
无痛机器学习之DCGAN的小尝试
主要内容来自对https://zhuanlan.zhihu.com/p/22386494以及https://zhuanlan.zhihu.com/p/22386494的整合
话说当今的深度学习网络框架世界,除了Caffe,还有很多不错的框架。这一次为了省事,我们直接找一个开源的应用进行分析和尝试。而这次的框架主角是keras,一个拥有简洁API的框架。
DCGAN
如果从GAN的起点开始聊起,那么等我们聊到正题,估计好几集都过去了。所以让我们忘掉前面的种种解法,直接来到我们的深度学习部分:DCGAN。全称是Deep Convolution GAN。也就是用深度卷积网络进行对抗生成网络的建模。
对抗神经网络(GAN)有两个主角——
- 一个是G(Generator),也就是生成模型;它的输入是一个随机生成的向量,长度不定,输出是一个具有一定大小的图像(N*N*3)和(N*N*1)。
- 一个是D(Discriminator),也就是判别模型。在我们接下来介绍的模型中,它的输入维度和G的输出一样,输出是一个长度为1 的向量,数字的范围从0到1,表示图像像一个正常图片的程度。
G的输入和输出都比较好理解,D的输入也比较好理解,那么D的输出是什么含义呢?它表示了对给定输出是否像我们给定的标准的输入数据。这句话可能有点绕口,我们可以把判别模型理解成一个解决分类问题的模型,那么在这个问题中判别模型的结果就是区分一个输入属于下面两个类别中的哪个——“正常输入”和“非正常输入”。
举个更具体的例子。对于MNIST数据集来说,每一个手写的数字都可以认为是一个“正常输入”,而随便生成的一个不像手写数字的输入都可以认为是一个“非正常输入”。而我们的判别模型就是要判断这个问题,我们学习的目标也是学习出一个能够解决这个问题的模型。
那么,我们的生成模型的目标呢?就是我们能够从一个随机生成的向量生成一样“正常输入”的图像。听上去有点神奇吧,不过现实中这个效果是可以实现的。我们可以想象我们的输入空间是满足某种分布的一个空间,对于空间中的每一个点,我们都可以利用生成模型将其映射成为一个图像,现在我们限定了生成的图像必须是“正常输入”,那么输入和输出在某种程度上已经确定,我们就可以用监督学习的方式进行学习了。不过对于生成模型来说,我们的loss是生成图像的likelihood,这个和判别模型的loss不太一样。
好了,两个模型的输入输出已经说完了,下面还有两个问题需要解决:
- 判别模型的训练数据该如何准备?正例可以用现有数据,那负例呢?
- 生成模型的loss该如何计算?
其实要想解决这两个问题,我们需要把两个模型连起来。因为生成模型和输出和判别模型的输入在维度和含义上都是相同的,这样连起来我们就可以解决上面的两个问题。我们利用判别模型去判断生成模型的likelihood,而用生成模型产生的结果去做判别模型的负例,这样就把上面的两个问题解决了。
当然,关于把生成模型的输出作负例这件事,听上去还是有点奇怪的。生成模型的目标是生成“正常输入”,那么生成了“正常输入”还被当成负例,也是够冤的。不过这种矛盾的关系在机器学习中经常存在,就像优化目标中的loss项和正则项一样,这两个目标往往也是一对矛盾体。所以这种矛盾的存在并不奇怪,这也是这个模型被称为“对抗”的原因。
大家都喜欢用警察和小偷的关系来比喻生成模型和判别模型之间的“对抗”关系,我觉得可以用“魔高一尺,道高一丈”,“道高一丈,魔高十丈”来解释两个模型随着对抗不断强化的关系。判别模型在进化中能够捕捉不像“正常输入”的所有细节,而生成模型则会尽全力地模仿判别模型心中“正常输入”的形象。
好了,说了这么多,我们来看看针对“Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks” 这篇论文的keras版“实现”:GitHub - jacobgil/keras-dcgan: Keras implementation of Deep Convolutional Generative Adversarial Networks,说是“实现”是因为这个实现实际上和论文中期望的有点小不同。
这个代码使用的数据集是MNIST,经典的小数据集,手写数字。在我的实验结果中,生成模型生成的手写数字是这样的:

除了个别数字之外,大多数的数字生成得还是有模有样的嘛!
另外我们看一下两个模型在训练过程中的Loss:
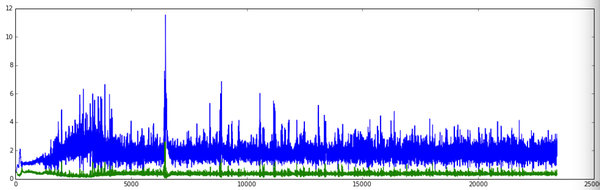 其中蓝色是生成模型的loss,绿色是判别模型的loss,可以看出两个模型的Loss都存在一定程度的抖动,也可以算是对抗过程中的此消彼长吧。
其中蓝色是生成模型的loss,绿色是判别模型的loss,可以看出两个模型的Loss都存在一定程度的抖动,也可以算是对抗过程中的此消彼长吧。
以上简单地展示了基于keras框架、MNIST数据集的DCGAN模型的结果,下面我们来详细地看一下这个代码的实现。
生成模型的结构
def generator_model(): model = Sequential() model.add(Dense(input_dim=100, output_dim=1024)) model.add(Activation('tanh')) model.add(Dense(out_dim=128*7*7)) model.add(BatchNormalization()) model.add(Activation('tanh')) model.add(Reshape((128, 7, 7), input_shape=(128*7*7,))) model.add(UpSampling2D(size=(2, 2))) model.add(Convolution2D(out_channel=64, kernel_height=5, kernel_width=5, border_mode='same')) model.add(Activation('tanh')) model.add(UpSampling2D(size=(2, 2))) model.add(Convolution2D(out_channel=1, kernel_height=5, kernel_width=5, border_mode='same')) model.add(Activation('tanh')) return model
直接上代码了。keras的代码总体上比较直观,我在里面加了一些参数对应的描述,应该编译不过,但是会比较好理解。这里需要说明的一点是,这个实现中的激活函数都是双曲正切,和论文中的描述不一样。当然,和论文中的模型架构也不一样,不过两者的数据集也不一样。
判别模型的结构
判别模型的结构如下所示,仔细地读一遍就可以理解,这里不需要赘述了。
def discriminator_model(): model = Sequential() model.add(Convolution2D( 64, 5, 5, border_mode='same', input_shape=(1, 28, 28))) model.add(Activation('tanh')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Convolution2D(128, 5, 5)) model.add(Activation('tanh')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Flatten()) model.add(Dense(1024)) model.add(Activation('tanh')) model.add(Dense(1)) model.add(Activation('sigmoid')) return model
训练
这里的训练的一轮迭代可以用下面的流程表示:
- 利用G生成一批generated_image
- 将真实的数据和generated_image合并,并放入D中进行一轮训练,其中真实数据的label为1,generated_image的label为0。
- 利用G再生成一批generated_image
- 这一次将G和D连起来,并给第3步的gereated_image的label设为1,固定D的参数不变,进行一轮训练。
可以看出第1,2步是为了优化D,第3,4步是为了优化G,而两者之间还是存在着紧密的联系。
图像生成
图像生成的过程可以用如下两步表示:
- 利用G生成一大批generated_image
- 利用D计算这些generated_image的分类结果,把得分高的一批选出来
最终我们看到的就是从D的眼皮下逃出的优质的生成数据。
好了,前面对代码的几个核心部分做了介绍,下面我们来看看实验过程中的一些问题。
图像的演变过程
在优化刚开始时,从随机生成的100维向量生成的图像是这样子的:
 其实就是噪声。
其实就是噪声。
经过400轮的迭代,生成模型可以生成下面的图像了:
 可以看出数字的大体结构已经形成,但是能够表征数字细节的特征还没有出现。
可以看出数字的大体结构已经形成,但是能够表征数字细节的特征还没有出现。
经过10个Epoch后,生成模型的作品:
 这时候有些数字已经成型,但是还有一些数字仍然存在欠缺。
这时候有些数字已经成型,但是还有一些数字仍然存在欠缺。
然后是20轮Epoch的结果:
 这个时候的数字已经具有很强的辨识度,但是与其同时,我们发现生成的数字中有大量的“1”。
这个时候的数字已经具有很强的辨识度,但是与其同时,我们发现生成的数字中有大量的“1”。
当完成了所有的训练,我们拿出生成模型在最后一轮生成的图像,可以看到:

可以看出这里面的数字质量更高一些,但是里面的1也更多了。
从这个演化过程中,我们可以看出,从一开始的数字生成质量都很差但生成数字的多样性比较好,到后来的数字质量比较高但数字的多样性比较差,模型的特性在不断地发生变化。这也和两个模型的对抗有关系,而这个演变也和增强学习中的“探索-利用”困境有关系。
我们站在生成模型的角度去想,一开始生成模型会尽可能地生成各种各样形状的数字,而判别模型会识别出一些形状较差的模型,而放过一些形状较好的模型,随着学习的进程不断推进,判别模型的能力也在不断地加强,生成模型慢慢发现有一些固定的套路比较容易通过,而其他一些套路不那么容易通过,于是它就会尽可能地增大这些“套路”出现的概率,让自己的loss变小。这样,一个从探索为主的模型变成了一个以利用为主的模型,实际上它的数据分布已经不那么均匀了。
如果这个模型继续训练下去,生成模型有可能进一步地利用这个“套路”,这和我们传统意义上的过拟合也有很相近的地方。所以我们希望能够避免这样的过拟合。
这个小实验也到此结束了,下面我们将看看论文中关于DCGAN的介绍,以及关于模型的一些改进方案和其他框架的实现。

