RocketMQ学习笔记
消息系统三个作用
- 异步
- 削峰、填谷
- 解耦
RocketMQ的组成
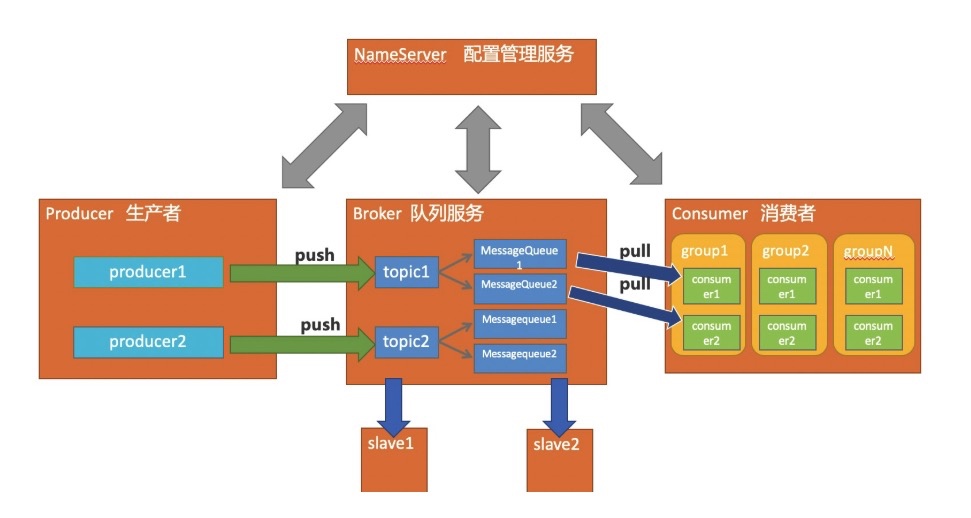
- nameServer
- Consumer
- Producer
- Broker
NameServer
NameServer是什么?
本质上讲,NameServer是本质上它是一个轻量级元数据管理服务器。
从功能上讲,NameServer在收集,维护集群中所有机器的配置、状态等信息。
NameServer工作原理
- NameServer中有五个Map,分别存储了Topic,Broker,Cluster等信息
- 集群中所有的机器都会定时向NameServer发送请求,如果超时,那么被认为不可以用。 为什么不用Zookeeper
- Zookeeper功能强大,RocketMQ不需要使用到这么多的功能。例如:包括Master选举,RocketMQ的架构决定了它不需要Master选举。多个NameServer是相互独立,无状态的。
- 相对于Zookeeper这样的一个中间件,NameServer更加轻量级,维护成本低
Consumer
RocketMQ中Consumer可以分为两种pullConsumer和pushConsumer。
pushConsumer代码更加高度自动化,只需要填入少量参数即可使用。相对于PushConsumer,PullConsumer更加偏向底层,很多逻辑需要自己实现,例如message-queue的选择,offset保存提交。所以一般使用PushConsumer。
PushConsumer
PushConsumer虽然名字叫push,但是本质上也是pull。即,客户的端主动轮询拉取,不同的是RocketMQ中的PushConusmer使用了一种叫”长轮询“的方式。
长轮询:
“长轮询”的思路是Broker Holder住Consumer的请求一小段时间(默认是15秒),在这一小段时间内,如果有新的消息达到则立即返回给Consumer。
这样避免了如果拉取时间太短,“忙碌等待”浪费资源,和拉取间隔时间太长消息获取不及时的问题。
流量控制:
RocketMQ中每一个MessageQueue都有一个快照类,叫做ProcessQueue。
ProcessQueue中的有一个TreeMap和一个读写锁。
TreeMap里,以MessageQueue的offset作为KEY,消息内容的引用作为VALUE,保存了所有MessageQueue获取到但还没有被处理的消息;读写锁控制着多个线程对TreeMap对象的并发访问。
这样,为处理消、、息的个数,消息总大小超过阈值就隔一段时间在拉取消息,从而达到流量控制的目的。
此外,ProcessQueue还可以辅助实现顺序消费的逻辑
启动:
PushConsumer在启动时候,会做各种检查,然后连接到NameServer获取信息,启动时如果遇到异常,比如无法连接NameServer,程序会正常启动不报错(日志只有WARN信息)。
