CS61A_Project2_Cat
Problem 6
题目描述:

注意事项:
1.不能使用for while循环
2.达到limit时,必须立即返回,不能继续递归
代码:
1.我的代码,很繁琐
1 def shifty_shifts(start, goal, limit): 2 """A diff function for autocorrect that determines how many letters 3 in START need to be substituted to create GOAL, then adds the difference in 4 their lengths. 5 """ 6 # BEGIN PROBLEM 6 7 #base case should about limit ,the recursion should stop when reach limitation , 8 if limit<0: 9 return 1 10 #base case 11 len_sta = len(start) 12 len_goa = len(goal) 13 dif=abs(len_sta-len_goa) 14 15 if len_sta != len_goa: 16 limit-=dif 17 18 sum=dif 19 array_sta = list(start) 20 array_goa = list(goal) 21 if array_sta[0]!=array_goa[0]: 22 limit-=1 23 sum+=1 24 if len_goa==1 or len_sta==1: 25 return sum 26 min_len=min(len_sta,len_goa) 27 sum+=shifty_shifts(array_sta[1:min_len],array_goa[1:min_len],limit) 28 return sum
2.优秀的、优雅的代码
1 def shifty_shifts(start, goal, limit): 2 """A diff function for autocorrect that determines how many letters 3 in START need to be substituted to create GOAL, then adds the difference in 4 their lengths. 5 """ 6 # BEGIN PROBLEM 6 7 if len(start) == 0: 8 return len(goal) 9 if len(goal) == 0: 10 return len(start) 11 if start[0] != goal[0]: 12 if limit == 0: 13 return 1 14 return 1 + shifty_shifts(start[1:], goal[1:], limit - 1) 15 else: 16 return shifty_shifts(start[1:], goal[1:], limit)
Problem7
题目描述:
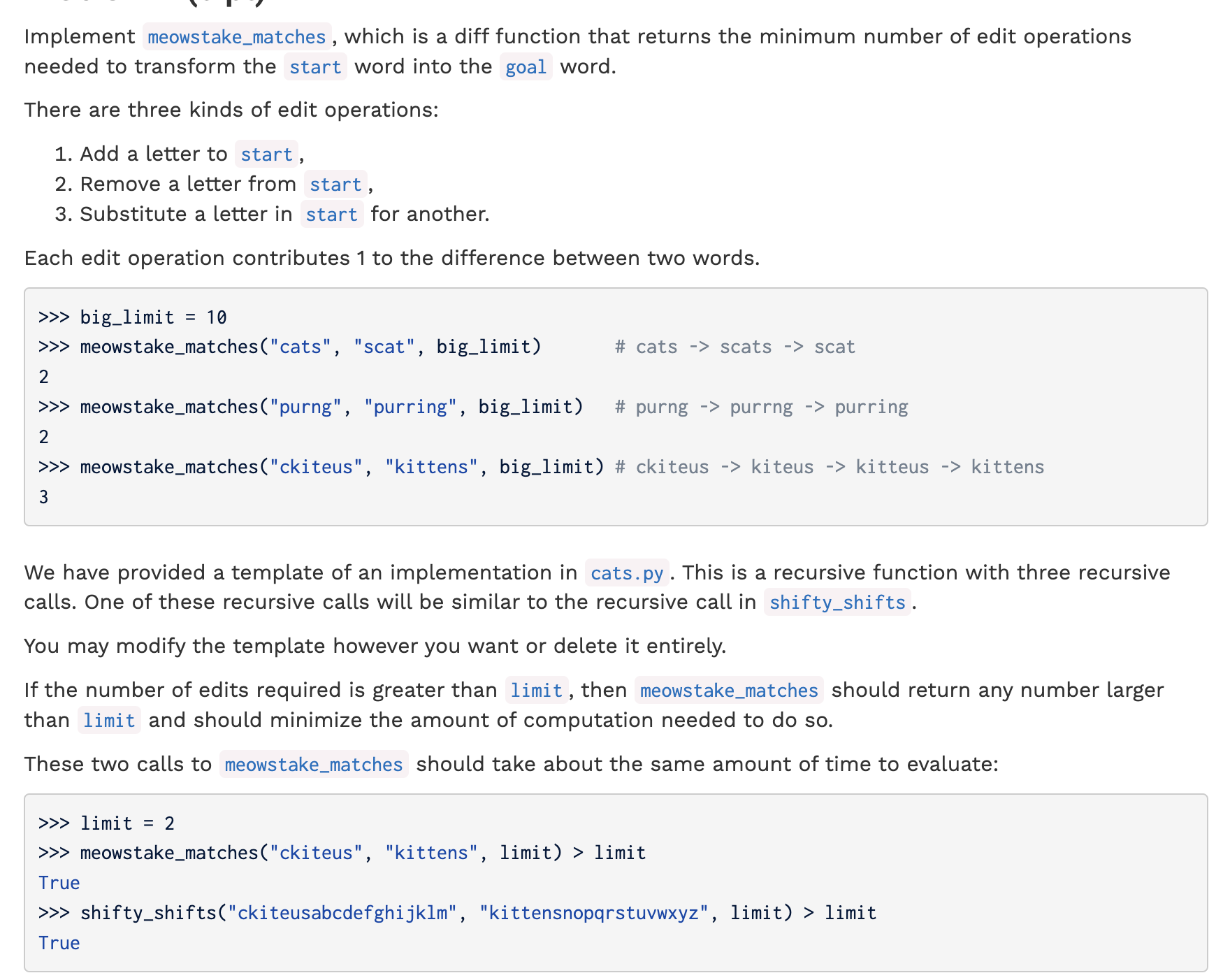
代码:
