Python----Kernel SVM
什么是kernel
Kernel的其实就是将向量feature转换与点积运算合并后的运算,如下,

概念上很简单,但是并不是所有的feature转换函数都有kernel的特性。
常见kernel
常见kernel有多项式,高斯和线性,各有利弊。
kernel SVM
在非线性的SVM算法中,如何将一组线性不可分的数据,利用从低维到高维的投射,使它变成在高维空间中线性可分的数据。将已经分割好的数据,投射回到原先的空间,及低维空间。
(1)一维空间
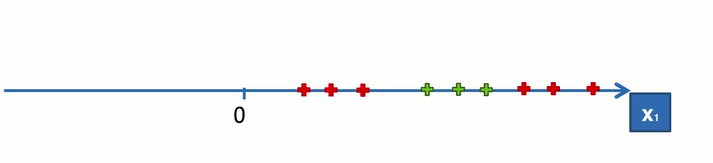
一维空间中的线性分类,找是否从在一个点,使一边都是红,一边都是绿,显然这样的线性分类器是不存在的。所以将数据投射到二维的空间里,例如:
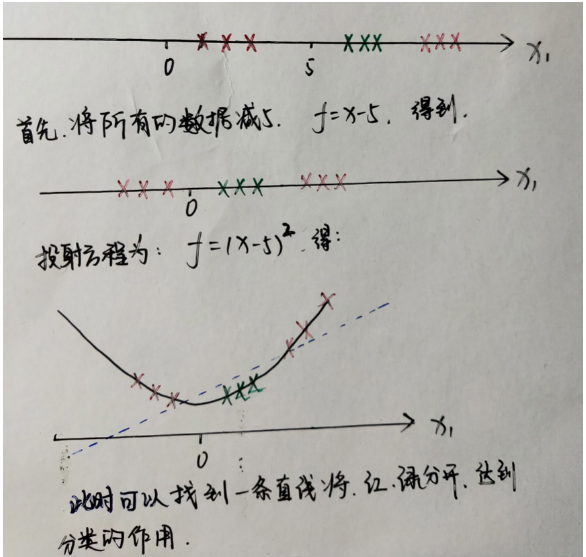
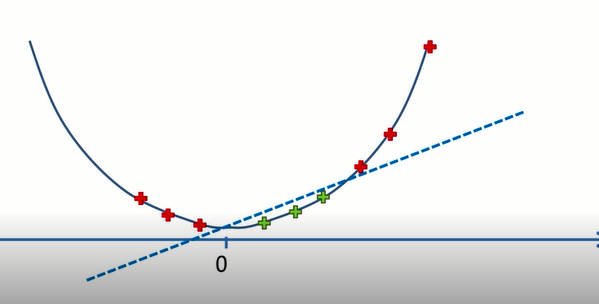
(2)二维
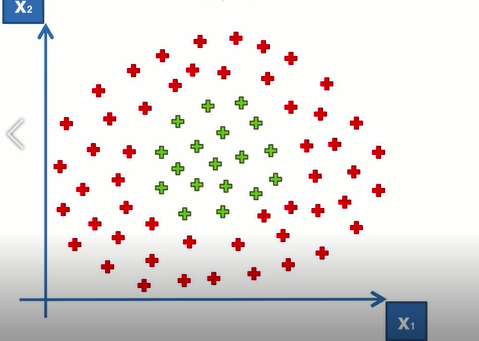
投射,保持X1轴和X2轴不变,增加第三个轴,将X1,X2两个点投射到一个三维空间里,前两个维度不变,第三个z与X1,X2有关系;在新的三维空间里,绿色和红色就变成了线性可分。线性可分在不是二维的空间中,有一个超平面,将两组数据分开。
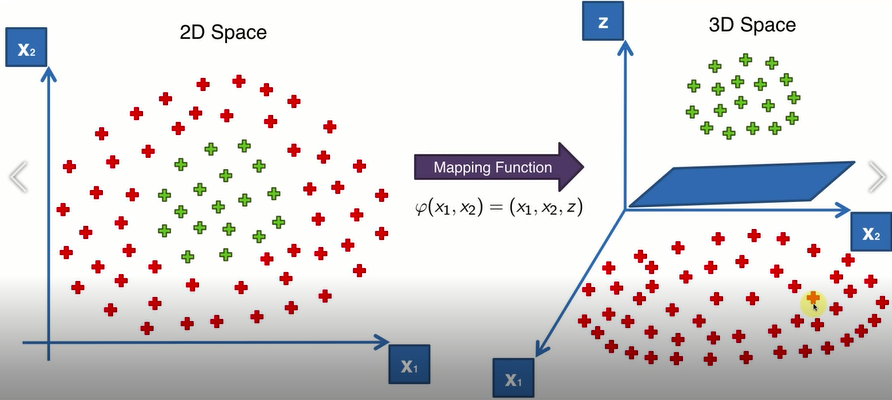
(3)反向投射
三维空间中找到的分割的平面,与数据本身结构,根据这两个信息,找出在原来数据空间二维空间中的分类界线。

核技巧在非线性SVM的应用
(1)非线性SVM最常用的核方程:![]()

假设只有一个自变量X,而l已定,看成一个关于X的函数,此时的函数在空间中的形态
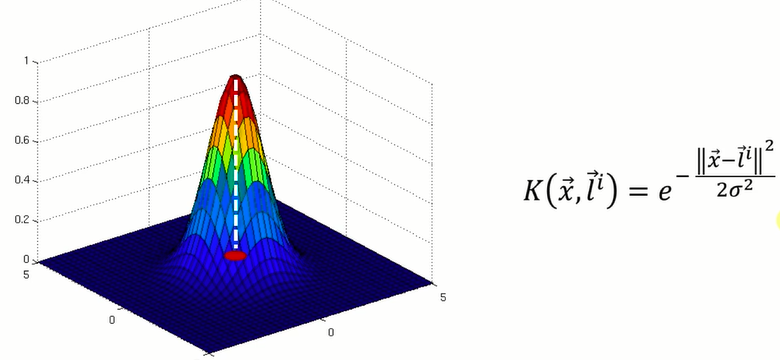 l点就是(0,0)这个点
l点就是(0,0)这个点
利用高斯核函数算出分类函数:
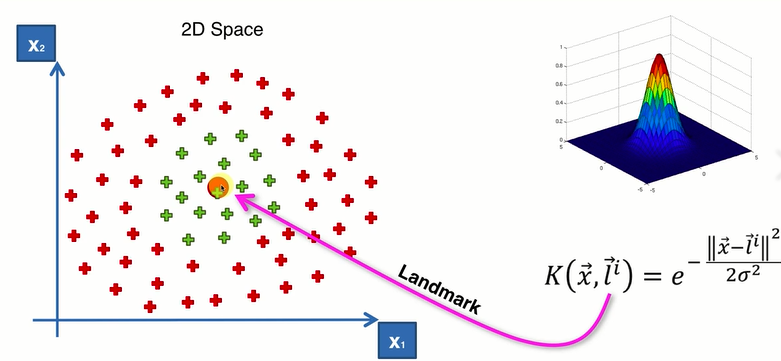
