
pytorch实现VAE
一、VAE的具体结构
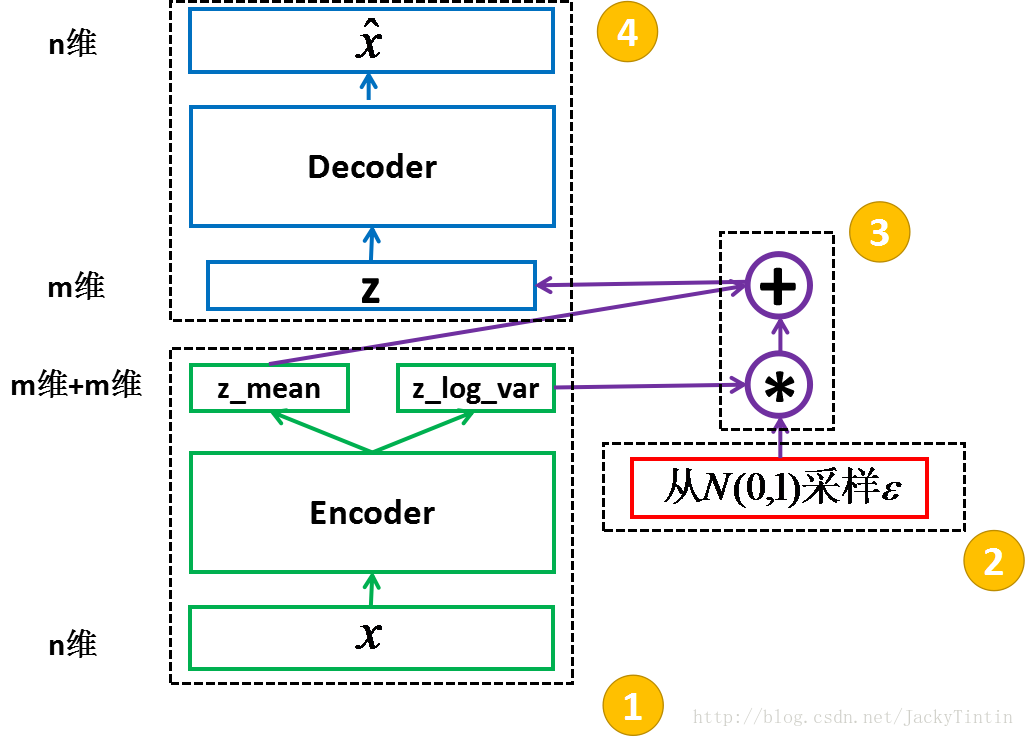
二、VAE的pytorch实现
1加载并规范化MNIST
import相关类:
from __future__ import print_function import argparse import torch import torch.utils.data import torch.nn as nn import torch.optim as optim from torch.autograd import Variable from torchvision import datasets, transforms
设置参数:
parser = argparse.ArgumentParser(description='PyTorch MNIST Example') parser.add_argument('--batch-size', type=int, default=128, metavar='N', help='input batch size for training (default: 128)') parser.add_argument('--epochs', type=int, default=10, metavar='N', help='number of epochs to train (default: 10)') parser.add_argument('--no-cuda', action='store_true', default=False, help='enables CUDA training') parser.add_argument('--seed', type=int, default=1, metavar='S', help='random seed (default: 1)') parser.add_argument('--log-interval', type=int, default=10, metavar='N', help='how many batches to wait before logging training status') args = parser.parse_args() args.cuda = not args.no_cuda and torch.cuda.is_available() print(args) #Sets the seed for generating random numbers. And returns a torch._C.Generator object. torch.manual_seed(args.seed) if args.cuda: torch.cuda.manual_seed(args.seed)
输出结果:
Namespace(batch_size=128, cuda=True, epochs=10, log_interval=10, no_cuda=False, seed=1)
下载数据集到./data/目录下:
kwargs = {'num_workers': 1, 'pin_memory': True} if args.cuda else {}
trainset = datasets.MNIST('../data', train=True, download=True,transform=transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(
trainset,
batch_size=args.batch_size, shuffle=True, **kwargs)
testset= datasets.MNIST('../data', train=False, transform=transforms.ToTensor())
test_loader = torch.utils.data.DataLoader(
testset,
batch_size=args.batch_size, shuffle=True, **kwargs)
image, label = trainset[0]
print(len(trainset))
print(image.size())
image, label = testset[0]
print(len(testset))
print(image.size())
输出结果:
60000 torch.Size([1, 28, 28]) 10000 torch.Size([1, 28, 28])
2定义VAE
首先我们介绍x.view方法:
x = torch.randn(4, 4)y = x.view(16)z = x.view(-1, 16) # the size -1 is inferred from other dimensions print(x)
print(y)
print(z)
输出结果:
1.6154 1.1792 0.6450 1.2078 -0.4741 1.2145 0.8381 2.3532 0.2070 -0.9054 0.9262 0.6758 1.2613 0.5196 -1.7125 -0.0519 [torch.FloatTensor of size 4x4] 1.6154 1.1792 0.6450 1.2078 -0.4741 1.2145 0.8381 2.3532 0.2070 -0.9054 0.9262 0.6758 1.2613 0.5196 -1.7125 -0.0519 [torch.FloatTensor of size 16] Columns 0 to 9 1.6154 1.1792 0.6450 1.2078 -0.4741 1.2145 0.8381 2.3532 0.2070 -0.9054 Columns 10 to 15 0.9262 0.6758 1.2613 0.5196 -1.7125 -0.0519 [torch.FloatTensor of size 1x16]
然后建立VAE模型
class VAE(nn.Module): def __init__(self): super(VAE, self).__init__() self.fc1 = nn.Linear(784, 400) self.fc21 = nn.Linear(400, 20) self.fc22 = nn.Linear(400, 20) self.fc3 = nn.Linear(20, 400) self.fc4 = nn.Linear(400, 784) self.relu = nn.ReLU() self.sigmoid = nn.Sigmoid() def encode(self, x): h1 = self.relu(self.fc1(x)) return self.fc21(h1), self.fc22(h1) def reparametrize(self, mu, logvar): std = logvar.mul(0.5).exp_() eps = Variable(std.data.new(std.size()).normal_()) return eps.mul(std).add_(mu) def decode(self, z): h3 = self.relu(self.fc3(z)) return self.sigmoid(self.fc4(h3)) def forward(self, x): mu, logvar = self.encode(x.view(-1, 784)) z = self.reparametrize(mu, logvar) return self.decode(z), mu, logvar model = VAE() if args.cuda: model.cuda()
3.定义一个损失函数
reconstruction_function = nn.BCELoss() reconstruction_function.size_average = False def loss_function(recon_x, x, mu, logvar): BCE = reconstruction_function(recon_x, x.view(-1, 784)) # see Appendix B from VAE paper: # Kingma and Welling. Auto-Encoding Variational Bayes. ICLR, 2014 # https://arxiv.org/abs/1312.6114 # 0.5 * sum(1 + log(sigma^2) - mu^2 - sigma^2) KLD_element = mu.pow(2).add_(logvar.exp()).mul_(-1).add_(1).add_(logvar) KLD = torch.sum(KLD_element).mul_(-0.5) return BCE + KLD optimizer = optim.Adam(model.parameters(), lr=1e-3)
4.在训练数据上训练神经网络
我们只需要对数据迭代器进行循环,并将输入反馈到网络并进行优化。
for epoch in range(1, args.epochs + 1): train(epoch) test(epoch)
其中
def train(epoch): model.train() train_loss = 0 for batch_idx, (data, _) in enumerate(train_loader): data = Variable(data) if args.cuda: data = data.cuda() optimizer.zero_grad() recon_batch, mu, logvar = model(data) loss = loss_function(recon_batch, data, mu, logvar) loss.backward() train_loss += loss.data[0] optimizer.step() if batch_idx % args.log_interval == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( epoch, batch_idx * len(data), len(train_loader.dataset), 100. * batch_idx / len(train_loader), loss.data[0] / len(data))) print('====> Epoch: {} Average loss: {:.4f}'.format( epoch, train_loss / len(train_loader.dataset))) def test(epoch): model.eval() test_loss = 0 for data, _ in test_loader: if args.cuda: data = data.cuda() data = Variable(data, volatile=True) recon_batch, mu, logvar = model(data) test_loss += loss_function(recon_batch, data, mu, logvar).data[0] test_loss /= len(test_loader.dataset) print('====> Test set loss: {:.4f}'.format(test_loss))
Tips:
1.直接运行pytorch examples里的代码发现library not initialized at /pytorch/torch/lib/THC/THCGeneral.c错误
解决方案:sudo rm -r ~/.nv
2.该源码实现的论文为https://arxiv.org/pdf/1312.6114.pdf

