CS61B_时间复杂度

这是一个递归函数,其中有一个对自身的四次调用,并且在每次调用之后,输入的大小(N)减半。在函数的最后部分,有一个以Θ(N²)时间复杂度运行的函数g(N)。
现在让我们来计算这个函数的时间复杂度。
如果我们设T(N)为这个函数的时间复杂度,我们可以通过观察代码中的各个部分来构建一个递归方程。
递归的部分包含四个f4(N / 2),所以它们的总时间复杂度是4T(N / 2)。
然后是g(N),我们知道它的时间复杂度是Θ(N²)。
所以,我们可以建立一个递归方程,如下:
T(N) = 4T(N / 2) + Θ(N²)
这是一个典型的递归时间复杂度问题,可以使用主定理(Master Theorem)来解决。主定理可以帮助我们快速确定递归问题的时间复杂度。
根据主定理,如果我们有一个形式为T(n) = aT(n/b) + f(n)的递归关系,其中a >= 1,b > 1,f(n) 是一个正函数,我们可以比较f(n) 和n^log_b(a)的大小来决定T(n)的大小。
在我们的例子中,a = 4, b = 2, 且f(n) = n^2。所以n^log_b(a) = n^2。
在主定理的第二种情况中,k是一个非负实数,它出现在f(n)的定义中,即f(n) = Θ(n^log_b(a) * log^k(n))。
这里的k决定了除去n^log_b(a)的部分的增长率,也就是说,k是对数部分的次数。
如果k = 0,那么我们只有n^log_b(a)这一项。如果k = 1,那么我们有一个额外的log(n)因子。如果k = 2,那么我们有一个额外的(log(n))^2因子。依此类推。
主定理的第二种情况说明,如果f(n)与n^log_b(a)的增长率相同,并且我们有一个log^k(n)的因子(k大于或等于0),那么总体的时间复杂度就是n^log_b(a)乘以(log(n))的k+1次方。
换句话说,k决定了f(n)的复杂度在n^log_b(a)之上增长的速度。
确定k的值需要通过观察你的函数f(n)的形式来实现。
在主定理的第二种情况中,我们有 f(n) = Θ(n^log_b(a) * log^k(n))。如果你的函数f(n)具有这种形式,那么k的值就是log(n)项的指数。
举个例子,如果你有一个函数f(n) = n^2 * log^3(n),并且你正在处理一个形如T(n) = aT(n/b) + f(n)的递归关系,那么你可以看到 f(n) 具有n^log_b(a) * log^k(n) 的形式。如果a = 4 和 b = 2,那么 log_b(a) 就是2,因此 n^log_b(a) 就是 n^2,这和f(n)的n^2项匹配。然后你看到 log^3(n),所以这就告诉你 k = 3。
因此,确定k的值主要取决于你的f(n)函数的形式,特别是log(n)项的指数。
因为f(n) = Θ(n^log_b(a)),所以根据主定理的第二种情况,T(N) = Θ(n^log_b(a) * log^n) = Θ(N²logN)。
所以这个函数的时间复杂度是Θ(N²logN)。
主定理(Master Theorem)是一个用于解决递归式时间复杂度的常见工具。它可以帮助我们确定一些形式为T(n) = aT(n/b) + f(n)的递归关系的解。在这个等式中:
- n是问题的规模。
- a是子问题的数量。
- n/b是每个子问题的大小。
- f(n)是将子问题组合在一起的工作量。
主定理定义了三种情况,可以帮助我们找出这种形式的递归式的时间复杂度:
1. 如果f(n)是O(n^c),其中c < log_b(a),那么问题的时间复杂度是Θ(n^log_b(a))。
2. 如果f(n)是Θ(n^log_b(a) * log^k(n)),其中k >= 0,那么问题的时间复杂度是Θ(n^log_b(a) * log^(k+1)(n))。
3. 如果f(n)是Ω(n^c),其中c > log_b(a),如果a*f(n/b) <= k*f(n)对于某个常数k<1和所有足够大的n都成立,那么问题的时间复杂度是Θ(f(n))。
注意,主定理并不能解决所有形式的递归式,但对于许多常见形式的递归式,它都是一个非常有用的工具。
public static void p3(int N) { if (N <= 1) return; p3(N / 2); p3(N / 2); }
这段代码中的函数p3是一个典型的递归函数,它每次调用时,将问题规模N减小为原来的一半,并且调用自身两次。
这个递归函数的时间复杂度可以通过主定理(Master Theorem)来分析。我们可以将这个问题形式化为以下递归关系:
T(N) = 2T(N / 2) + O(1)
这个递归关系可以解读为:解决规模为N的问题需要解决两个规模为N/2的子问题,再加上常数时间的操作(即递归基础情况和函数调用)。
按照主定理的形式,这个递归关系中,a = 2, b = 2, 并且 f(n) = O(1),因此c = 0(因为1 = n^0)。现在我们需要比较c和log_b(a),即比较0和log_2(2)。在这种情况下,0 < log_2(2) = 1,因此我们可以应用主定理的第一种情况。
根据主定理的第一种情况,如果f(n)是O(n^c),其中c < log_b(a),那么问题的时间复杂度是Θ(n^log_b(a))。
因此,这个递归函数的时间复杂度是Θ(N^log_b(a)) = Θ(N^1) = Θ(N)。
所以,这段代码的时间复杂度是Θ(N)。