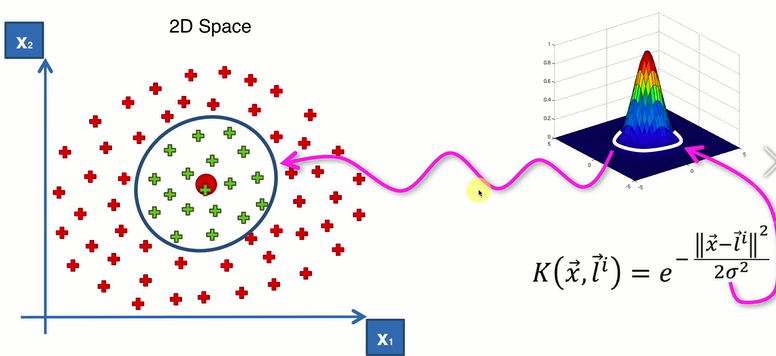
绿点所对应的高斯核函数的值,坐落在白色圈的里面(小山上);红点所对应的高斯核函数的值,坐落在周围深蓝色图像上。做出的投影图。
σ:控制圈的半径(大小)
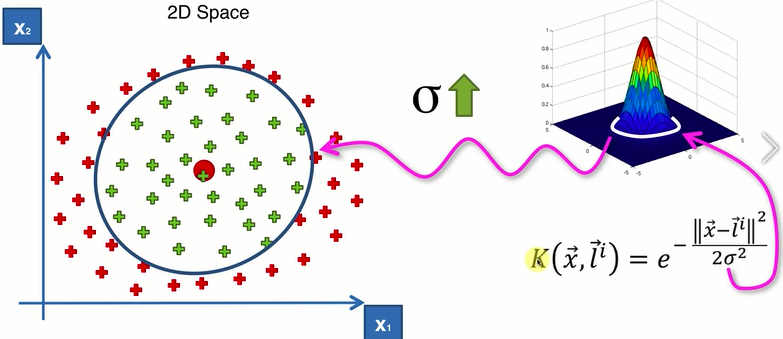
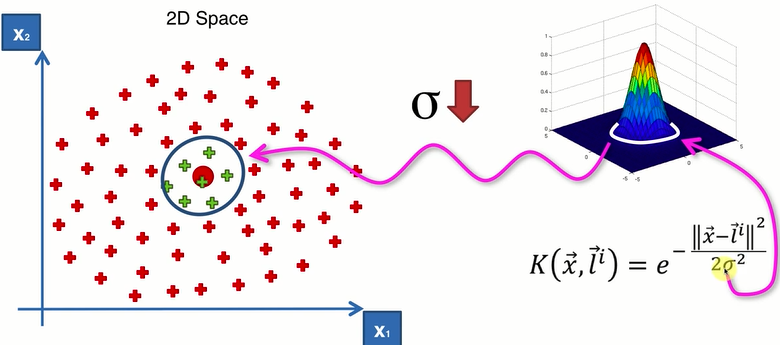
(2)较复杂的二维
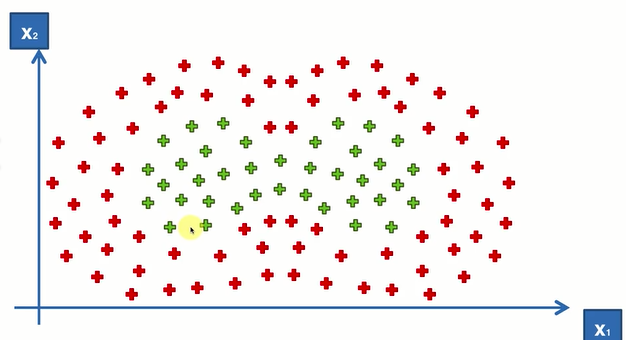 此时的核函数
此时的核函数![]()
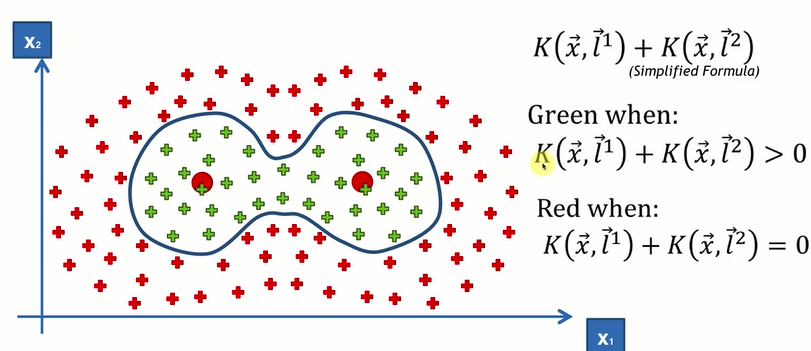
实例
数据集

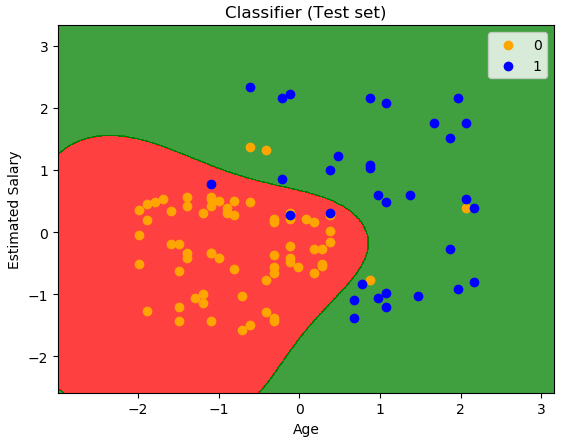
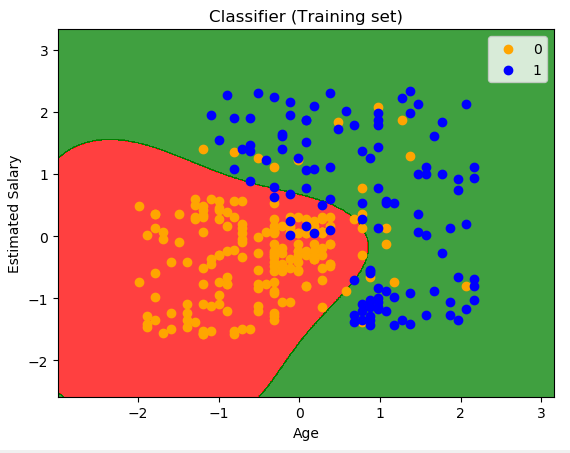
# Importing the libraries import numpy as np import matplotlib.pyplot as plt import pandas as pd # Importing the dataset dataset = pd.read_csv('Social_Network_Ads.csv') X = dataset.iloc[:, [2,3]].values y = dataset.iloc[:, 4].values # Splitting the dataset into the Training set and Test set from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0) # Feature Scaling from sklearn.preprocessing import StandardScaler sc_X = StandardScaler() X_train = sc_X.fit_transform(X_train) X_test = sc_X.transform(X_test) # Fitting Logistic Regression