

图像,矩阵以及鲁棒性笔记
1.黑白图像不是二维数据。图像的维度,实际上是图像中特征向量的数量。用向量数据化图像,想象按行扫描,遇到的每一个像素都是向量的一个元素,像素个数就是向量维数;例如二维图像矩阵表示为:256*256=65536,维数还是很高的。一个100x100像素的图像其灰度图产生的特征向量是10000维度,而1920x1080像素的图像则对应2073600维度的特征向量。
2.图像降维:降维算法中的”降维“,指的是降低特征矩阵中特征的数量。
假设一个矩阵 (大小为
,已经归一化), 那么可以得到一个
的协方差矩阵
。这是一个对称矩阵,特征向量正交。
因此应用SVD分解 。其中
是特征向量组成的矩阵(
),
是由特征值组成的对角矩阵。特征向量对应数据的主要方向。然后就是把数据投影到这个方向上来。那么投影后为
。
如果只取前 个特征值对应的特征向量,那么原本
(
)可以变成
(
),完成了降维。
2.假设我们要执行面部识别,即基于带有标记的面部图像训练数据集来确定人的身份。一个办法是把图像上每个像素的亮度作为特征。如果输入图像的大小是32×32,这意味着该特征向量包含1024个特征值。判断新的图像通过计算这1024维矢量与我们训练数据集中特征向量之间的欧氏距离完成。然后最小距离告诉我们正在寻找的那个人。
因为2D数据的特征向量是2维的,三维数据的特征向量是3维的,1024维数据的特征向量是1024维。换句话说,为了可视化,我们可以重塑每个1024维特征向量到一个32×32的图像。图10展示了由剑桥人脸数据集的特征分解获得的前四个特征向量:

每个1024维特征向量可以映射到N个最大的特征向量,并可以表示为这些特征脸的线性组合。这些线性组合的权重确定人的身份。因为最大特征向量表示数据中的最大方差,所以这些特征脸描述信息量最大的图像区域(眼睛,鼻子,嘴等)。只考虑前N(例如,N = 70)个特征向量,特征空间的维数大大减少了。剩下的问题是现在使用了多少个特征脸,或者在一般情况下,应保留多少个特征向量。
2.Certified Adversarial Robustness via Randomized Smoothing
代码地址: http://github.com/locuslab/smoothing.
定义: “smoothed” classifier g
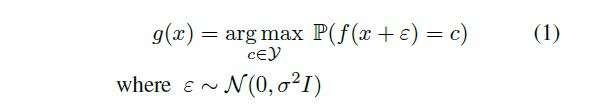
论文证明的结论
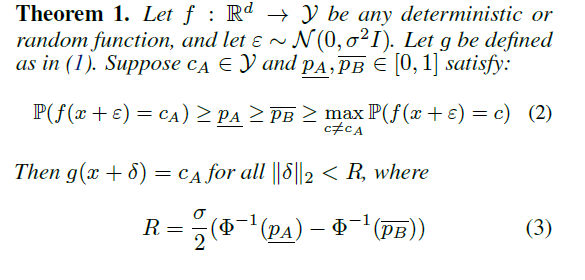


从任意分类器f得到g的方法:通过大量采样。

参考文献:
1.https://www.zhihu.com/question/270867521
2.https://www.jianshu.com/p/c1a9604db03b
3.https://cloud.tencent.com/developer/article/1030408
4.Jeremy M. Cohen, Elan Rosenfeld, J. Zico Kolter:Certified Adversarial Robustness via Randomized Smoothing. ICML 2019: 1310-1320
5.https://blog.csdn.net/emmaczw/article/details/78383115
6.https://blog.csdn.net/u010006643/article/details/46417127#


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架