Proj THUDBFuzz Paper Reading: The Art, Science, and Engineering of Fuzzing: A Survey
2. Systemization, taxonomy and test programs
fuzzing目前包含很多方面的东西,如:
- dynamic symbolic execution
- grammar-based test case generation
- persmission testing
- behavioral testing
- complexity testing
- kernel testing
- representation dependence testing
- function detection
- robustness evaluation
- exploit development
- GUI testing
- signature generation
- penetration testing
- embedded devices
- neural network testing
2.1 Fuzzing and Fuzz Testing
2.2 Paper Selection Criteria
CCS, S&P, NDSS, USEC, FSE, ASE, ICSE
2.3 Fuzz Testing Algo

2.4 Taxonomy of Fuzzers
2.4.1 Black-box Fuzzer
IO-driven, data-driven testing
e.g: funfuzz, Peach 使用关于输入的结构化信息来生成有意义的输入
adaptive random testing中也有类似的想法
2.4.2 White-box fuzzer
2007, Dynamic Symbolic Execution(DSE, concolic testing), 提出白盒测试这个概念
一般会结合动态插桩,SMT Solving
2.4.3 Grey-box Fuzzer
一般会有轻量的静态分析
e.g: EFS, Randoop, AFL, VUzzer
2.5 Fuzzer Genealogy and Overview
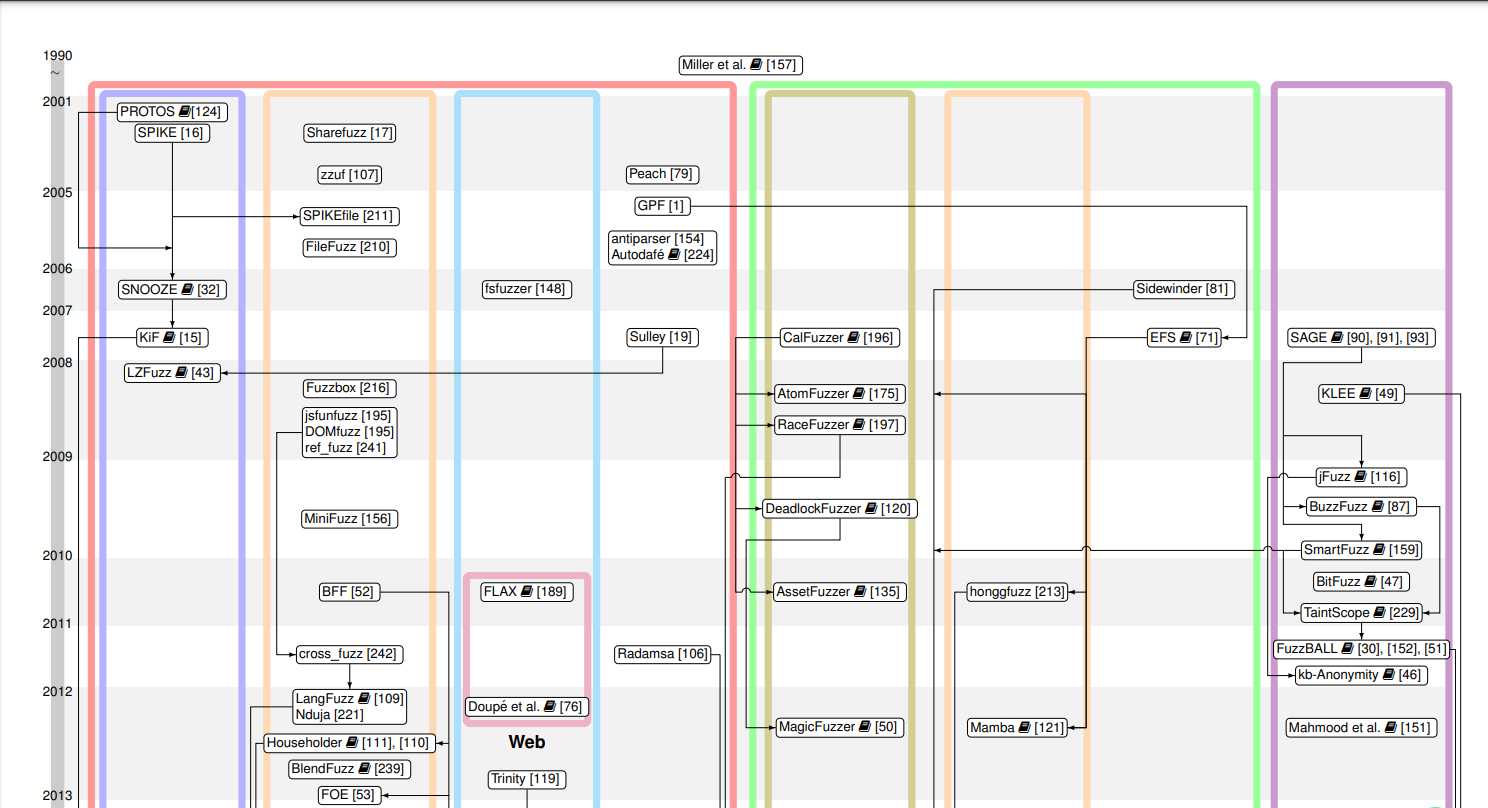
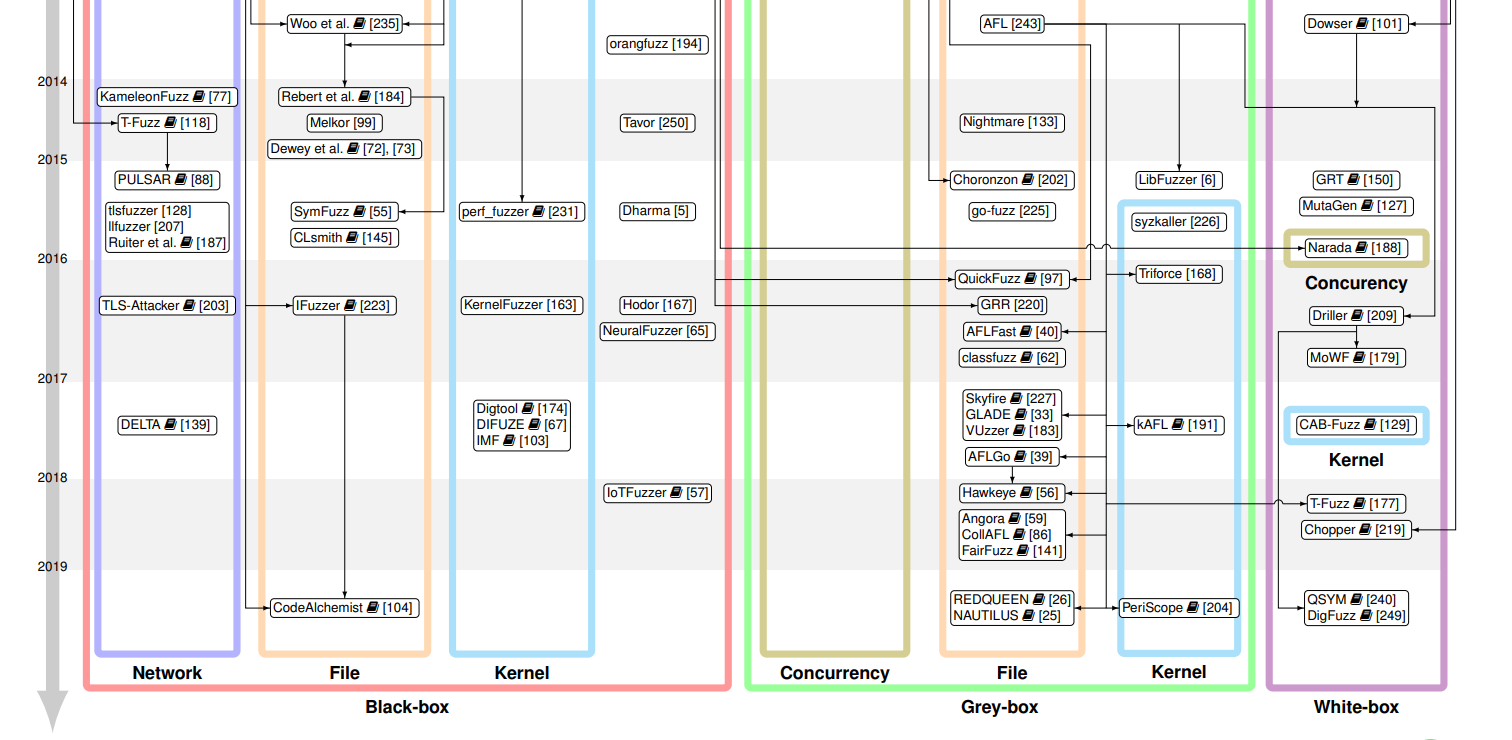
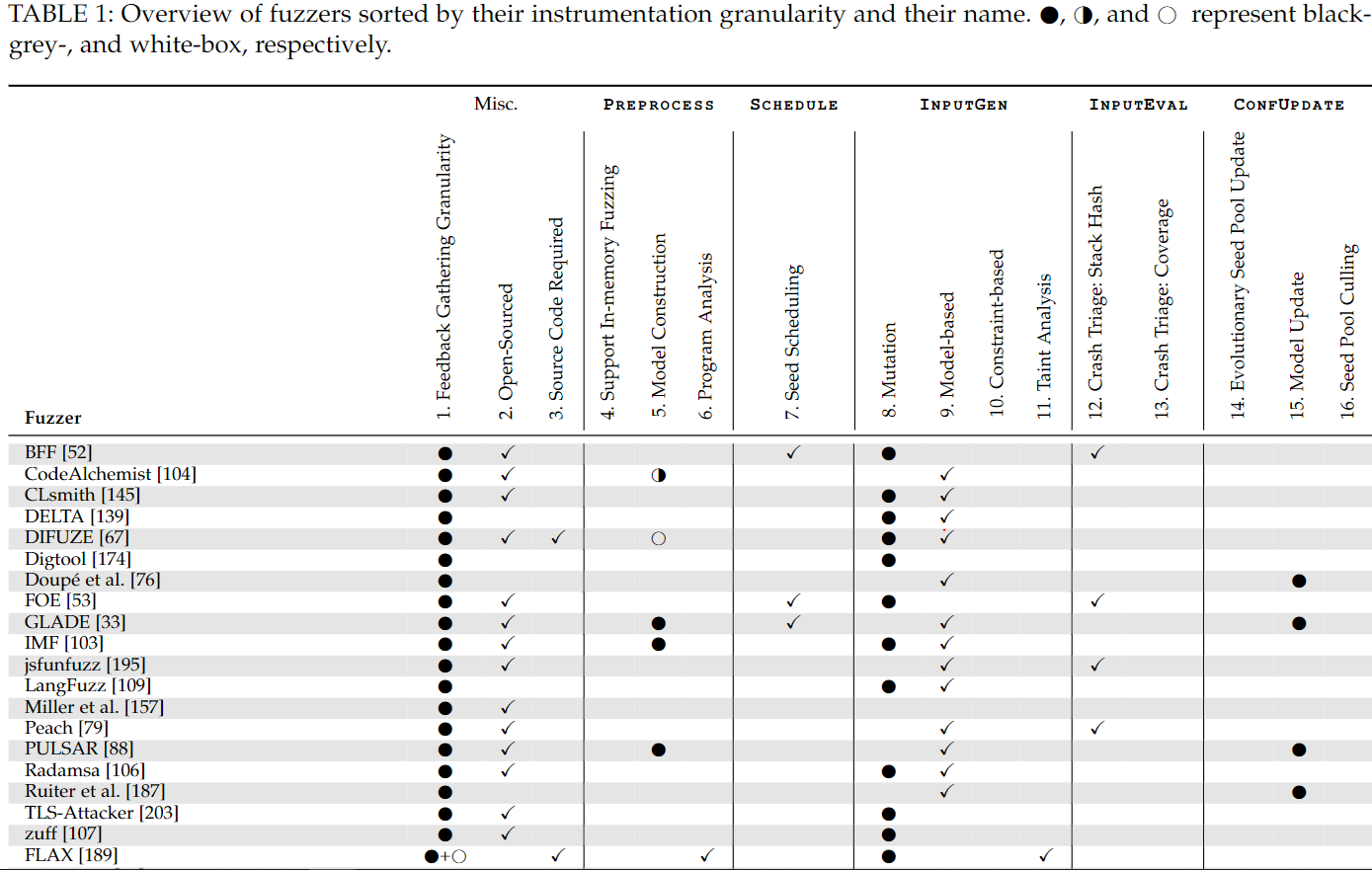
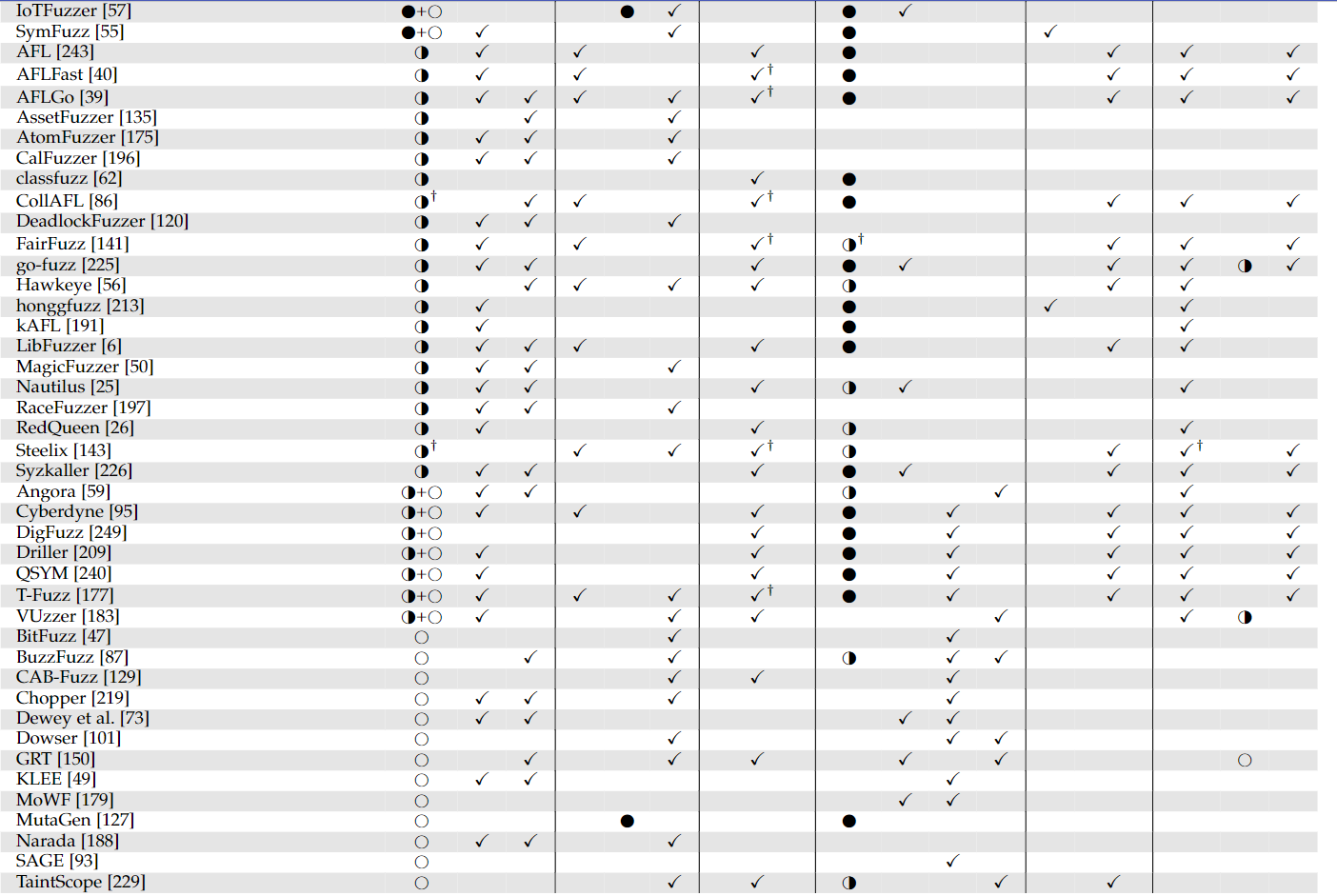
3 Preprocess
在第一轮fuzz iteration之前修改fuzz configurations.
常用preprocess策略:
- 插桩
- 删掉冗余的configuration,比如seed selection
- trim seed
- generate driver applications
3.1 Intrumentation
尽管也可以通过处理器traces或者system call usage获得一些程序执行信息,大部分的信息还是通过插桩获得的。
静态插桩一般是在编译阶段对中间代码或者对源代码进行的。因为它发生在运行之前,所以相对消耗的时间比动态更少。
如果待测程序依赖于库,这些库都需要被分别插桩。其实也有binary-level基于二进制程序的静态插桩。
动态插桩可以对新动态链接进来的库进行插桩,比如DynInst, DynamoRIO, Pin, Valgrind, QEMU
一般fuzzer能够支持多种插桩方式,比如AFL就能够支持源代码静态插桩和QEMU帮助下的动态插桩。此外,AFL可以只对目标程序本身插桩,也可以对目标程序加上引用的库都插桩。
3.1.1 Execution Feedback
- LibFuzzer, AFL计算branch coverage,由于这些信息被存在compact bit vector中,可能造成数据丢失
- CollAFL引入path-sensitive hash function来解决这个问题
- Skyzkaller: 使用node coverage
- honggfuzz允许用户来选择用什么coverage
3.1.2 Thread Scheduling
- 插桩本身能够被用于出发不同的程序行为,比如可以显式控制线程执行,能有效地找到race condition bugs
3.1.3 In-Memory Fuzzing
有的时候每个fuzz-iteration都re-spwaning是比较大的代价,例如复杂的GUI程序往往需要数秒时间启动。解决这个问题的方案有:
- memory snapshot: 在没有处理任何输入时先建一个memory snapshot,执行完了之后再复位
- fork server: 可以避免execve
- In-memory API fuzzing: 在某个函数上进行in-memory fuzzing,每次迭代之后不尝试恢复状态,例如AFL的persistent mode
- 缺点: 1. bug可重复性差 2. 多次function calls之后会有难以捕捉的边际效应
3.2 Seed Selection
- 缩减最初种子池的规模: 采用最小代价覆盖
- AFL的minset是基于branch覆盖的
- Honggfuzz是基于执行的指令数目,分支数目和独特的code blocks数目综合来计算coverage
3.3 Seed Trimming
- AFL使用Seed Trimming技术,迭代地删掉种子一部分,保持种子的coverage不变
- Rebert等给更短的种子更高的优先度
- Moonshine拓展了Skyzkaller的方法,在缩减种子大小的同时能够用静态分析来保存调用之间的依赖关系
3.4 Preparing a Driver Application
例如为了测试kernel,利用已有的用户应用程序来测;为了测试IoT设备,利用已有的手机控制程序来测
4 Scheduling
4.1 The Fuzz Configuration Scheduling Problem
The goal of scheduling is to analyze the currently-available information abount the configurations and pick one that is likely to lead to the most favorable outcome.
