

四、磁盘及文件系统
一、 磁盘
1.固态硬盘
SLC 贵 寿命长
MLC 中等
TLC 寿命短
2.机械硬盘分为盘片,磁道,磁柱
扇区:512 字节
二、 分区表
MBR:整个硬盘的第一个扇区,它非常的重要(512B)
446B:操作系统的内核-----------启动加载器--------第一阶段
64B:分区表------逻辑上把一个硬盘分割出几个区域
从哪-------->到哪 第一个分区
从哪-------->到哪 第二个分区
一个分区信息占用 16 字节,用于记录该分区的起始位置。结束位置、分区标识符
(64/16=4)所以一块硬盘只能分 4 个区,分区信息在 mbr 中叫主分区
2B:校验码
三、 fdisk
fdisk 分区:
m 帮助信息
n 新建分区
d 删除分区
p print 打印分区表
w 保存分区表
q 退出不保存
t 更改分区标识符
四、 磁盘附加
lsblk 查看硬盘
第一块硬盘起始位 2048 为 4K 对齐 扩展分区 不存放信息存放分区
主分区:把分区写在 MBR 中的分区
逻辑分区:模拟出来的分区
1.一块硬盘最多可以创建 4 个主分区 或 3 个主分区(primary)+扩展分区(extended)
2.扩展分区不能存储数据 扩展分区是用来存储分区(逻辑分区 logical)
3.主分区用于存储启动过程中需要使用的重要文件。
逻辑分区当成数据仓库
分区方案 1.BIOS+MBR
2.UEFI+GPT
重新加载分区表
简单的开机过程
开机自检 BIOS--------操作系统内核出场--------加载硬盘设备-------加载分区表--------能够正常使用分区
使用 fdisk 的过程
fdisk-----w(把分区表写回到 MBR 当中)---------使用命令重新加载分区表
使用命令重新加载分区表:是把刚才写入到 MBR 中的分区表导入到内存中,这样内核才能读取该分区表,识别新的分区,或者重新启动你的系统
<RHEL6----partprobe 磁盘设备标识符 如 partprobe /dev/sdb
RHEL6------partx -a 硬盘设备标识符 partx -a /dev/sdb
RHEL7------partprobe 磁盘设备标识符
五、 文件系统
什么是文件系统:
分区是在磁盘上逻辑的划分出来一些区域
磁盘:是真实存在的事物还是虚拟的 答:真实存在的
文件:文件是真实存在的还是虚拟的 答:虚拟的
磁盘----------文件系统-----------------文件
1.文件系统是连接物理磁盘和虚拟的文件间的载体
2.假设 整个楼层就是一块新的硬盘、
分割出来房间:分区
文件:我们学生
请问什么是文件系统 桌椅板凳
文件系统中的重要概念 :
文件系统是分区为单位
1.超级块(superblock):一个分区中的第一个区块,用于记录该分区的信息 如:分区大小、分区位置、分区上文件的索引位置
2 索引节点:一个文件必须使用一个索引节点,用于记录该文件信息;如:文件大小 创建日期、属于谁、实际上存储在硬盘的哪些区块上、文件权限等
对 sdb1 创建 ext4 的文件系统 mkfs -t ext4 /dev/sdb1
查看文件系统 tune2fs -l /dev/sdb1
ext(extend)
ext2 非日志文件系统
ext3=ext2+日志区块 速度比 ext2 慢,意外断电,文件就可以恢复
ext4 原生的日志文件系统

创建ext文件系统


六、tun2fs

七、 ext 特性
保留区块 我的系统不怕内存不够用 因为有交换内存 不怕 CPU 不够用 因为有队列机制
系统怕什么?磁盘空间不够用 why?用户登陆进去 和应用程序都需要产生临时文件 如果磁盘空间不够用 用户没办法登录。应用程序无法运行。所以 EXT 默认给 root 用户在每个文件系统保留一定的空间用于排错,叫保留区块:只允许 root 用户使用。
fdisk 分区、ext 文件系统、创建 ext、查看 ext 文件系统下的 superblock、调整 ext 的参数
fdisk 分区优缺点
优点 简单 交互式
缺点 不能写脚本
八、 parted 分区
交互式
命令模式 parted /dev/sdb mkpart primary 100M 200M 创建分区
parted /dev/sdb mklabel gpt(msdos) yes 设置磁盘格式
parted /dev/sdb print 打印输出分区信息
九、 实验
//对/dev/sdb1 创建 ext4 的文件系统,在创建时指定数据区块为 2K,索引节点大小为 256B(默认为 128B)索引节点为 200 个保留区块占数据区块的百分之 30,卷标名称为 test-vol
#mkfs.ext4 -b 2048 -I 256 -N 200 -M 30 -L test-vol /dev/sdb1
//查看/dev/sdb1 超级块的信息
#tune2fs -l /dev/sdb1
//检验索引节点个数
[root@localhost ~]# tune2fs -l /dev/sdb1 |grep -i "free inodes"
Free inodes: 205
[root@localhost ~]#mkdir test
[root@localhost ~]# mount /dev/sdb1 test
[root@localhost ~]# cd test
