
Proj FuzzViz Paper Reading: A Scalable Log Differencing Visualisation Applied to COBOL Refactoring
Abstract
解决目标:大型代码重构项目的重构过程可视化
方法:基于日志的行为差异可视化
为了适应大型项目:
visualisation tool that highlights those parts that really changed in-between iterations of a large refactoring process and collapses those parts that remain stable.
1. Intro
本文: log-based behavioural differencing, 对象为重构进程
基于M. Goldstein, D. Raz, and I. Segall, “Experience Report: Log-Based
Behavioral Differencing,” in Proceedings of the 28th International
Symposium on Software Reliability Engineering (ISSRE), 2017, pp. 282–
293, DOI: 10.1109/ISSRE.2017.14.
做了是英语大型项目的处理
主要方法:折叠掉不怎么重要的点和链,
需求:
起因:需要为Raincode Lab(一家提供陈旧系统迁移和现代化服务的编译器厂家)比较不同的重构进程
对象:PACBASE migration(一个第四代自动生成COBOL代码的语言),这个系统已经于2015年退役,但生成的这些代码人类难读,现在Raincode写了一个系统来讲这些生成的代码转化为刻度代码,但是这个系统有很多refactoring rules.
为什么需要可视化:因为这些规则需要顾客来决定如何采用
作用:可视化启动或者仅用一条规则的影响,具体来说就是高亮改变
本文的贡献:
- 使用并拓展Goldstein的算法
- 进行了一些改进,增进了Goldstein的可读性
- 工业化场景
- 验证了自家系统能用
已有的方法
A. Motivation
介绍Goldstein的log-based behavioural differencing algorithm
What step(s), if any, happened in p1 but not in p2?
What step(s), if any, happened in p2 but not in p1?
What step(s) are common to p1 and p2?
How has the execution of p2 changed with respect to p1, i.e. are some steps present in p1 happening more or less often in p2?
介绍可视化目标
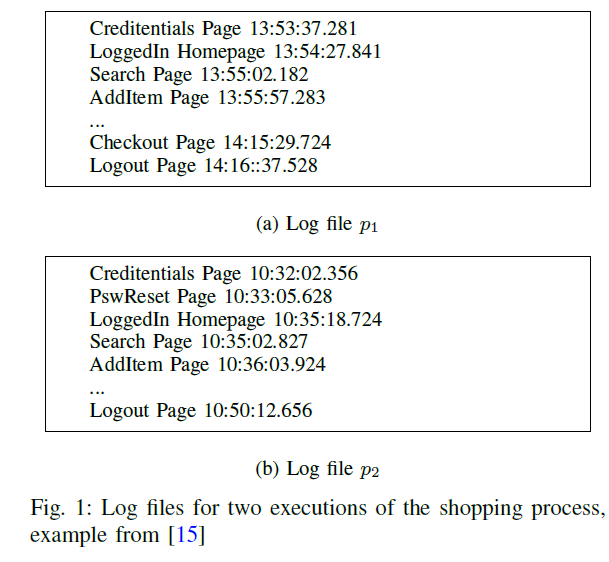
例如,在online store中,p1可能代表一个正常但是旧的网站版本,而p2代表新的版本
收集p1和p2的文字log心机,将这些改为状态自动机,然后用比较算法比较,把改变高亮出来
本文用来可视化在一些rule set激活前后的改变
B. Log-based behavioural differencing
基本步骤
- 规范化Logs
- 收集相关信息
- 相关信息可能包含debug信息、错误信息、时间戳、硬件信息等等,需要筛选
- 本文的目标是分析网站的流,查看哪些网页、产品会被客户访问最多、客户可能会被哪些网页阻塞、哪些网页的加载时间过长,因此,本文只用带时间戳和页面访问的
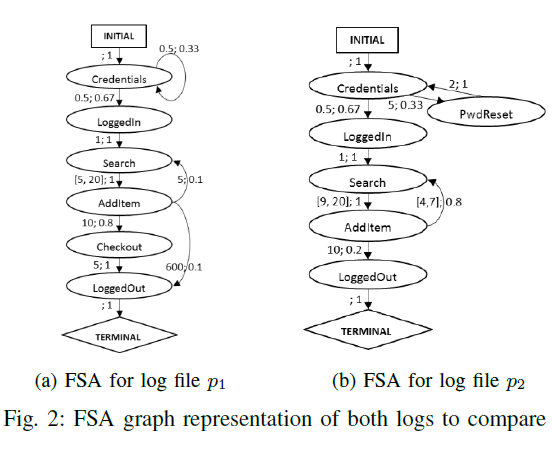
- 使用kTails提取FSA模型
- 输出.dot格式,可用graphviz可视化
- 对比两条轨迹,计算不同。
- 目标:保留全部节点但是可以去掉边,将节点标记为a. 都有 b. 删除 c.添加,将边标记上时间戳和转移可能
- 步骤
1. 计算一条从起始点到重点的公共路径,公共路径指全部节点的label相同。
2. Common nodes are defined as those having the same label and being part of at least one common path.
3. Added nodes are nodes that are present in the second model and not common, while removed nodes are present in the first model but not in the set of common nodes
4. a node is considered common if it has a label that is unique to its model and happens in both compared models
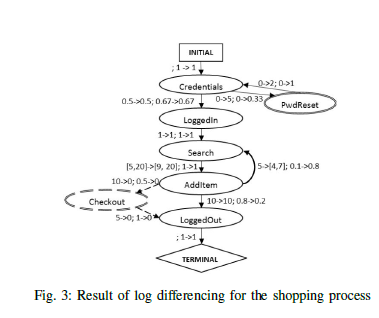
C. Visualization
III. 工业场景
A. 直接应用
Step1: 确定需要获取的信息
- 不要警告、错误信息
- 只记被触发的规则名称
- 没有记录每步时间,因为这个功能很少用到
Step2: kTails, Perfume算法被换成Synoptic算法
Step3: 说了用颜色表达状态之类的。还表达了可拓展性
force-based layout: This layout differs from the linear layout used by Goldstein et al. which is arguably more readable as it follows a natural top-to-bottom reading path, but would not scale up to these size of graphs as it would not fit on a single page or screen

B. Limitations of the visualizatin

- 稀疏图外加有小圈,导致理解困难
- 实际上有很多长链(iterative step-by-step nature of the refactoring process),算是线性的,这些细粒度的信息不会提供特别多信息但是占了图中绝大部分
- changes often tend to happen in clusters
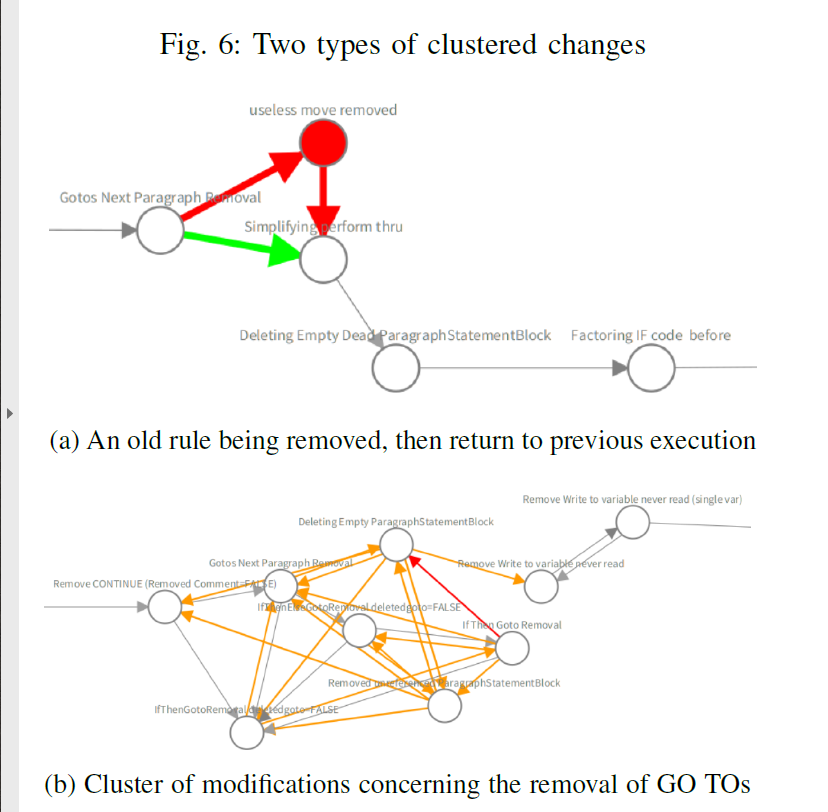
为此,创建了merge algo
Two linked nodes are merged if they fit the following criteria:
- Both nodes are common (neither added or removed, i.e. not in green or red);
- No transition edge from or to those nodes is added or removed;
- No transition edge to or from those nodes has seen a probability change between the two variants of the process (i.e. in orange).
The merge conditions ensure that no key insight will be hidden from the user when looking at the resulting graph
4. Validation
- 描述对象
- 描述metrics
- 用旧的算法需要多久算出图
- 描述可视化规模
- 加上工程师之后怎么做