exploration-exploitation conflict
4.2 Black-box FCS Algo
黑盒测试能够得到的信息很少,往往只有crashes的结果,花费的时间等信息
- HouseHolder等
- 将黑盒变异建模为一系列Bernoulli trials
- 偏好#unique crashes/#runs更高的conf
- 最终的确用BFF在单位时间内找到了更多的crashes
- Woo等
- 将模型定义为Weighted Coupon Collector's Problen with Unknow Weights,在每次trial之后学习一个递减的成功概率上限
- 在fuzzing过程中做多路采样(MAB)
- 使用时间对成功概率做正则化
- 使用成功概率对新fuzz iteration做redefine
4.3 Greybox FCS algo
- AFL使用演化算法,初始化一些configurations,并且为每个conf计算初始fitness,接着,不断选择并尝试使用它们,进行遗传变异重组操作
- 主要问题: what makes a conf fit? how confs are selected? how a selected conf is used?
- 回答: 包含最快最小input的conf fit; 维持一个confs环形队列; 会给予更多runs机会
- AFLFast
- 优先能够探索新/稀有路径的conf
- 建立了power scedule机制,能够更加动态地为每个conf分配运行次数-初始化energy比较小比较均一,使得所有conf都至少运行过,接着指数增长,使得有价值的conf充分运行
- 会使用已经生成的inputs数目对energy进行归一化,运行less-freq conf
- FidgetyAFL: 在AFL上实现AFLFast
- AFLGo: 按照能否到达指定位置来给定权重
- Hawkeye: 为directed fuzzing的seed scheduling和input generation引入静态分析
- FairFuzz: 为每对种子和rare branch引入mutation mask来加强rare branch的覆盖
- QTEP: 使用静态分析分析哪一部分更可能出错,并且加重权重
5 Input Generation
Mutation based fuzzers are generally considered to be modelless since seeds are merely example inputs and even in large numbers they do not completely describe the expected input space of the PUT.
5.1 Model-based/Generation-based Fuzzers
5.1.1 Predefined Model
- Peach, Protos, Dharma等: 允许用户指定输入语法
- Autodafe, Sulley, SPIKE, SPIKEfile, LibFuzzer:有API能够让用户创建自己的input models
- Travor: 允许EBNF语法的输入说明
- PROTOS, SNOOZE, KiF, TFuzz: 用户需要指定network protocal specification
- Kernel API fuzzers如[119], [226], [163], [168], [231]等,都定义了system call templates,里面会指定系统调用的参数的类型和个数
- Nautilus: general-purpose; grammar-based input; grammar-based seed trimming
- Dewey等: 借助constraint logic programming,生成语义正确的test case
- LangFuzz: 在有用户提供的语法的同时,从种子中随机结合来生成新的语法正确的种子。
- BlendFuzz: 和LangFuzz类似,只不过在XML和正则表达式上效果更好
more specified works:
- crossfuzz, DOMfuzz: 生成DOM objects
- jsfunfuzz: 语义正确的js code
- quickfuzz: Haskell libraries
- 特定网络协议: Frankencerts, TLS-Attacker, tlsfuzzer, llfuzzer
5.1.2 Model Inference
Automated input format和协议逆向分析的技术已经很成熟。[69], [48], [146], [66], [31]
预处理阶段
- TestMiner在待测程序中搜索例如常量之类的数据,用于预测可行的inputs
- Skyfire在给定grammar和种子集之后,推测上下文敏感概率文法
- IMF: 通过分析系统API调用日志来产生调用API的c代码
- CodeAlchemist: 将js代码拆成code bricks,计算assembly constraints。这些约束最后以动态和静态的方式共同解决。
- Neural, Learn&Fuzz, Liu等: 通过测试文件集合学习模型,再用这个模型来生成test cases
在一定执行之后
- PULSAR: 通过抓住的packets, 自动推测网络协议模型。PULSAR会在内部生成一个状态机,将message token和具体的状态关联起来
- Doupe等: 通过观测到的IO行为推测网络服务的状态机,再用来寻找bug
- Ruiter等: 面向TLS,基于LearnLib的实现
- GLADE: 从IO样本集合中合成上下文无关文法用来fuzzing
- go-fuzz: 为每个种子建立模型来生成新输入
- Shen等: 使用神经网络解决复杂的branch condition进而生成输入
5.1.3 Encoder Model