1 def meowstake_matches(start, goal, limit): 2 """A diff function that computes the edit distance from START to GOAL.""" 3 4 if limit < 0: 5 # BEGIN 6 "*** YOUR CODE HERE ***" 7 return 0 8 # END 9 10 elif len(start) == 0 or len(goal) == 0: 11 # BEGIN 12 "*** YOUR CODE HERE ***" 13 return len(start) + len(goal) 14 # END 15 elif start[0] == goal[0]: 16 return meowstake_matches(start[1:], goal[1:], limit) 17 else: 18 add_diff = meowstake_matches(start, goal[1:], limit - 1) 19 remove_diff = meowstake_matches(start[1:], goal, limit - 1) 20 substitute_diff = meowstake_matches(start[1:], goal[1:], limit - 1) 21 # BEGIN 22 "*** YOUR CODE HERE ***" 23 return 1 + min(min(add_diff, remove_diff), substitute_diff) 24 # END
反思:
1.题目已经给出明显的提示,并且自己也已经明显地感知到必须使用递归,但是并没有去按照自己总结的套路去做。所以以后一旦确定要用递归,那么就一定要按照套路去做。即先找好base case ,从最简单的案列开始,找出限定条件,再去想复杂的。
2.对事物的本质还是没有进行深刻的洞察。不能站在人的角度去思考,而是要站在机器的角度,计算机的角度。
譬如这一题,如果站在人的角度,肯定是一眼确定最大的相似位置,再来进行增删改。
但是站在机器的角度,这样子是无法进行的——不能找出最大的相似位置。
而题目已经给出提示,虽然仍然有所误导:提示是电脑只能一次处理一个,进行增删改,误导是直接到确定位置进行增删改。
而且最大的误导就是让人以为还要进行纠正,而不是简简单单的找出需要修改的次数。
3.最后return 中的1 是第一个字符位置的处理
对于每个字符,都需要进行至少一次操作才能匹配成功。因此,在进行插入、删除、替换操作之前,需要先将当前字符与目标字符串中对应位置的字符进行比较,以确定是否需要进行操作。
而对于起始字符串和目标字符串的第一个字符,它们之间的距离是由于它们不相同而产生的,因此需要进行一次操作才能匹配成功。因此,在进行插入、删除、替换操作之前,需要先将这两个字符进行比较,以确定是否需要进行操作。然后再将两个字符串都向后移动一位,继续进行递归调用,计算下一个字符的编辑距离。
因此,在计算编辑距离时,对于每个字符,都需要进行至少一次操作才能匹配成功,因此最小代价加上1就是当前字符的编辑距离。同时,在计算起始字符串和目标字符串的编辑距离时,也需要考虑它们的第一个字符是否匹配成功。
4.既然是要进行递归,那么肯定是首先处理一个,然后递归处理剩下的,那么问题就在于如何处理,处理谁。
如何处理,只有三种情况:增加,删除,替换。
增加,那么start第一个字符位置肯定相同了,原来的第一个字符位置移到二号位置,那么就比较二号位置呗。ok,goal [1:].
