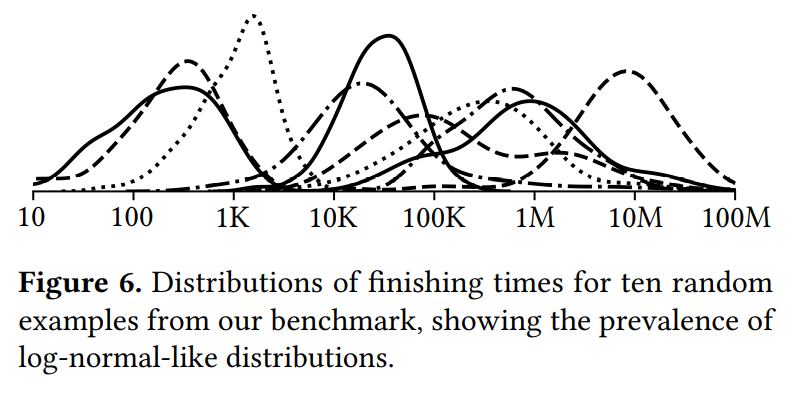
并发现Q:平台期的数量和连通性会导致搜索时间呈现不同的heavy-tail分布,e.g: gamma分布,log-normal分布。
Q: In a pure random walk, the cost function is ignored: all programs effectively have the same cost and the search time will be geometrically distributed. 为什么可以忽略cost?
处理heavy-tailed distribution的一种解决思路:如果搜索时间长于某个截止时间,则重新开始搜索。本文同样证明了当时间分布不是heavy-tailed,经典的重启算法实际上会损害性能。
本文改进了经典的重启策略,放宽黑盒假设并引入了一种更有效的adaptive restart algorithm(从针对Las-Vegas算法的Luby重启算法中获得灵感)。
实验细节:使用2个benchmarks:
- SyGUS Competition 2017
- 从Linux发行版中得到的程序碎片收集得到的benchmark
效果:
- adaptive restart比原始版本快1.7-10倍,比Luby快5.5倍
- 在50次尝试中成功合成了97%的benchmark problems
- 分析了为何剩下的3%没有被解决
本文贡献:
- 使用几何分布研究平台期,并且分析了当β低时,近似于heavy-tailed log-nromal distribution的搜索时间分布
- 使用linux发行版提出了新的superoptimization synthesis problems,组建了新benchmark
- 提出了新的合成算法
2. Related Work
程序合成
- 系统枚举程序直到找到具有所需功能的程序
- 基于SMT方法
- STOKE项目类似的方法
- ML
程序合成的应用
- STOKE
- Mimic project
- 查找编译器bugs
- 程序修复
2.1 以前的数据集
- 研究10和Morpheus:手动管理,规模较小,只有25-80个示例
- SyGus竞赛: 600 bit manipulation problems
2.2 Restart Strategies
应用
- Las Vegas算法
- SAT Solvers,但是会保存一些学习到的clauses等信息
3. Synthesis Algorithm
3.1 Program Representation

Programs are rooted, directed, acyclic(?) dataflow graphs, where nodes are instructions\constants\inputs, and edges are the usage relationships. 根节点是输出。
为了减少操作顺序过于重要带来的繁琐,本文定义:
- intermediate values和常量为64bit整数。
- 定义orq, addq为bitwise OR和integer addition。
- 定义每个instruction node为带有opcode的fixed arity(固定元数的)无副作用的确定性操作(a deterministic operation of fixed arity with no side effects)。
- 本文不允许dead code,所有节点都必须连接到根节点。
3.2 Stochastic Synthesis Algo
随机合成算法维护当前程序p,每个迭代步提出一个可能的新程序p',每一步有若干种可能的moves。在每个迭代步中,合成算法计算p'带来的新cost,并且如果cost降低或者cost增加的程度可以忽略不计(Q:与β有关?only increased by at most a small margin)则可以接受这一步。重复以上过程直到cost为0。
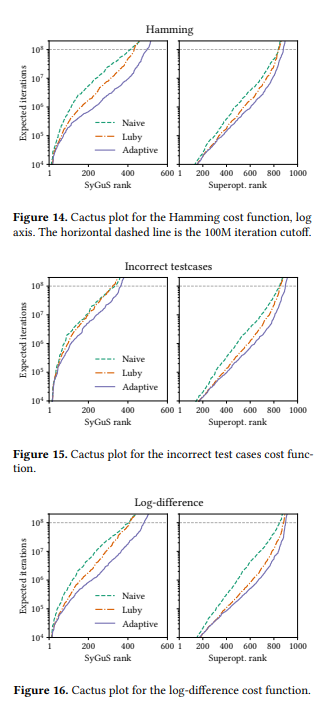
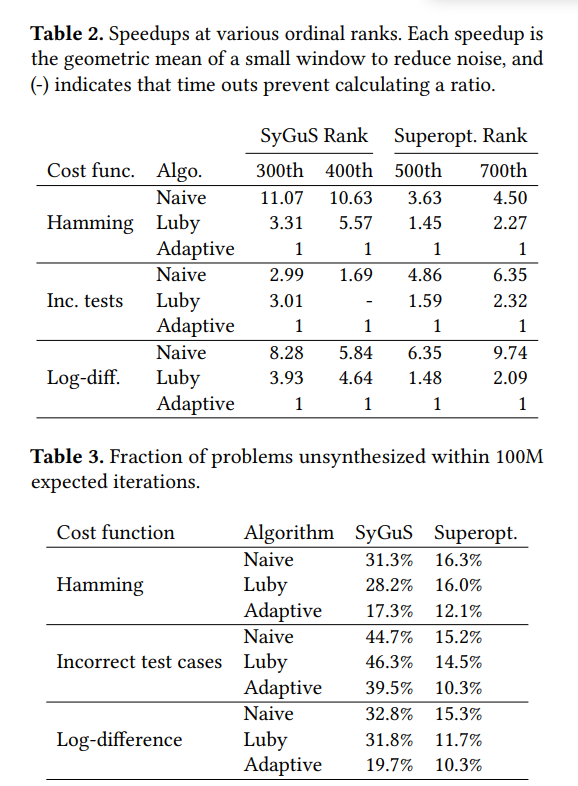
本文考虑以下的cost functions
- Hamming
- Incorrect test cases
- Log-difference: 1 + log2(|a - b|)
本文考虑以下的moves:
- Instruction: 随机选择一个参数或随机选择slot for the root node。对这个选择的参数,生成随机opcode,再随机使用常数或者使用已有的nodes(不造成环的)来填充Opcode所需参数
- Opcode:随机选择instruction node。生成随机opcode(同样元数的其他opnodes)。
- Operand:随机选择一个参数或者随机选择slot for the root node。随机使用常数或者使用已有的nodes(不造成环的)来填充Opcode所需参数。
选择每种move的概率均等。本文只允许程序有最多16个节点。
在实验中,搜索在单个CPU内核上实现了每秒339k迭代。本文选择迭代次数为衡量标准以免受硬件对处理速度带来的干扰。
当β=1时,若p'的cost只比p大了不到3bits,则以5%概率接受,若p'只大了不到6bits,则以0.25%概率接受
尽管本文的程序严格来说并不满足MCMC理论所提出的遍历性ergodicity和互惠性reciprocity要求,本文认为\(β \times In(random(0, 1))\)是指数分布。对不同benchmark进行归一化,使其成为在100个testcases上的对应概率。
即实际使用的$\beta ' = \frac{\beta \times # testcases}{100} $
4. Behavior of Stochastic Synthesis
首先简化随机合成模型,将opcodes简化为and, or, xor, not, shr, shl, zero, ones
再添加一种move用于拼合程序,以便减少搜索空间:
第四种move: redundancy: 随机挑选一对在给定的测试用例上有相同输出值的指令nodes,将其中一个的入边全部指给另一个。
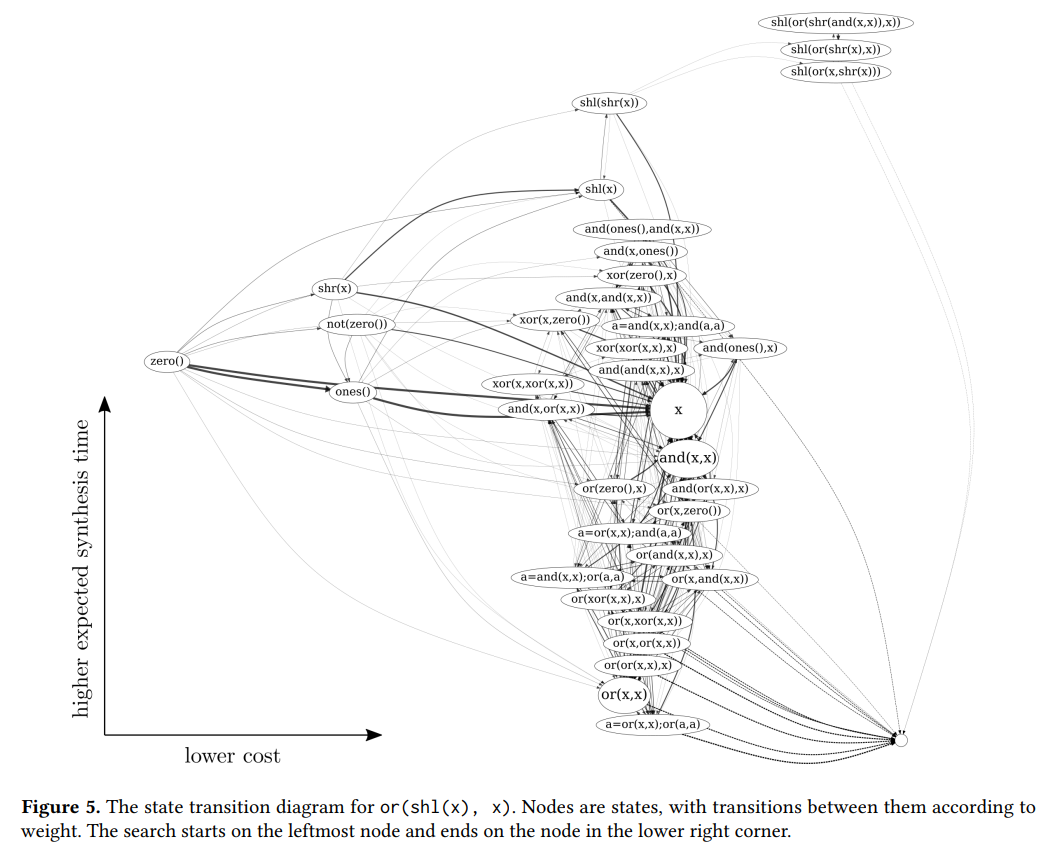
以生成(shl(x), x)为例,从zero状态开始搜索。
运行多次合成实验,并且追踪35个常访问的状态进行采样构建马尔可夫模型。Q: 构建转移矩阵的条件时停留在这组popular states中。(不是一步么?为什么停留?难道是构建整个平台期的?)
在这个简易分析中,non-popular states都被忽略。
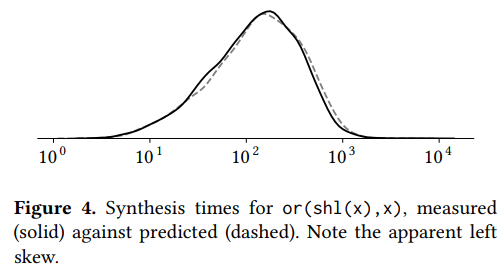
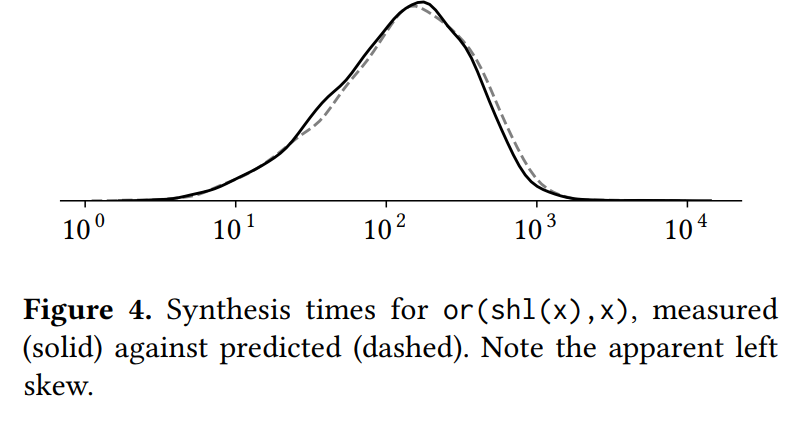
结果,将马尔可夫链的转移时间绘制出来,并且将这个分布与院士合成问题作比较,可以看到分布非常温和。 also note that the distribution appears to be skewed to the left when plotted logarithmically
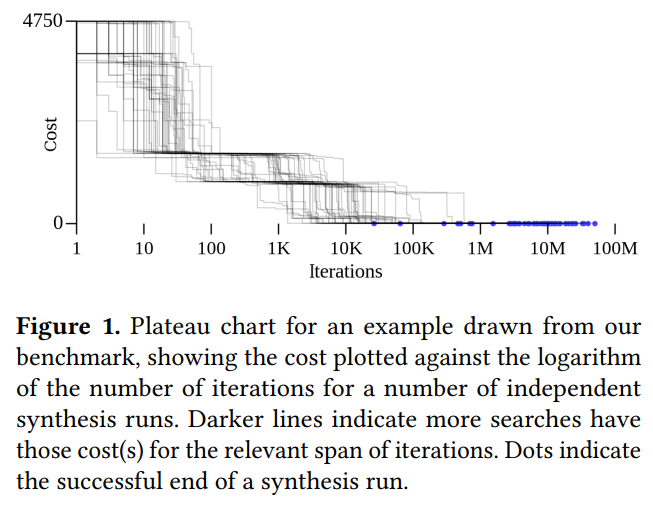
Q:这里画出的每个点是一次trial?还是到达一组popular states?
4.1 平台期
观察结果
- 在图中心有一个强连通分量,搜索将把大部分时间花在这个份量上。由于冗余移动,这些经常转换回到X节点。并且强连通分量中所有状态的costs近似。The key property is the existence of a strongly connected component of the search space where all states have nearly equal costs. 本文称这些区域为strong components。本文认为Strong component会导致平台期。本文将平台期近似为马尔科夫链中的一个节点,设自环概率为1-p。离开该节点的概率为几何随机变量。
- 右上角的连通分量:低cost,高时间代价。本文认为若陷入这个强连通分量,则cost function无明显作用。The paths out of these states are same as indicated by a high expected time to synthesize starting from that state.
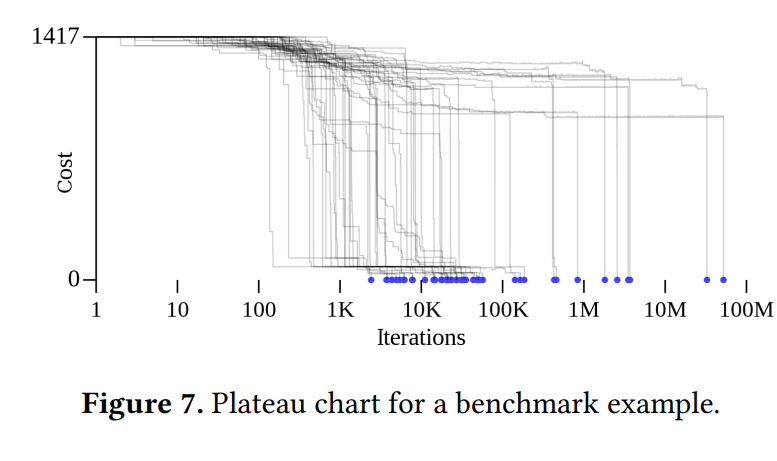
- 本文解释为何左偏分布(Fig7 实际分布要比预测值稍微左偏)因为逃离右上角的概率较小,右上角的强连通分量对整个搜索的时间影响没有中央的强连通分量大。Q:难道不是逃离右上角概率较小,所以反而对整个搜索时间影响更大么
- Q: 预测值是怎么计算的?用转移矩阵?
- Q: 每个点代表什么?逃出一组状态的时间还是结束时间?