为什么程序启动无法连接nameServer程序不抛异常呢,这和分布式系统设计有关,RoketMQ集群可以有多个NameServer、Broker某个机器异常后整体服务依然可用。
如果需要Consumer在启动时就暴露配置问题,那么需要在consumer.start()语句后调用:Consumer.fetchSubscribeMessageQueues("TopicName"),这时如果配置信息填写错误,当前服务不可用,这个语句会报MQClientException
使用方法:
使用PushConsumer只需传入各种参数,和处理消息的函数,系统在接收到消息后会自动调用函数处理消息,保持Offset。
PushConsumer主要以三个参数:
- GroupName: 把多个Consumer组织在一起,提高并发的能力。
GroupName需要和MessageModel配合使用,RocketMQ中有两种MessageModel- Clustering:同一个ConsumerGroup里的每一个Consumer只消费订阅所有消息的一部分,同一个ConsumerGroup里所有的Conusmer消费合起来才是所订阅Topic的内容的全部,从而达到负载均衡的目的。
- Broadcasting: 同一个ConsumerGroup里的每一个Consumer都能消费到全部消息,也就是一个消息被分为多次分发给多个Consumer消费。
- NameServer: nameServer可以填写多个,用;隔开达到消除单点故障的目的,例如: “IP1:port;IP2:port;IP3:port”
- Topic: Topic名称用来标识消息类型,需要提前创建。 Topic的下还可以使用Tag来进行过滤。例如: Consumer.subscribe("TopicTest","tag1||tag2||tag3"), 在填写Tag参数的位置,用null或者* 表示消费这个Topci的所有消息
PullConsumer
Producer:
按照不同的业务场景,可以使用同步发送、异步发送、延迟发送、发送事务消息。
延迟消息:
Rocket收到消息后延迟一段时间再处理,使消息在一段时间后生效
创建延迟消息的办法是:Message.setDelayTimeLevel
自定义消息发送规则:
一个Topic会有多个Message-queue,默认情况下,Producer会轮询发送到各个Message—queue,Consumer根据负载均衡策略消费被分配到的Message-Queue。
如果业务需要把同一类型的Message发送到Message-Queue中,那么需要使用MessageQueueSelector
事务消息:
RocketMQ的事务消息可以让业务实现分布式二阶段提交,达到最终一致性。
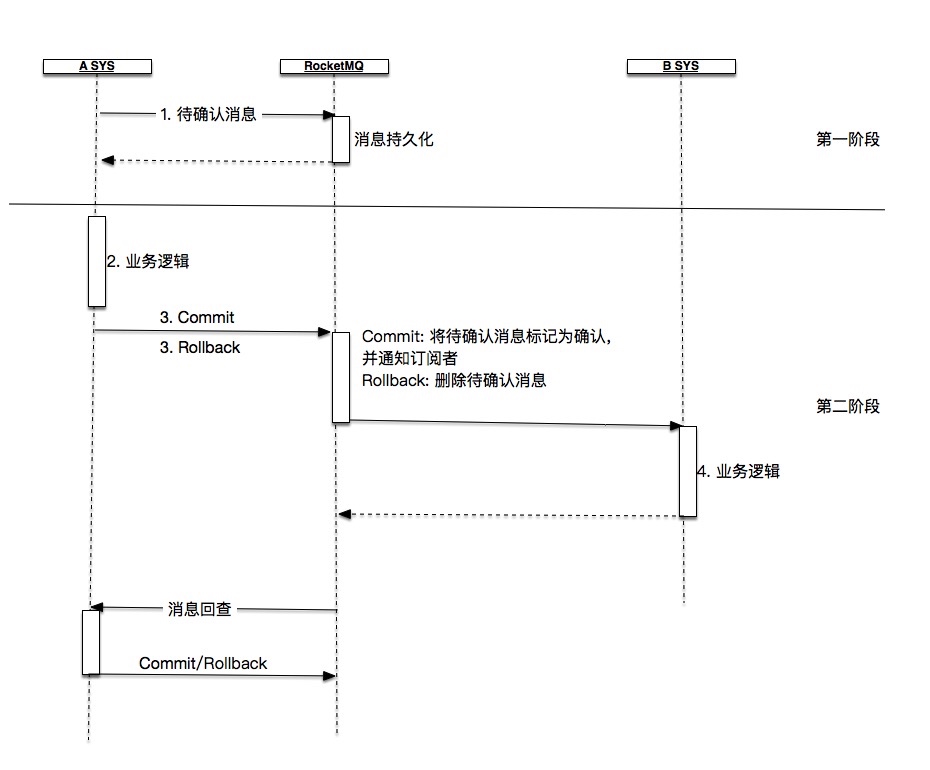
