


Proj THUDBFuzz Paper Reading: IJON: Exploring Deep State Spaces via Fuzzing
Abstract
P1: 背景: 目前fuzzing难以解决一些条件,比如需要复杂状态自动机的
P2:
提出IJON-可以使用人工注解来辅助fuzzer工作(allows a more systematic exploration of the program's behavior based on the data representing the internal state of the program)。
实验:
- 能解决其他fuzzer或者符号执行工具不能解决的问题
- 能找到新的bugs,这些bugs都需要全面和定制化的语法才可能用其他fuzzer测出来
- 能在GCC数据集上解决很多挑战
1. Intro
P1-3: fuzzing已有相当进展;但是还存在很难被解决的constraints阻碍测试,此外,状态空间太大也会导致fuzzing不成功
P4-7: 人力的优越
2. Tech Background
A. AFL Coverage Feedback
B. Extending Feedback Beyond Coverage
为了解决fuzzer被卡住的问题,已经提出了多种方法:
- LAF-INTEL: 目的在于解决magic byte constraints。将大的compare instructions切分成若干段小的比较,这样fuzzer就能挨个解决这些小型比较。
- STEELIX: 和LAF-INTEL思路相似,但是使用了动态插桩
- ANGORA: 为每个函数都分配一个随机识别符,然后执行时将所有执行到的函数识别符都整合计算为一个hash值,
3. Design
找到一个最好的度量指标是件很困难的事情。
A State Exploration
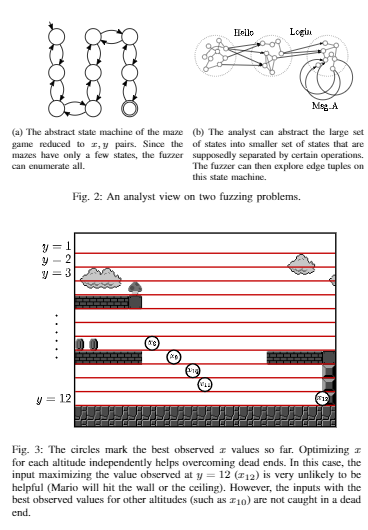
P1: 本节的主要目的是为了展示现有的技术很难构造一些代码
方法: 使用先进的fuzzers做了多组offline实验
在实验过程中遇到的困难问题:
- Known Relevant State Values:
Sometimes, code coverage adds no feedback to help the fuzzer to advance.
如前所述,有时代码覆盖率几乎不产生有关程序状态的信息,因为所有有趣的状态都存储在数据中。

在例子迷宫问题中,实际上只有四个分支可以覆盖,因此仅覆盖并不足以说明有趣的行为。 - Known State Changes:

用户可能不知道相关状态的哪些部分值得探索,或者状态可能散布在整个应用程序中并且难以识别。可替代地,状态可以是已知的,但是不能识别出足够小的子集以用于直接引导模糊器。但是,可能可以标识预期会更改状态的代码部分。这种情况通常发生在使用高度结构化数据(例如消息序列或文件格式的块列表)的应用程序中。在这种情况下,用户可以创建一个包含消息日志或块类型日志的变量,而不是直接公开状态本身。该变量可以充当实际状态变化的代理,并且可以暴露给反馈功能
- Missing Intermediate State:
人类分析人员通常可以推断程序的行为方式,并且通常可以提供进度指示器。通过将此指标编码为其他人为的中间状态,分析人员可以引导模糊器。

B. Feedback Mechanisms
我们设计了一组注释,以使分析师能够影响模糊器的反馈功能。我们的目标是使分析人员可以使用这些注释为模糊过程提供高级指导。
在交互式的模糊测试会话中,分析人员会不时检查代码覆盖率,以识别似乎难以覆盖的分支。
然后,分析人员可以确定模糊器无法取得进展的原因。
找到障碍后,分析人员可以开始第二次模糊测试会话,重点是使用自定义注释解决此障碍。
批注本身是目标应用程序的一个小补丁,通常由提供额外反馈信息的一行(有时是两行)代码组成。当模糊器解决路障时,长时间运行的模糊会话会从临时会话中选择会产生新覆盖的输入,并继续进行模糊检测,从而克服了困难的情况。
我们设计了四个可用于注释源代码的通用原语:
1)我们允许分析人员选择与解决当前问题相关的代码区域。
2)我们允许直接访问AFL位图以存储其他值。位图条目可以直接设置或递增,因此可以将状态值公开给反馈功能。
3)我们使分析师能够影响覆盖范围的计算。这允许相同的边缘覆盖范围导致不同的位图覆盖范围。这允许在不同状态下创建更细粒度的反馈。
4)我们引入了一个原语,该原语允许用户添加爬山优化[48]。
C. IJON-Enable
用于开启/关闭coverage feedback