- The connectivity of the search space is strongly influenced by the value of β. 当β很大时,cost的影响被削弱(Q: β=1的时候,接近6bits差距也几乎不会被接受?)。所有状态成为倾向于成为同一个连通分量。此时搜索时间接近于几何分布。
- 为此,本文允许搜索状态一步回到原点(zero())
4.2 Multiple Plateaus
- Strong Component:会导致陷入plateau
- One dominated Strong component: 几何分布,标准几何分布(heavy-head distribution或者头尾平衡的)重启可能有害,heavy-tailed distribution上重启才是有意义的。
- Multiple dominated strong components
- 多个分布极度相似:Gamma分布
- 多条路径,每条路径一个dominated strong component: 多个几何分布之和
- 多条路径且每条路径上分布差异极大:正态分布
- 只有一条关键路径,重启实际上是有害的
- 其他非heavy-tail分布
5. Improving Stochastic Synthesis with Restart Strategies
5.1 Restart Strategies
关键问题:何时应当restart?
过去解决方案:使用cutoffs,注意,cutoffs可以是一个序列,也可以是无穷序列
- 没有搜索信息可用:
- Luby算法。cutoffs为1,1,2,1,1,2,4,....
- 时间复杂度
O(T*In(T*)) - 在随机分布上最优
- 时间复杂度
- Luby算法。cutoffs为1,1,2,1,1,2,4,....
- 本文:有cost信息,即how close the search is to success
- 每次重启都会修改cutoff(与Luby相同)
- 其他扩展:expotentiall increasing; inner-outer geometric strategy
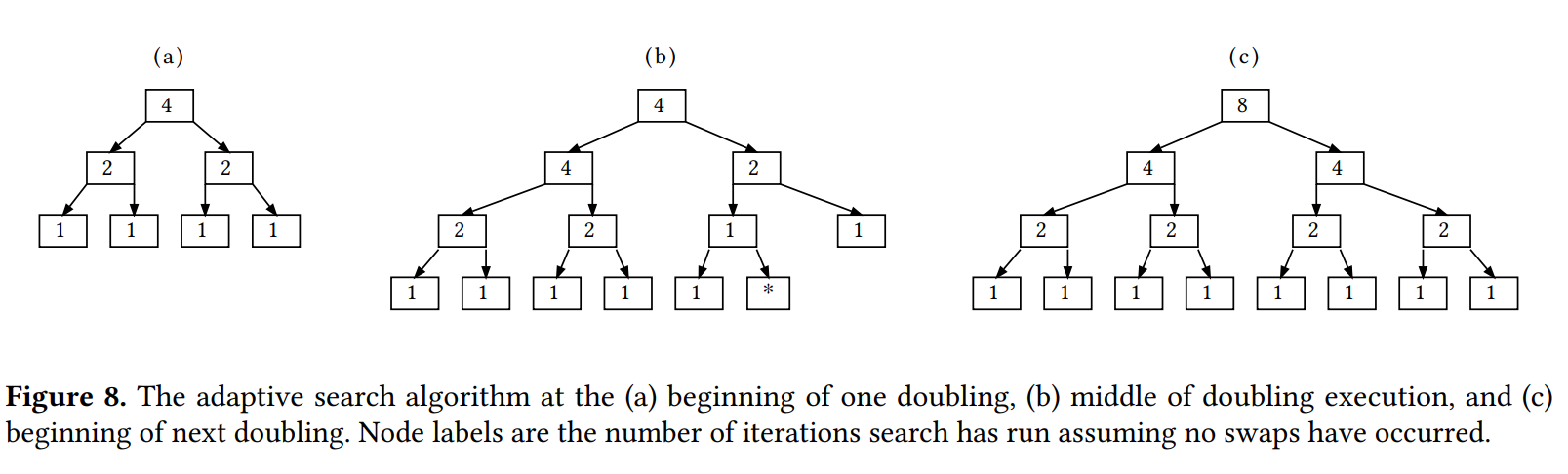
5.2 Adaptive Algorithm

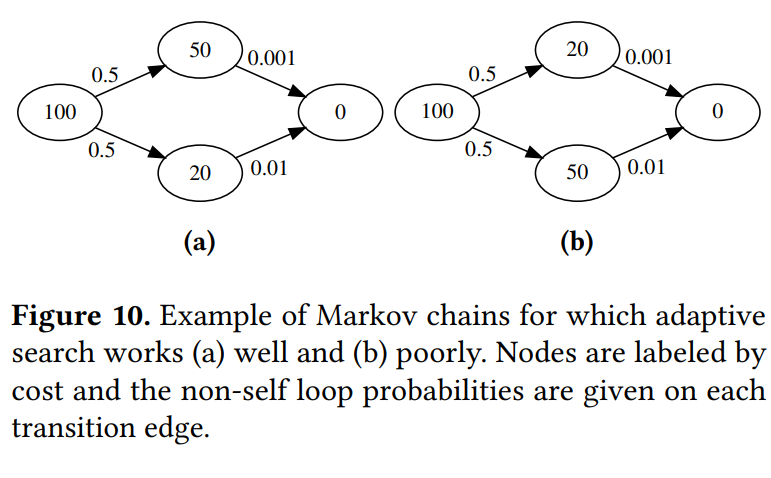
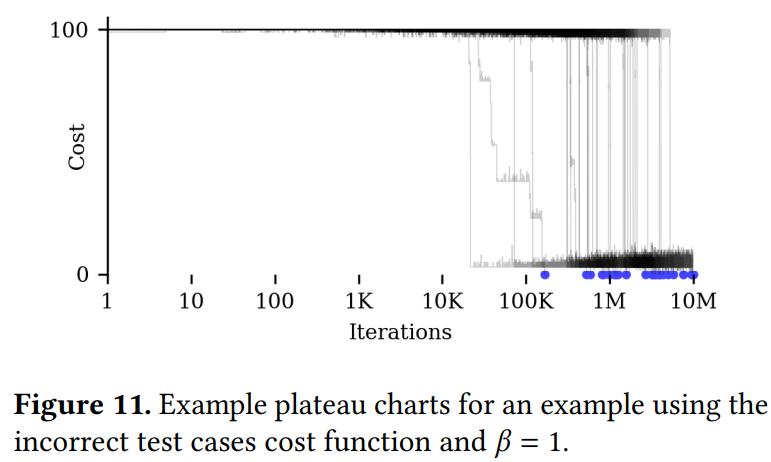
过去的实验只用到了搜索是否已完成的信息,
本文使用新信息:how close the search is to success
Q: Instead of restarting searches, we run searches in parallel but focus search time on searches with low cost. 为何说不是真正的Restart?此外,本文说adaptive algo实际上是在不同的搜索间分配iteration。
前提:在不是最佳成本的搜索上,花时间可以是有益的,可以避免stuck in a long plateau
本文算法分为2步:
- modify Luby restart strategy to run searches in parallel
- 若是将Luby理解为一颗从小到大,不断复制自己然后增长一个power(2, depth)的根节点的二叉树
- 本文则选择将现有标签加倍,然后将每个现有的叶节点添加一对新的1-labeled叶
- how to prioritize searches with low cost
- 让成本最低的运行靠近根有意义。所以若parent有更高成本,就让当前节点对应的候选程序与parent交换
5.2.1 Model Markov Chains
当low cost与易达终点并无直接关系时,本文反而比Luby更慢
5.2.2 Effect of 𝛽 on Search Space
- β越高,各状态集越接近强连通分量,搜索越接近随机游走,时间分布接近几何分布。不是heavy-tailed分布,此时重新启动有害。
- 最好算法:不启动的朴素算法
- 本文:比Ruby好,因为有成本,不会像Luby一样频繁重启。Luby将时间花在短搜索上,这些短时搜索在重启前未达到cost更低的plateau就频繁重启
- β越低,越可能卡在某个cost低且较复杂的plateau。
- 最好算法: Luby
- 本文:可以重启
6. Superoptimization Synthesis Benchmark
6.1 Generating the Standard Benchmark

- 来源:Ubuntu 16.04 x86_64 binaries
- 特点: Dataflow-related: 删掉了与计算某个特殊output无关的指令
- 步骤
- 考虑在基本块之后仍然live out的寄存器r
- 取所有与r的计算相关的指令
- 将所有和内存读有关的都换成没用到的寄存器读
- 若code fragment中有至少2个non-trivial instructions,则选为potential synthesis problem,此时有180k个
- 使用instruction signature分类去重,分类时忽略纯粹的数据移动指令,得到9719个
- 给定n,从n-1长的程序prefix开始合成,看能否合成到n步。这一步是为了排除不能合成的程序
- 随机选择1k个。
- 局限
- 没有内存相关操作
- all straight line code,没有分支也没有loops
- 提取不全,比如本文disassembler不支持的都没有取
7. Evaluation
7.1 Effect of β
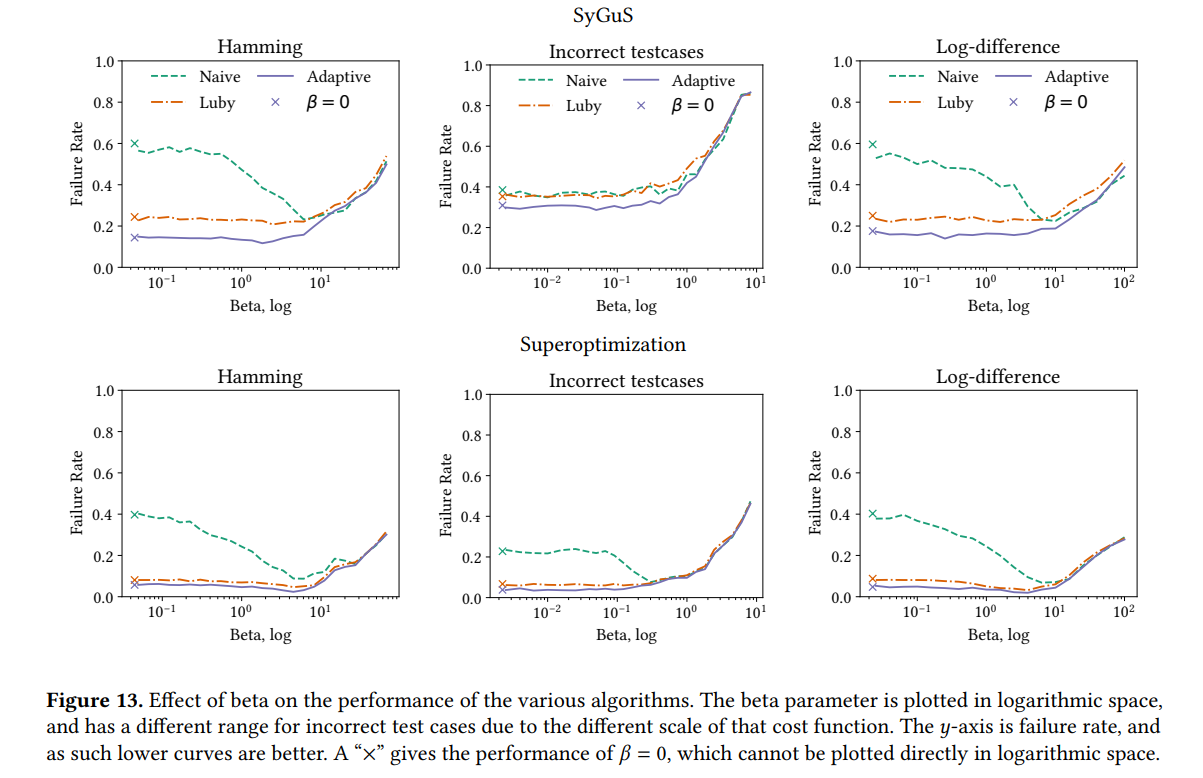
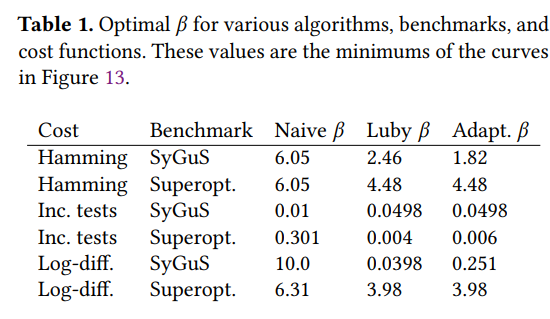
7.2 Calculating Mean Time to Synthesize
7.3 Algorithm Comparisons and Discussion

 浙公网安备 33010602011771号
浙公网安备 33010602011771号