一般,测试目标可以视作某些file formats的decoder,MutaGen借用这些文件类型的encoders,通过对这些encoder程序产生变异,获得slightly malformed inputs
5.2 Model-less/Mutation-based Fuzzers
随机生成的数据很难满足输入格式需求,为此,seed-based input generation获得了长足研究,seed可以是一个文件,一个network packet,或者一串UI事件
5.2.1 Bit-flipping
有些软件会限制只能一次flip一定数目的,有些则是纯随机。
- SymFuzz展示了fuzzing performance和mutation ratio息息相关,而且对目标程序特异,SymFuzz用白盒分析为每个种子确定mutation ratio
- BFF和FOE试着使用指数级别的mutation ratio sets来对每个seed做测试。
5.2.2 Arithmetic Mutation
AFL和honggfuzz可以把选中的byte sequence取出来,加或者减一个数
A key intuition is to bound the effect of mutation by a small number.例如在AFL中,这个range是i+-r, 0< r <=35
5.2.3 Block-based Mutation
- 在随机处插入一个随机生成的block
- 删除
- 替换为值
- 打乱顺序
- resize by appending
- 用其他种子的一块插入/替换
5.2.4 Dictionary-based Mutation
AFL, honggfuzz, Libfuzzer都有0, -1, 1作为预设值
Radamsa: 用Unicode String
GPF: %x, %s一类的formatting char
5.3 Whitebox-based Fuzzers
白盒fuzzers也可以分为model-based或者modelless,也有[91][179][129]会借助input models,比如语法,来指导符号执行。
我们故意遗漏了[92][198][63][49][218][54]。
5.3.1 Dynamic Symbolic Execution
对每条程序路径,symbolic interpreter会建立一个path formula(path predicate),这个path formula可以用SMT solver来尝试得到可行解。
dynamic symbolic execution(concolic testing(concrete + symbolic))
具体执行数据往往可以用来减少约束求解的复杂度,比如用灰盒fuzzing找到重要的程序part。
- Driller, Cyberdyne: 具体执行和白盒符号执行切换
- QSYM: 通过a fast concolic execution engine来更好地结合灰盒,白盒
- DigFuzz: 用灰盒测试确定每个分支执行概率
5.3.2 Guided Fuzzing
通常分两个阶段:
-
a costly program analysis for obtaining useful information about the PUT
-
test case generation with the guidance from the analysis
-
TaintScope: 使用精细化taint analysis来找到和关键系统调用/API调用有关的hot bytes
-
Dowser: 在编译时就会执行静态分析确定可能会包含bugs的loops(具体说来是找有解引用操作的loops),然后使用taint analysis计算输入中的bytes和这些loops之间的关系,最后使用动态符号执行,只把和这些loop有关的critical bytes作为symbol相关的,以此增进性能。
-
VUzzer, GRT: 动静态分析结合,控制流数据流结合
-
Angora, Redqueen: 先运行一次全面昂贵的插桩,运行seeds之后收集信息优化插桩
-
Angora: 使用taint analysis将每个path constraint与特定bytes的关联找出来,然后用梯度下降类似的搜索来引导变异朝向解决这些constaints的方向进行
-
RedQueen: 尝试对全部比较都插桩,推测输入在程序中是怎么用的,寻找操作数和输入之间的关联,用此来解决限制
5.3.3 PUT Mutation
对目标程序本身变异
- TaintScope: 通过taint analysis找到checksum test intruction,然后修改待测程序,直接绕过去。当找到crash之后,再试着用带正确checksum的输入来使得未修改的目标程序崩溃。
- stitched dynamic symbolic execution: 在有checksum的情况下能够生成test cases
- T-Fuzz: 高效penetrate各种条件分支
- 找到能够被修改掉但是不会影响程序逻辑的branches,称其为Non-Critical Checks(NCCs)
- 当停止找到新paths的时候,程序会找到一个NCC,在目标程序中transforms it
- 对被修改后的程序再执行测试,如果发生崩溃,用符号执行去跑原版PUT。
6 Input Evaluation
6.1 Bug Oracles
最基本的策略是检测Fatal Signal,该策略能够检测到许多memory vulnerablities,但是也会遗漏一些不致命的,比如: stackbufferoverflow导致一块仍然valid的内存地址被写。
As a mitigation, researchers have proposed a variety of efficient program transformations to detect unsafe or unwanted program behaviors and abort the program. These are often called sanitizers.