都是N^2
这段代码是一个递归函数,其中还包含一个for循环。让我们对其进行时间复杂度分析。
首先,有一个for循环,该循环将执行i次,其中cnst()是一个常数时间操作,所以这个循环的时间复杂度是O(i)。
接下来是递归部分,根据i的大小,它将进行不同的递归调用。如果i > N/2,那么它只调用一次foo2函数,递归深度减少1,这是一个线性的递归调用。否则,它调用foo2函数两次,每次递归深度减半,这是一个更复杂的递归调用。
对于i > N/2的情况,时间复杂度是O(N)。因为最差的情况是i从N开始,然后递减,直到i <= N/2,期间会有大约N/2次递归调用,每次递归调用的时间复杂度是O(i)。所以总的时间复杂度是O(N^2)。
对于i <= N/2的情况,它是一个类似于二分的递归过程,时间复杂度是O(logN)。因为每次递归深度减半,最多需要logN次递归调用,而每次递归调用的时间复杂度是O(i)。所以总的时间复杂度是O(i*logN)。
但是,最终的时间复杂度应该是这两种情况的最大值,即O(N^2)。
这是对这段代码时间复杂度的一个大致分析,可能还需要考虑其他因素,例如函数调用的开销等。但在大多数情况下,这种分析是有效的
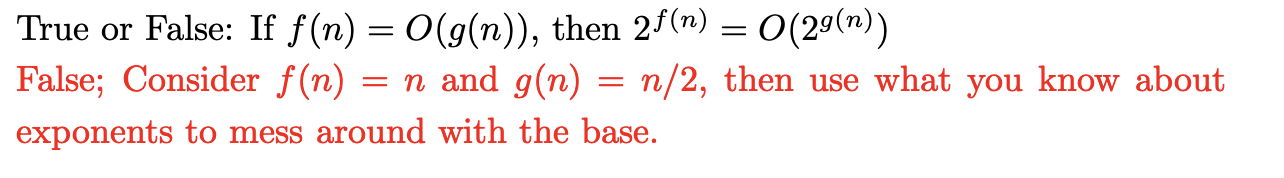
因为:big O 表示法,忽略常数项和前面的系数,但是系数可以不同。

T(n) = 2 T(n / 2) + n log n
a = 2 ,b = 2, log_b a = 1;
T(n) = aT(n/b) + Θ(n^log_b(a) * log^k(n))
那么k = 1;
在主定理的第二种情况中,k是一个非负实数,它出现在f(n)的定义中,即f(n) = Θ(n^log_b(a) * log^k(n))。
这里的k决定了除去n^log_b(a)的部分的增长率,也就是说,k是对数部分的次数。
如果k = 0,那么我们只有n^log_b(a)这一项。如果k = 1,那么我们有一个额外的log(n)因子。如果k = 2,那么我们有一个额外的(log(n))^2因子。依此类推。
主定理的第二种情况说明,如果f(n)与n^log_b(a)的增长率相同,并且我们有一个log^k(n)的因子(k大于或等于0),那么总体的时间复杂度就是n^log_b(a)乘以(log(n))的k+1次方。
则答案就是 n * log^ 2 n
例如,归并排序就是这种情况的一个例子,它的递归关系是T(n) = 2T(n/2) + Θ(n),你可以看到在这个情况中,a = 2,b = 2,f(n) = Θ(n),因此log_b(a) = 1,k = 0。根据主定理的第二种情况,我们可以得出其复杂度为T(n) = Θ(n*log(n))。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号