示例1.考虑清单4中的注释(绿色突出显示)。在此示例中,IJON-ENABLE将限制为只覆盖到达带注释行且x值为负值的输入。 该注释使模糊测试者可以专注于难题,而不会浪费时间探索输入队列中的许多其他路径。
D. IJON-INC和IJON-SET
IJON-INC和IJON-SET批注可用于增加或设置位图中的特定条目。 这有效地允许将状态中的新值视为等同于新的代码覆盖率。 分析人员可以使用此注释将状态的各个方面选择性地暴露给模糊器。 结果,模糊器便可以探索该变量的许多不同值。 实际上,此注释增加了代码覆盖范围之外的反馈机制。

示例2.考虑清单5中所示的注释。每次x更改时,位图中的新条目都会增加。 例如,如果x等于5,我们将基于当前文件名和当前行号以及值5的哈希值计算位图中的索引。然后,位图中的相应条目将递增。 这使模糊器可以bit by bit学习各种输入。
IJON-SET不设置条目的增量,而是直接设置位图值的最低有效位。 这使得可以控制位图中的特定条目来引导模糊器。

如果无法轻易观察到状态,则可以使用状态更改日志记录(如前所述),在其中注释已知会影响我们关心的状态的操作,并将状态更改日志用作反馈的索引。
示例4.作为另一个示例,请考虑清单7。在成功解析和处理了每条消息之后,我们将表示消息类型的命令索引附加到状态更改日志中。 然后,我们设置一个由状态更改日志的哈希值寻址的位。 结果,每当我们看到多达四个成功处理的消息的新组合时,模糊器就会认为输入很有趣,从而在应用程序的状态空间中提供了更好的覆盖范围。
E.IJON-STATE
如果无法轻松串联消息(例如,因为有消息计数器),则状态更改日志可能不足以探索不同的状态。 为了产生更细粒度的反馈,我们可以探索状态和代码覆盖率的笛卡尔积。 为了实现这一点,我们提供了第三个原语,该原语能够更改边缘覆盖范围本身的计算。 与ANGORA相似,我们使用名为“虚拟状态”的第三个组件扩展了边缘元组。 在计算任何边缘的位图索引时,也会考虑此虚拟状态分量。 此注释称为IJON-STATE。 只要虚拟状态发生变化,任何边缘都会触发新的覆盖范围。 必须谨慎使用此原语:如果虚拟状态的数量增加太多,则模糊器会被大量输入淹没,这实际上会减慢模糊处理的进度。


示例5.考虑清单8中提供的示例。如前所述,在没有注释的情况下,模糊测试人员可能难以探究各种消息的组合。 通过将协议状态显式添加到模糊器的虚拟状态,我们可以根据协议状态创建代码的多个虚拟副本。 因此,模糊器能够在协议状态机的各种状态下完全探究所有可能的消息。 实际上,相同的边缘覆盖率现在可以导致不同的位图覆盖率,因此模糊器可以有效地探索被测程序的状态空间。 请注意,为防止状态爆炸,状态只有三个可能的值。 结果,一旦成功通过身份验证,模糊器就可以完全重新探究整个代码库。
F.IJON-MAX
到目前为止,我们主要处理的是提供可用于增加所存储输入的多样性的反馈。 但是,在某些情况下,我们希望针对特定目标进行优化,或者状态空间太大而无法完全覆盖。 在这种情况下,我们可能不关心一组不同的值,或者想要丢弃所有中间值。 为了在这种情况下实现有效的模糊处理,我们提供了一个称为IJON-MAX的最大化原语。 它有效地将模糊器变成了基于爬山的通用黑匣子优化器。 为了使一个以上的值最大化,提供了多个(默认为512个)插槽来存储这些值。 像coverage位图一样,每个值都独立最大化。 使用此原语,还可以通过最大化x来轻松构建x的最小化原语。