举例说明:A系统向B系统转账1W元
- A向RocketMQ发送一个消息(待确认)。
- 消息发送成功后,A执行业务逻辑,减款1W元。
- 如果业务逻辑执行成功/失败,发送Commit/Rollback消息
- RocketMQ将收到Rollback后,将“待确认”消息删除。收到Commit消息后,将“待确认”消息标记为"待发送"。
- B将收到订阅的消息,并执行业务逻辑。
- 如果步骤3出现异常,消息没有正确发送到RocketMQ,服务器经过固定时间段后将对待确认消息发起回查,并返回给A。A将根据业务再次判断是否执行Commmit或者Rollback
Broker
Broker是RocketMQ的核心,大部分“重量级”工作都是基于Broker来完成的,包括接收producer发过来的消息,处理Consumer的消费消息请求,消息持久化存储,消息的HA机制以及服务器端过滤功能。
消息存储和发送
- 顺序写,随机读与“零拷贝”规避了的磁盘的瓶颈
#### 消息存储结构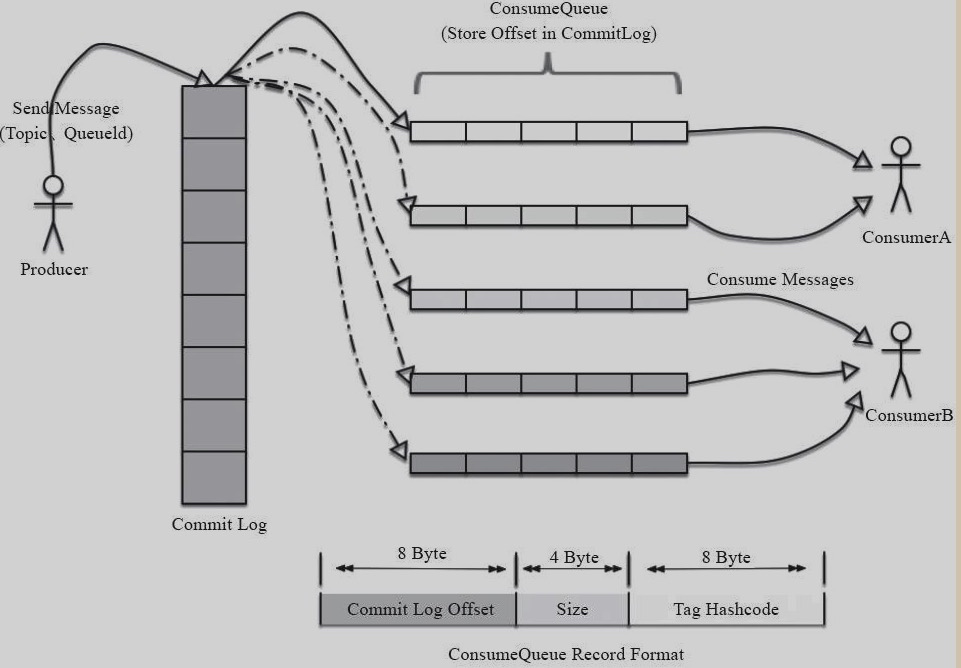 RocketMQ的消息存储主要数据结构有两个,
RocketMQ的消息存储主要数据结构有两个,ConsumeQueue和ConsumeLogConsumeLog: 消息存储物理文件 ConsumeQueue: - 每一个Topic下的每一个MessageQueue都有一个ConsumeQueue
- 消息存储的逻辑队列,相当于是索引的作用,队列中存储了每条消息指向ConsumeLog的物理地址
- ConsumeQueue中每一个记录存储了ConsumeLog的offet,大小,和Tag。 由于可知,每次取消息的时候回从ConsumeQueue获取消息的物理地址,再从CommitLog中取出数据
Broker的HA机制
- RocketMQ的HA是通过Master,Slave实现的。
- Consumer不需要配置指定具体的Master,Slave, 当某个节点不可读时,程序会自动切换到其他节点,而且当Master不可用用时,程序还可以继续读Slave,这样保证了消费高可用
- 在创建Topic的时候,可以把Topic的Message Queue创建在多个Broker组上,每个Broker组会有一个Master,以此保证写的高可用
- RocketMQ暂时还不支持动态的Slave自动转Master,如果需要Slave转Master需要手动停机重启
刷盘机制
RocketMQ支持同步刷盘和异步刷盘两种方式
同步刷盘: 消息写入内存后,立即同步持久化
异步刷盘: 消息写入后立即返回,当内存中消息累计到一定量在触发写入
同步刷盘还是异步刷盘通过Broker配置文件中的flushDiskType参数配置,可以配置成SYNC_FLUSh或者ASYNC_FLUSH
同步复制和异步复制
同步复制和异步复制两种方式各有长短,异步复制方式下,系统拥有延迟低,高吞吐量,但是如果Master宕机,数据没有来得及同步到Slave,就会造成数据的丢失。
实际应用过程中应该实际的业务场景,合理设置刷盘方式和主从复制的方式,通常情况下应该吧Master和Salve配置成异步刷盘的方式,主从之间配置成同步复制,这样即使有一台机器故障,仍然可以保证数据不丢失。
消息优先级
有些场景,需要应用程序处理集中类型的消息,不同的消息的优先级不同。RocketMQ是一个先进先出的队列,不支持消息级别者或Topic级别的优先级,业务中简单的优先级需求,可以通过间接方式解决:
第一种情况:消息A大量产生,而且处理速度慢,导致消息B延迟被获取。可以单独给B创建一个Topic
第二种情况:强优先级需求,要求A优先B先处理, 可以手动实现pullConsumer控制MessageQueue的遍历
过滤
Tag过滤:
对于一个应用来说,通常使用是一个Topic,然后再根据不同的Tag来过滤各个Consumer需要的消息,因为ConsumerQueue中存储有Tag的hashcode所以不需要读取消息内容即可查询到需要的消息
Key过滤: 每个Message可以设置Key,Key一般是业务上的唯一标识,这样可以通过Key来查询单个消息的接收,发送情况,可以快速定位问题。RocketMQ会为KEY创建索引文件。
Tag和Key的区别是,Tag用于Consumer对Broker的消息过滤,Key用于查询某条消息
Filter Server过滤: FilterServer允许用户使用Java函数对消息进行过滤
要使用FilterServer首先需要启动Broker前在配置文件中加上FilterServer=3,Broker在启动的时候就会在本机启动3个FilterServer进程,然后FilterServer会消费用户发送的消息,并进行过滤,过滤后的消息将发送给Consumer。
使用这种方式要特别会占用Broker机器更多的CPU资源,上传的Java代码也应该检查,不能申请大内存,创建进程这样的情况,否则容易导致Broker宕机。
提高Consumer消费能力
提高消费并行度:
- 增加Consumer的实例数量,可以是增加机器,或者是Consumer的数量,或者是增加一个Consumer中的线程数,可以通过consumeThreadMin和consumeThreadMAX来设置。
- 但是式不能超过Topic下的Read Queue数量,否则超过也接收不到消息。 以批量方式消费: 某些场景下,单个消息逐条处理的速度,比不上批量处理的速度。例如说,收到到消息后执行SQL Update操作。 逐条执行Update不如批量Update更有效率 主动监测延时,跳过不重要重要的消息 可以在Consumer代码中主动监测消息堆积情况,跳过不重要的消息
posted on 2020-04-07 01:12 yipianlarou 阅读(375) 评论(0) 编辑 收藏 举报