[root@localhost ~]# touch file{1..500}
[root@localhost 1]# ls -l file* |wc -l
205
[root@localhost ~]# umount /dev/sdb1
[root@localhost ~]# mount /dev/sdb1 test
[root@localhost ~]# tune2fs -l /dev/sdb1 | grep -i "Free inodes"
Free inodes: 0
//使用卷标的方式挂载磁盘
[root@localhost ~]# mount -L test-vol /tmp/test/ ---------1
[root@localhost ~]# mount /dev/sdb1 /tmp/test/ -----------2
[root@localhost ~]# umount /tmp/test/
[root@localhost ~]# mount LABEL=test-vol /tmp/test/ ----3
//更改最大挂载次数
[root@localhost ~]# tune2fs -l /dev/sdb1 | grep -i "mount count"
Mount count: 4
Maximum mount count: -1
[root@localhost ~]# tune2fs -c 10 -C 9 /dev/sdb1 //设置最大挂载次数 10 次 已经挂载次数为 9 次
tune2fs 1.42.9 (28-Dec-2013)
Setting maximal mount count to 10
Setting current mount count to 9
[root@localhost ~]# mount LABEL=test-vol /tmp/test/
[root@localhost ~]# umount /tmp/test/
[root@localhost ~]# mount LABEL=test-vol /tmp/test/
[root@localhost ~]# umount /tmp/test/
[root@localhost ~]# mount LABEL=test-vol /tmp/test/
[root@localhost ~]# umount /tmp/test/
[root@localhost ~]# tune2fs -l /dev/sdb1 | grep -i "mount count"
Mount count: 11
Maximum mount count: 10
[root@localhost ~]# e2fsck /dev/sdb1 //磁盘检查
e2fsck 1.42.9 (28-Dec-2013)
test-vol has been mounted 11 times without being checked, 强制检查.
第一步: 检查 inode,块,和大小
第二步: 检查目录结构
第三步: 检查目录连接性
第四步: Checking reference counts
第五步: 检查簇概要信息
test-vol: 216/216 files (0.5% non-contiguous), 4335/49152 blocks
[root@localhost ~]# tune2fs -l /dev/sdb1 | grep -i "mount count"
Mount count: 0
Maximum mount count: 10
以上每挂载一次 mount count 数值+1,当指定 e2fck 后 mount count 清零 e2fsck 做磁盘检查。
十、 ext 文件系统的调整
/dev/sdb 分区大小为 200M 但是只创建 100M 的文件系统
[root@666 ~]# mkdir /tmp/sdb3
[root@666 ~]# mkfs.ext4 /dev/sdb1 100M
[root@666 ~]# mount /dev/sdb1 /tmp/sdb3/
[root@666 ~]# df -lh |grep sdb
/dev/sdb1 93M 1.6M 85M 2% /tmp/sdb3
想要创建 100M 的文件系统,结果只显示 93M
创建文件系统:mkfs.ext4 /dev/sdb3 100M //使用 1000 进制
dh -lh 显示 1024 进制
为什么已经使用了 1.6M?
超级块和索引节点占用
为什么显示可用空间为 85M
保留区块占用
调整 ext 文件系统大小(resize2fs)
在线放大:最大不可以超过分区大小,不需要卸载文件系统
离线缩小:最小不能小于已经占用的超级块和索引节点占用空间大小(慎用!!!)
必须先卸载掉,然后做文件系统查看后才能缩小
在线和离线是什么意思?
已经挂载了某个位置称在线。
增大到 150M
[root@666 ~]# resize2fs /dev/sdb1 150M
resize2fs 1.42.9 (28-Dec-2013)
Filesystem at /dev/sdb1 is mounted on /tmp/sdb3; on-line resizing required
old_desc_blocks = 1, new_desc_blocks = 2
The filesystem on /dev/sdb1 is now 153600 blocks long.
[root@666 ~]# df -lh |grep sdb
/dev/sdb1 142M 1.6M 132M 2% /tmp/sdb3
放大到 200M
[root@666 ~]# resize2fs /dev/sdb1 200M
resize2fs 1.42.9 (28-Dec-2013)
Filesystem at /dev/sdb1 is mounted on /tmp/sdb3; on-line resizing required
old_desc_blocks = 2, new_desc_blocks = 2
The filesystem on /dev/sdb1 is now 204800 blocks long.
[root@666 ~]# df -lh |grep sdb
/dev/sdb1 190M 1.6M 178M 1% /tmp/sdb3
缩小到 150M
[root@666 ~]# umount /dev/sdb1
[root@666 ~]# e2fsck -f /dev/sdb1
e2fsck 1.42.9 (28-Dec-2013)
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Pass 5: Checking group summary information
/dev/sdb1: 11/49400 files (9.1% non-contiguous), 11884/204800 blocks
[root@666 ~]# resize2fs /dev/sdb1 150M
resize2fs 1.42.9 (28-Dec-2013)
Resizing the filesystem on /dev/sdb1 to 153600 (1k) blocks.
The filesystem on /dev/sdb1 is now 153600 blocks long
df -lh 是查看当前挂载上的文件系统上的使用大小
ext 系统升级与降级(ext2<----->ext3)
ext1 文件系统已经不支持了
ext2+日志=ext3--------------------ext2 和 ext3 无损过度
[root@666 ~]# mkfs.ext2 /dev/sdb2 //创建文件系统
[root@666n ~]# tune2fs -l /dev/sdb2 // 检查文件系统
[root@666 ~]# tune2fs -l /dev/sdb2 | grep -i ournal //查看日志(无输出)
[root@666 ~]# tune2fs -j /dev/sdb2 //升级文件系统 ext2------>ext3
tune2fs 1.42.9 (28-Dec-2013)
Creating journal inode: done //创建日志区块完成
[root@666 ~]# tune2fs -l /dev/sdb2 | grep -i journal
Filesystem features: has_journal ext_attr resize_inode dir_index filetype sparse_super
Journal inode: 8
Journal backup: inode blocks
[root@666 ~]# tune2fs -O ^has_journal /dev/sdb2 //去除日志功能 达到 ext3---->ext2
tune2fs 1.42.9 (28-Dec-2013)
[root@666 ~]# tune2fs -l /dev/sdb2 | grep -i journal //查看
Journal backup: inode blocks
查看以上特性 已经没有日志功能了
[root@666 ~]# tune2fs -O has_journal /dev/sdb2 //恢复 has_journal 特性
tune2fs 1.42.9 (28-Dec-2013)
Creating journal inode: done
[root@666 ~]# tune2fs -l /dev/sdb2 | grep -i journal
Filesystem features: has_journal ext_attr resize_inode dir_index filetype sparse_super
Journal inode: 8
Journal backup: inode blocks
查看以上特性 日志功能已经找回 恢复了 ext3 的特性
ext 系统升级(ext3----->ext4)
只是模拟 ext4 的特性,不是原生升级。要想原生升级方案:还要进行创建文件系统(mkfs.ext4)
[root@666 ~]# tune2fs -O /dev/sdb2
tune2fs 1.42.9 (28-Dec-2013)
[root@666 ~]# tune2fs -l /dev/sdb2 | grep -i features
Filesystem features: has_journal ext_attr resize_inode dir_index filetype extent sparse_super uninit_bg
[root@666 ~]# mount /dev/sdb2 /tmp/wushengmin/
[root@666 ~]# mount | grep sdb
/dev/sdb1 on /tmp/sdb3 type ext4 (rw,relatime,seclabel,data=ordered)
/dev/sdb2 on /tmp/wushengmin type ext4 (rw,relatime,seclabel,data=ordered)
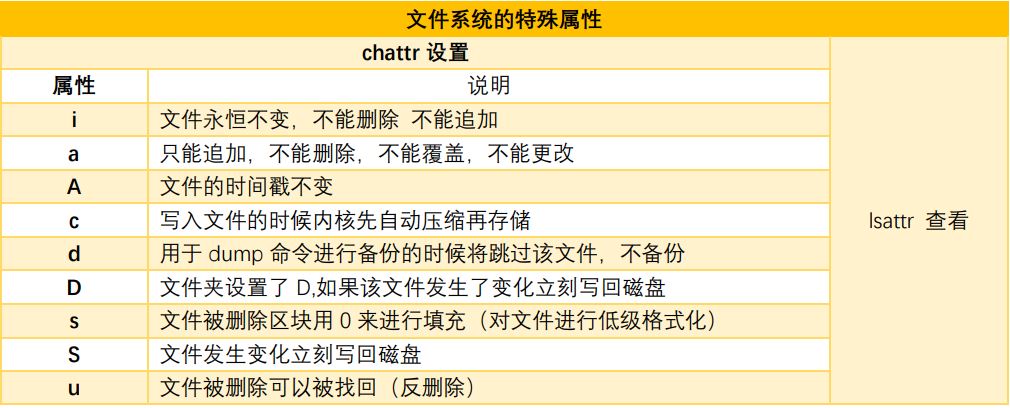
文件系统层级:文件系统的 features > mount 的时候挂载的指定参数 > 文件系统的特殊属性(chatter)> 强制位(suid) ,冒险位(sgid),黏贴位 > root > rwx > setfacl
十一、 xfs
xfs 相关常用命令
xfs_admin: 调整 xfs 文件系统的各种参数
xfs_copy: 拷贝 xfs 文件系统的内容到一个或多个目标系统(并行方式)
xfs_db: 调试或检测 xfs 文件系统(查看文件系统碎片等)
xfs_check: 检测 xfs 文件系统的完整性
xfs_bmap: 查看一个文件的块映射
xfs_repair: 尝试修复受损的 xfs 文件系统
xfs_fsr: 碎片整理
xfs_quota: 管理 xfs 文件系统的磁盘配额
xfs_metadump: 将 xfs 文件系统的元数据 (metadata) 拷贝到一个文件中
xfs_mdrestore: 从一个文件中将元数据 (metadata) 恢复到 xfs 文件系统
xfs_growfs: 调整一个 xfs 文件系统大小(只能扩展)
xfs_freeze 暂停(-f)和恢复(-u)xfs 文件系统
xfs_logprint: 打印 xfs 文件系统的日志
xfs_mkfile: 创建 xfs 文件系统
xfs_info: 查询文件系统详细信息
xfs_ncheck: generate pathnames from i-numbers for XFS
xfs_rtcp: XFS 实时拷贝命令
1.根据所记录的日志在很短的时间内迅速恢复磁盘文件内容
2.采用优化算法,日志记录对整体文件操作影响非常小
3.是一个全 64 比特的文件系统,支持上百 T 字节的存储空间
4.能接近裸设备 I/O 的性能存储数据
xfs 系统特性 :
系统完整性:当意外宕机时由于文件系统启动了日志功能,根据你的日志恢复文件
传输特性:采用优化算法 日志记录对系统影响非常小 查询和分配资源特别快
可扩展性:全 64byte 的系统 可以支持上百个 T 字节的存储
传输宽带:xfs 能接近裸设备 I/O 文件测试可以达到 7GB/S 单个文件的读写可达到 4GB/S
xfs_info /dev/sda1 查看 boot 的信息
十二、 磁盘配额
1.独立的文件系统
2.磁盘配额基于用户和组
3.区块的磁盘配额、索引节点的磁盘配额
4.磁盘配额有软性限制和硬性限制
磁盘配额能干什么
jack 在某个文件系统上只能使用 100M 空间,创建 20 个文件
game 组中的所有用户在某个系统上可以加一起使用 200M 创建 100 个文件
http://docs.redhat.com 红帽官方文档
1) xfs 磁盘配额实验:
开发一部 dep1 有三个用户:simon jack marry
开发一部所有用户只能写入 100M 文件,所有用户加起来之能创建 100 个文件
实验前期准备:
[root@666 tmp]#groupadd dep1
[root@666 tmp]#gpasswd -a jack dep1
[root@666 tmp]# useradd simon
[root@666 tmp]#gpasswd -a simon dep1
[root@666 tmp]#useradd marry
[root@666 tmp]#gpasswd -a marry dep1
[root@666 tmp]# chown .dep1 /tmp/xfs-test1/ -R
[root@666 tmp]# chmod 2770 /tmp/xfs-test1/
1.添加磁盘配额挂载参数:
编辑/etc/fstab
UUID="5d6d6b2f-b14d-4ba4-b86a-ca0271962479" /tmp/xfs-test1 xfs defaults,usrquota,grpquota 0 0
[root@666 tmp]#mount -o remount /dev/sdb3
[root@666 tmp]# mount |grep sdb
/dev/sdb3 on /tmp/xfs-test1 type xfs (rw,relatime,seclabel,attr2,inode64,usrquota,grpquota)
确保两个挂载参数生效
2.设置磁盘配额
[root@666 tmp]# xfs_quota -x -c 'limit -g bsoft=80M bhard=100M dep1' /tmp/xfs-test1/
[root@666 tmp]# xfs_quota -x -c 'limit -g isoft=80 ihard=100 dep1' /tmp/xfs-test1/
3.查看磁盘配额信息
[root@666 tmp]# xfs_quota -x -c 'report -ig' /tmp/xfs-test1/
Group quota on /tmp/xfs-test1 (/dev/sdb3)
Inodes
Group ID Used Soft Hard Warn/ Grace
---------- --------------------------------------------------
root 2 0 0 00 [--------]
dep1 1 80 100 00 [--------]
[root@666 tmp]# xfs_quota -x -c 'report -hg' /tmp/xfs-test1/
Group quota on /tmp/xfs-test1 (/dev/sdb3)
Blocks
Group ID Used Soft Hard Warn/Grace
---------- ---------------------------------
root 0 0 0 00 [------]
dep1 0 80M 100M 00 [------]
测试:三个用户无论谁在里面创建文件最终总和不超过 100
2) ext 系统文件配额
ext 系统文件配额(/dev/sdb5 ext3)
[root@666 xfs-test1]# mkdir /tmp/quota
[root@666 xfs-test1]# echo "/dev/sdb5 /tmp/quota ext3 defaults 0 0" >> /etc/fstab
[root@666 xfs-test1]# mount -a
[root@666 xfs-test1]# cat /etc/fstab
[root@666 xfs-test1]# chmod 777 /tmp/quota/
1.使用 usrquota,grpquota 重新挂载
[root@666 tmp]# mount -o remount,usrquota,grpquota /dev/sdb5
[root@666 tmp]# mount |grep sdb5
/dev/sdb5 on /tmp/quota type ext3 (rw,relatime,seclabel,quota,usrquota,grpquota,data=ordered)
2.生产磁盘配额数据库
[root@666 tmp]# quotacheck -cug /dev/sdb5
[root@666 tmp]# cd /tmp/quota/
[root@666 quota]# ls
aquota.group aquota.user lost+found
看到以上两个文件代表磁盘配额数据库创建成功!
3.打开磁盘配额功能:
[root@666 quota]# quotaon -ug /dev/sdb5
4.编辑磁盘配额数据库
[root@666 quota]# edquota -u jack
Disk quotas for user jack (uid 1005):
Filesystem blocks soft hard inodes soft hard
/dev/sdb5 0 100000 120000 0 30 50
以上代表区块软性限制为 100M 硬性限制为 120M 索引节点软性限制为 30 个硬性限制为 50 个
测试
[jack@666 quota]$ touch file{1..100}
sdb5: warning, user file quota exceeded.
sdb5: write failed, user file limit reached.
touch: cannot touch ‘file51’: Disk quota exceeded
touch: cannot touch ‘file52’: Disk quota exceeded
......
touch: cannot touch ‘file98’: Disk quota exceeded
touch: cannot touch ‘file99’: Disk quota exceeded
touch: cannot touch ‘file100’: Disk quota exceeded
[jack@666 quota]$ ls
aquota.group file13 file19 file24 file3 file35 file40 file46 file6
aquota.user file14 file2 file25 file30 file36 file41 file47 file7
file1 file15 file20 file26 file31 file37 file42 file48 file8
file10 file16 file21 file27 file32 file38 file43 file49 file9
file11 file17 file22 file28 file33 file39 file44 file5 lost+found
file12 file18 file23 file29 file34 file4 file45 file50
[jack@666 quota]$ rm -f file*
[jack@666 quota]$ ls
aquota.group aquota.user lost+found
[jack@666 quota]$ dd if=/dev/zero of=tesk-jack bs=1M count=300
sdb5: warning, user block quota exceeded.
sdb5: write failed, user block limit reached.
sdb5: write failed, user block limit reached.
dd: error writing ‘tesk-jack’: Disk quota exceeded
117+0 records in
116+0 records out
122396672 bytes (122 MB) copied, 0.643885 s, 190 MB/s
[jack@666 quota]$ ls -lh
total 118M
-rw-------. 1 root root 7.0K Jan 5 17:00 aquota.group
-rw-------. 1 root root 7.0K Jan 5 17:00 aquota.user
drwx------. 2 root root 12K Jan 5 16:48 lost+found
-rw-rw-r--. 1 jack jack 117M Jan 5 17:14 tesk-jack