6.1.1 Memory and Type Safety
Memory safety errors可以被分为两类: spatial and temporal.
空间内存错误一般发生在指针指向不希望指向的地方时。e.g: buffer overflows and underflows
时间内存错误一般发生在指针在解引用时已经无效。e.g: use-after-free
- ASan: 快速的memory error detector。在编译时插桩,然后维护一个shadow memory,每当一块内存要被解引用的时候就去做有效性检查
- MEDS: 维护objects之间或者内部不可以访问的memory red zones,如果被访问了,那很可能时memory crahs
- SoftBounds/CETS: 为每个pointer都结合bounds和时间信息,这样就从理论上能够探测到所有的内存问题
- CaVer, TypeScan, HexType等: 检查c++的bad-casting,object被cast into一个不兼容的type,例如基类被cast为衍生类
- Control Flow Integrity: 检测运行时原本不应当出现的control flow transition,这样就能找到不合法地篡改了程序本身的test case
6.1.2 Undefined Behaviors
C语言一类的编程语言有的时候会留下未定义行为。有时程序在不同编译器或者平台上的行为会产生不一致,可能会产生bugs
- Memory Sanitizer: 用于检测C和C++中使用未初始化memory的行为
- Undefined Behavior Sanitizer: 在编译时修改程序,以此检测未定义行为,比如misaligned pointers, 除0,解引用空指针,整数overflows
- Thread Sanitizer: compile time modification,检测data races。
6.1.3 Input Validation
- KameleonFuzz: 用真实的web browser来检测XSS attacks
- μ4SQLi: 用浏览器检测SQL injections,用db proxy来检测是否确实是有害行为。(Since it is not possible to reliably detect SQL injections from a web application response, μ4SQLi uses )
6.1.4 Semantic Difference
black box differential fuzz testing
6.2 Execution Optimizations
重启是有代价的
AFL使用forkserver
Xu等提出了fork()的替代函数
6.3 Triage
7 Configuration Updating
7.1 Evolutionary Seed Pool Update
A common strategy in EA fuzzers is to refine the fitness function so that it can detect more subtle and granular indicators of improvements.
- AFL通过让fitness function考虑某个branch被覆盖的次数来增进效果
- STADS:提出一个受到经济学方法启发的统计学框架来估计如果继续fuzz还能找到多少conf
- LibFuzzer, honggfuzz, go-fuzz, Steelix: 都会对复杂条件中的每个比较都插桩。
- Steelix: 检查哪个input offsets会影响比较指令
- Angora: 考虑每个branch的calling context
- DeepXplore: 使用neuron coverage作为fitness function来测神经网络
- VUzzer: 其fitness function依赖于每个基本块的权重,而这个权重是由一次程序分析确定的。
- 使用程序分析将基本块分为正常(normal)或者异常处理块(EH)
- normal basic blocks的权重是CFG上随机游走到达它的概率的倒数
- EH blocks的权重是负的,This assumes that traversing an EH block signals a lower change of exercising a vulnerability since bugs often coincide with unhandled errors.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号