考虑视频游戏《超级马里奥兄弟》,其中玩家在侧向滚动游戏中控制角色。在每个关卡中,目标都是到达关卡的尽头,同时避免诸如敌人,陷阱和陷阱之类的危险。如果角色被敌人触摸或掉进坑中,则游戏结束。为了正确地探索游戏的状态空间,达到每个关卡的末尾很重要。如清单9所示,我们可以通过要求模糊器尝试最大化玩家的x坐标来完成关卡。鉴于这是一款横向滚动游戏,因此可以有效地指导模糊测试者找到成功完成关卡的方法。然后,IJON-MAX(slot,x)注释告诉模糊器最大化字符的x坐标。请注意,我们使用玩家的y坐标(高度)来选择广告位。这使我们能够在水平范围内独立地最大化不同高度上的进度。通过增加输入集的多样性,我们减少了陷入死胡同的机会,如图3所示。使用这种技术,我们可以快速找到32个游戏关卡中的29个的解决方案。有关更多详细信息,请参见第V-C节。
IV. Implementation
我们将IJON实施为基于AFL的多个模糊器的扩展:AFLFAST,LAF-INTEL,QSYM和ANGORA。
主要的实现有两方面:
- annotation
- communication channel to target
A. Adding Annotations
AFL附带了一个用于clang的特殊编译器pass,可对每个分支指令进行检测。 此外,AFL提供了一个wrapper,可以使用它而不是clang来编译目标。 该wrapper自动注入自定义编译器pass。 我们扩展了wrappere和编译器pass。 为了支持我们的更改,我们引入了一个附加的运行时库,编译器将其静态链接。 运行时实现了可用于注释目标应用程序的各种帮助器功能和宏。 特别是,我们增加了对快速哈希函数的支持,该函数可用于生成分布更好的值或将字符串压缩为整数。 总之,我们使用了第三节中的原语,并添加了一些更高级的辅助函数。
1)IJON-ENABLE:为实现IJON-ENABLE,我们引入了一个应用于所有位图索引计算的掩码。如果掩码设置为零,则只能寻址和更新第一个位图条目。如果将其设置为0xffff,则使用原始行为。这样,我们可以有效地禁用和启用覆盖范围跟踪。
2)IJON-INC和IJON-SET:这两个注释都启用了与位图的直接交互,因此实现起来很简单。调用ijon_inc(n)后,位图中的第n个条目将递增。同样,调用ijon_set(n)会将第n个条目的最低有效位设置为1。如果在程序代码中的多个位置使用了这些功能,则必须非常小心,不要重用相同的位图索引。为避免此类情况,我们引入了辅助宏IJON_INC(m)和IJON_SET(m)。这两个宏都调用相应的函数,但根据m的哈希值以及宏调用的文件名和行号来计算位图索引n。因此,避免在常用参数(例如0或1)上发生小冲突。
3)IJON-STATE:调用IJON_STATE(n)时,我们更改了将基本块边缘映射到位图条目的方式。为此,我们更改边缘元组的定义,以在源ID和目标ID(state,ID,IDT)之外还包括state。这里,"state”是线程局部变量,其存储与当前状态有关的信息。调用IJON_STATE(n)更新state := state^n.。这样,两个连续的呼叫会互相抵消。我们还修改了编译器遍历,以便按以下方式计算位图索引: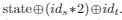
。
4)IJON-MAX:我们扩展了模糊器,以保持额外的第二输入队列以实现最大化。我们支持最多增加512个不同的变量。这些变量中的每一个都称为一个插槽。模糊器仅存储为每个插槽产生最佳值的输入,并丢弃导致较小值的旧输入。为了存储最大的观测值,我们引入了一个额外的共享内存max-map,该映射由64位无符号整数组成。调用最大化原语IJON_MAX(slot,val)会更新maxmap [slot] = max(maxmap [slot],val)。执行测试输入后,模糊器将检查共享位图和最大图是否有新覆盖。与共享覆盖位图和全局位图的设计类似(如第II-A节中所述),我们还实现了全局最大图,该图在整个模糊测试过程中都将持续存在,并补充了共享最大图。与位图相比,没有存储区应用于共享的max-map。如果共享的max-map中的条目大于全局max-map中的相应条目,则认为该条目是新颖的。由于我们现在有两个输入队列,因此我们还必须更新调度策略。 IJON要求用户提供使用原始队列(从代码覆盖率生成)或最大化队列(从最大化时隙生成)的概率。使用此功能,用户可以决定哪个队列在选择fuzzing输入方面更具权重。用户可以提供环境变量IJON_SCHEDULE_MAXMAP,其值为0到100。每次计划新的输入时,模糊器都会绘制一个介于100到100之间的随机数。如果随机数小于IJON_SCHEDULE_MAXMAP的值,则会进行通常的基于AFL的调度。否则,我们在max-map中选择一个随机的非零时隙,并模糊对应于该时隙的输入。如果在模糊其输入的同时更新了相同的插槽,则旧的输入将立即被丢弃,并且基于新近更新的输入,将继续进行模糊测试阶段。
5) Helper Function
B. Communication Channel
基于AFL的模糊器使用包含共享位图的共享内存区域。