to the Training set #训练集拟合SVM的分类器 #从模型的标准库中导入需要的类 from sklearn.svm import SVC #创建分类器 classifier = SVC(kernel = 'rbf', random_state = 0)#rbf运用了高斯核 #运用训练集拟合分类器 classifier.fit(X_train, y_train) # Predicting the Test set results #运用拟合好的分类器预测测试集的结果情况 #创建变量(包含预测出的结果) y_pred = classifier.predict(X_test) # Making the Confusion Matrix #通过测试的结果评估分类器的性能 #用混淆矩阵,评估性能 #65,24对应着正确的预测个数;8,3对应错误预测个数;拟合好的分类器正确率:(65+24)/100 from sklearn.metrics import confusion_matrix cm = confusion_matrix(y_test, y_pred) # Visualising the Training set results #在图像看分类结果 from matplotlib.colors import ListedColormap #创建变量 X_set, y_set = X_train, y_train #x1,x2对应图中的像素;最小值-1,最大值+1,-1和+1是为了让图的边缘留白,像素之间的距离0.01;第一行年龄,第二行年收入 X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01), np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01)) #将不同像素点涂色,用拟合好的分类器预测每个点所属的分类并且根据分类值涂色 plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green'))) #标注最大值及最小值 plt.xlim(X1.min(), X1.max()) plt.ylim(X2.min(), X2.max()) #为了滑出实际观测的点(黄、蓝) for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1], c = ListedColormap(('orange', 'blue'))(i), label = j) plt.title('Classifier (Training set)') plt.xlabel('Age') plt.ylabel('Estimated Salary') #显示不同的点对应的值 plt.legend() #生成图像 plt.show() # Visualising the Test set results from matplotlib.colors import ListedColormap X_set, y_set = X_test, y_test X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01), np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01)) plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green'))) plt.xlim(X1.min(), X1.max()) plt.ylim(X2.min(), X2.max()) for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1], c = ListedColormap(('orange', 'blue'))(i), label = j) plt.title('Classifier (Test set)') plt.xlabel('Age') plt.ylabel('Estimated Salary') plt.legend() plt.show()
训练集图像显示结果:
测试集图像显示结果: