
深度学习笔记(六) 卷积神经网络
1.通常神经认知机包含两类神经元,即承担特征抽取的S-元和抗变形的C-元。S-元中涉及两个重要参数,即感受野与阈值参数,前者确定输入连接的数目,后者则控制对特征子模式的反应程度。在传统的神经认知机中,每个S-元的感光区中由C-元带来的视觉模糊量呈正态分布,也就是说如果眼睛感受到物体是移动的,即已感受到模糊和残影,S-感光区会调整识别模式,这时它不会完整地提取所有的特征给大脑而是只获取一部分关键特征,屏蔽其他的视觉干扰。也就是说,眼睛看到移动物体时,先通过C-元决定整体的特征感受控制度,再由S-感光区提取相应特征。如果感光区的边缘所产生的模糊效果要比中央来得大,S-元将会接受这种非正态模糊所导致的更大的变形容忍性。我们希望得到的是,训练模式与变形刺激模式在感受野的边缘与其中心所产生的效果之间的差异变得越来越大。为了有效地形成这种非正态模糊,Fukushima提出了带双C-元层的改进型神经认知机。
2.包含有神经元的卷积网络安排在三个维度上,每一层都将三维输入转换成三维输出值。官方的说法:每一层会定义一个图像过滤器,或者称为一个有权重的方阵,这里实际就是特定特征提取。通常每层会有多个特征提取方式相同的过滤器。什么叫过滤器,通常定义一个范围内的最小特征值就是过滤器。
3.卷积神经网络的组成部分:
卷积层 对输入数据应用若干过滤器 。 例如,图像的第一个卷积可能有四个6 x6过滤器。 对图像应用一个过滤器的结果称为特征图谱/特征映射 (FM),特征映射图像的数量等于过滤器数量。 如果前面的层也是卷积层,那么过滤器应用在FM上,相当于输入一个FM,输出另外一个FM。 同一个权重应用于整个图像上意味着特征无论在哪个位置都能被检测到,同时多个过滤器可以同时探测多个特征。
子采样层 又叫池化层,减少输入数据的规模。 例如,如果输入32 x32的图像,通过一个2 x2的子采样,输出值将是16 x16图像,这意味着输入图像的4 Pixel像素(每个2 x2面积)将被组合到一个输出pixel。如果输入12 x12的图像,通过一个6 x6的子采样,输出值将是2 x2图像。 有多种方法二次取样,但最受欢迎的有最大值合并(最大池)max pooling , 平均值合并(平均池)average pooling , 随机合并(随机池)stochastic pooling 。
最后一个子采样层(或卷积)层通常是连接到一个或多个完全连接层,全连接层的输出就是最后的输出。
4.训练过程通过改进的反向传播实现,将子采样层作为考虑因素并基于所有值来更新卷积过滤器的权重。
5.卷积神经网络是一个多层的神经网络,每层由多个二维平面组成,而每个平面由多个独立神经元组成。
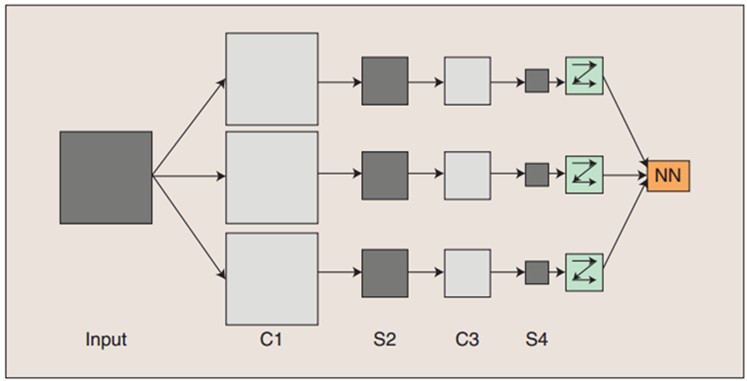
上图是卷积神经网络的概念示范:输入图像通过和三个可训练的滤波器和可加偏置进行卷积,卷积后在C1层产生三个特征映射图,然后特征映射图中每组的四个像素再进行求和,加权值,加偏置,通过一个Sigmoid函数得到三个S2层的特征映射图。这些映射图再进过滤波得到C3层。这个层级结构再和S2一样产生S4。最终,这些像素值被光栅化(处理去规则化),并连接成一个向量输入到传统的神经网络,得到输出。每个层有多个Feature Map,每个Feature Map通过一种卷积滤波器提取输入的一种特征,然后每个Feature Map有多个神经元。简单说就是去掉了读不懂的数据(符合一定特征的,或者可以提取特征的),留下了读得懂的数据。
6.CNN的基本结构包括两层,其一为特征提取层,每个神经元的输入与前一层的局部接受域相连,并提取该局部的特征。一旦该局部特征被提取后,它与其它特征间的位置关系也随之确定下来;其二是特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射是一个平面,平面上所有神经元的权值相等。特征映射结构采用影响函数核小的sigmoid函数作为卷积网络的激活函数,使得特征映射具有位移不变性。此外,由于一个映射面上的神经元共享权值,因而减少了网络自由参数的个数。卷积神经网络中的每一个卷积层都紧跟着一个用来求局部平均与二次提取的计算层,这种特有的两次特征提取结构减小了特征分辨率,使得网络在识别时对输入样本有着较好的畸变容忍能力。
7.卷积神经网络的核心思想是把完整的输入信息切成一个个子采样层进行采样,然后将提取的特征值和权重值作为参数传到下一层。
8.样例:

C1层是一个卷积层,由6个特征图Feature Map构成。特征图中每个神经元与输入中5*5的邻域相连。特征图的大小为28*28,这样能防止输入的连接掉到边界之外)。C1有156个可训练参数(每个滤波器5*5=25个unit参数和一个bias参数,一共6个滤波器,共(5*5+1)*6=156个参数),共156*(28*28)=122,304个连接。
S2层是一个下采样层,有6个14*14的特征图。特征图中的每个单元与C1中相对应特征图的2*2邻域相连接。S2层每个单元的4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid函数计算。可训练系数和偏置控制着sigmoid函数的非线性程度。如果系数比较小,那么运算近似于线性运算,亚采样相当于模糊图像。如果系数比较大,根据偏置的大小亚采样可以被看成是有噪声的“或”运算或者有噪声的“与”运算。每个单元的2*2感受野并不重叠,因此S2中每个特征图的大小是C1中特征图大小的1/4(行和列各1/2)。S2层有12(可训练参数:2*6(和的权+偏置))个可训练参数和5880((2*2+1)*6*14*14)个连接。
C3层也是一个卷积层,它同样通过5x5的卷积核去卷积层S2,然后得到的特征map就只有10x10个神经元,但是它有16种不同的卷积核,所以就存在16个特征map了。这里需要注意的一点是:C3中的每个特征map是连接到S2中的所有6个或者几个特征map的,表示本层的特征map是上一层提取到的特征map的不同组合(这个做法也并不是唯一的)。(看到没有,这里是组合,就像之前聊到的人的视觉系统一样,底层的结构构成上层更抽象的结构,例如边缘构成形状或者目标的部分)。刚才说C3中每个特征图由S2中所有6个或者几个特征map组合而成。为什么不把S2中的每个特征图连接到每个C3的特征图呢?原因有2点。第一,不完全的连接机制将连接的数量保持在合理的范围内。第二,也是最重要的,其破坏了网络的对称性。由于不同的特征图有不同的输入,所以迫使他们抽取不同的特征(希望是互补的)。 例如,存在的一个方式是:C3的前6个特征图以S2中3个相邻的特征图子集为输入。接下来6个特征图以S2中4个相邻特征图子集为输入。然后的3个以不相邻的4个特征图子集为输入。最后一个将S2中所有特征图为输入。这样C3层有6*(3*25+1)+6*(4*25+1)+3*(4*25+1)+(25*6+1)=1516个可训练参数和10*10*1516=151600个连接。
S4层是一个下采样层,由16个5*5大小的特征图构成。特征图中的每个单元与C3中相应特征图的2*2邻域相连接,跟C1和S2之间的连接一样。S4层有32个可训练参数(每个特征图1个因子和一个偏置)和16*(2*2+1)*5*5=2000个连接。
C5层是一个卷积层,有120个特征图。每个单元与S4层的全部16个单元的5*5邻域相连。由于S4层特征图的大小也为5*5(同滤波器一样),故C5特征图的大小为1*1:这构成了S4和C5之间的全连接。之所以仍将C5标示为卷积层而非全相联层,是因为如果LeNet-5的输入变大,而其他的保持不变,那么此时特征图的维数就会比1*1大。C5层有120*(16*5*5+1)=48120个可训练连接。
F6层有84个单元(之所以选这个数字的原因来自于输出层的设计),与C5层全相连。有10164个可训练参数。如同经典神经网络,F6层计算输入向量和权重向量之间的点积,再加上一个偏置。然后将其传递给sigmoid函数产生单元i的一个状态。
最后,输出层由欧式径向基函数(Euclidean Radial Basis Function)单元组成,每类一个单元,每个有84个输入。换句话说,每个输出RBF单元计算输入向量和参数向量之间的欧式距离。输入离参数向量越远,RBF输出的越大。一个RBF输出可以被理解为衡量输入模式和与RBF相关联类的一个模型的匹配程度的惩罚项。用概率术语来说,RBF输出可以被理解为F6层配置空间的高斯分布的负log-likelihood。给定一个输入模式,损失函数应能使得F6的配置与RBF参数向量(即模式的期望分类)足够接近。这些单元的参数是人工选取并保持固定的(至少初始时候如此)。这些参数向量的成分被设为-1或1。虽然这些参数可以以-1和1等概率的方式任选,或者构成一个纠错码,但是被设计成一个相应字符类的7*12大小(即84)的格式化图片。这种表示对识别单独的数字不是很有用,但是对识别可打印ASCII集中的字符串很有用。
9.卷积神经网络CNN主要用来识别位移、缩放及其他形式扭曲不变性的二维图形。由于CNN的特征检测层通过训练数据进行学习,所以在使用CNN时,避免了显式的特征抽取,而隐式地从训练数据中进行学习;再者由于同一特征映射面上的神经元权值相同,所以网络可以并行学习,这也是卷积网络相对于神经元彼此相连网络的一大优势。卷积神经网络以其局部权值共享的特殊结构在语音识别和图像处理方面有着独特的优越性,其布局更接近于实际的生物神经网络,权值共享降低了网络的复杂性,特别是多维输入向量的图像可以直接输入网络这一特点避免了特征提取和分类过程中数据重建的复杂度。
卷积神经网络CNN主要用来识别位移、缩放及其他形式扭曲不变性的二维图形(这些是不是在最一开始的时候就对图形进行修正呢,因为不同的卷积核进行不同的修正????)。由于CNN的特征检测层通过训练数据进行学习,所以在使用CNN时,避免了显式的特征抽取,而隐式地从训练数据中进行学习;再者由于同一特征映射面上的神经元权值相同,所以网络可以并行学习,这也是卷积网络相对于神经元彼此相连网络的一大优势。卷积神经网络以其局部权值共享的特殊结构在语音识别和图像处理方面有着独特的优越性,其布局更接近于实际的生物神经网络,权值共享降低了网络的复杂性,特别是多维输入向量的图像可以直接输入网络这一特点避免了特征提取和分类过程中数据重建的复杂度。
流的分类方式几乎都是基于统计特征的,这就意味着在进行分辨前必须提取某些特征。然而,显式的特征提取并不容易,在一些应用问题中也并非总是可靠的。卷积神经网络,它避免了显式的特征取样,隐式地从训练数据中进行学习。这使得卷积神经网络明显有别于其他基于神经网络的分类器,通过结构重组和减少权值将特征提取功能融合进多层感知器。它可以直接处理灰度图片,能够直接用于处理基于图像的分类。
卷积网络较一般神经网络在图像处理方面有如下优点: a)输入图像和网络的拓扑结构能很好的吻合;b)特征提取和模式分类同时进行,并同时在训练中产生;c)权重共享可以减少网络的训练参数,使神经网络结构变得更简单,适应性更强。