删除,那么start二号位置变为一号位置,goal还是没变,那么就继续比较一号位置呗。ok,start[1:]
替换,肯定二者一号位置都相同了,而且没有造成字符位置的变化,ok,那就同时比较后面的位置呗。start[1:] goal[1:]
但是注意每次只能处理一个,而且不知道谁才是最优的。那么都进行呗,最后取最优解,反正只是记录下处理次数。就像进行并行实验,只留下最好的,垃圾的都砍掉。
处理谁:
处理第一个元素,有两种情况:元素相同或者元素不同。
元素相同好解决,两个字符串都移位呗。元素不同,那么肯定会有一个change,这就是后面return 加一的由来。只是这个change是怎样的,就回到如何处理的问题了。
problem 9
题目描述:
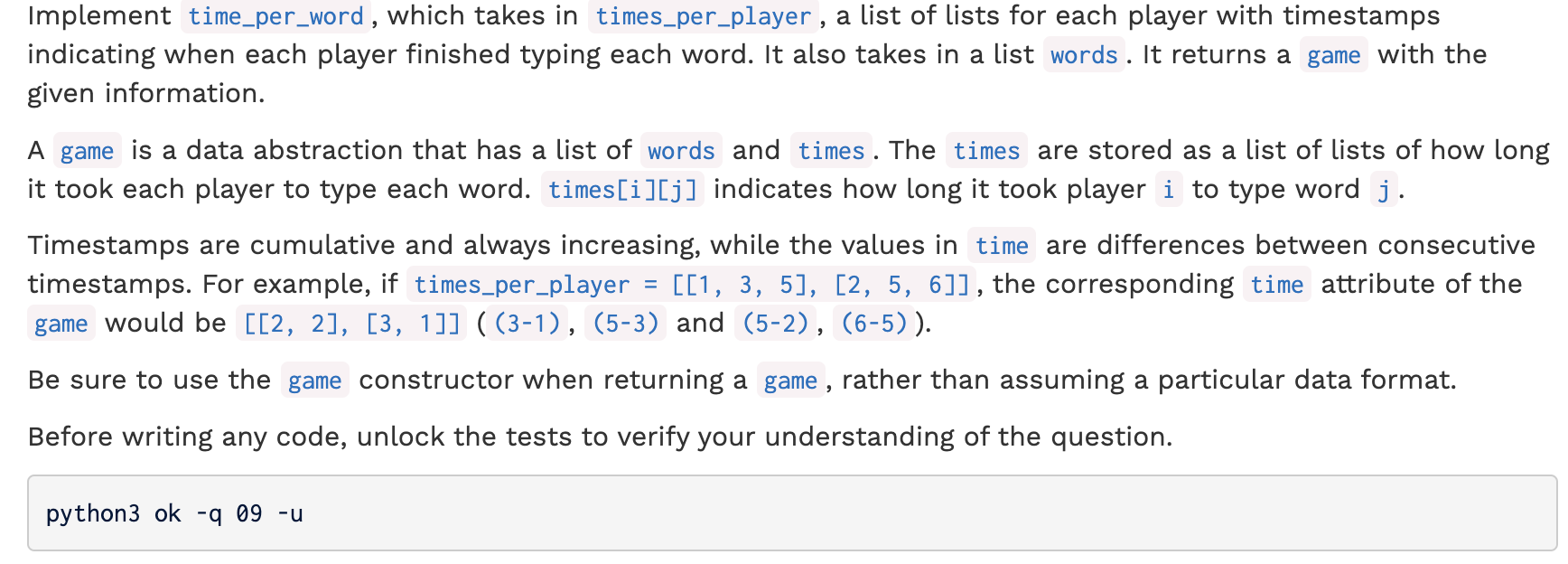
代码:
1.我的代码
1 def time_per_word(times_per_player, words): 2 """Given timing data, return a game data abstraction, which contains a list 3 of words and the amount of time each player took to type each word. 4 5 Arguments: 6 times_per_player: A list of lists of timestamps including the time 7 the player started typing, followed by the time 8 the player finished typing each word. 9 words: a list of words, in the order they are typed. 10 """ 11 # BEGIN PROBLEM 9 12 "*** YOUR CODE HERE ***" 13 #return a game which is a list of list 14 #first is words, and then is time 15 # p = [[0, 2, 3], [2, 4, 7]]-> [[2,1],[2,3]] 16 for i in range(0, len(times_per_player)): 17 for j in range(0,len(times_per_player[i])-1): 18 times_per_player[i][j]=times_per_player[i][j+1]-times_per_player[i][j] 19 times_per_player[i].pop(-1) 20 ls=[words,times_per_player] 21 return game(words,times_per_player)
2.别人的代码
1 def time_per_word(times_per_player, words): 2 """Given timing data, return a game data abstraction, which contains a list 3 of words and the amount of time each player took to type each word. 4 Arguments: 5 times_per_player: A list of lists of timestamps including the time 6 the player started typing, followed by the time 7 the player finished typing each word. 8 words: a list of words, in the order they are typed. 9 """ 10 # BEGIN PROBLEM 9 11 "*** YOUR CODE HERE ***" 12 tpp = [] 13 for player in times_per_player: 14 time = [] 15 for i in range(len(player) - 1): 16 time.append(player[i + 1] - player[i]) 17 tpp.append(time) 18 return game(words, tpp)
可以拓展一下思路
proble. 10
题目描述:
Implement fastest_words, which returns which words each player typed fastest. This function is called once both players have finished typing. It takes in a game.
The game argument is a game data abstraction, like the one returned in Problem 9. You can access words in the game with selectors word_at, which takes in a game and the word_index (an integer). You can access the time it took any player to type any word using time.
The fastest_words function returns a list of lists of words, one list for each player, and within each list the words they typed the fastest (against all the other players). In the case of a tie, consider the earliest player in the list (the smallest player index) to be the one who typed it the fastest.
Be sure to use the accessor functions for the game data abstraction, rather than assuming a particular data format.
代码:
1 def fastest_words(game): 2 """Return a list of lists of which words each player typed fastest. 3 Arguments: 4 game: a game data abstraction as returned by time_per_word. 5 Returns: 6 a list of lists containing which words each player typed fastest 7 """ 8 players = range(len(all_times(game))) # An index for each player 9 words = range(len(all_words(game))) # An index for each word 10 # BEGIN PROBLEM 10 11 "*** YOUR CODE HERE ***" 12 words = all_words(game) 13 times = all_times(game) 14 tot_player = len(times) 15 fastest = [[] for i in range(tot_player)] 16 for i, word in enumerate(words): 17 word_times = [times[player][i] for player in range(tot_player)] 18 idx = min(range(tot_player), key=lambda x: word_times[x]) 19 fastest[idx].append(word) 20 return fastest
启示:
1.如果想要重复某件事情,就可以使用for循环+range,想要重复N次,就用for i in rane(N)
fastest = [[] for i in range(tot_player)]
ps:range(10) :1-9
2.enumerate 的使用
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
idx = min(range(tot_player), key=lambda x: word_times[x])
[当我们想要找到一个列表中的最小值时,可以使用 Python 内置的 min 函数。min 函数可以接受一个列表作为参数,返回列表中的最小值。
在这里,我们也想要找到一个列表中的最小值,但是这个列表是由 word_times 构成的,而 word_times 是一个由不同玩家在说出某个单词所用的时间构成的列表。我们需要找到在这个列表中使用时间最短的玩家。
为了实现这个目的,我们使用了 Python 内置的 min 函数,但是在这里我们传递了两个参数。第一个参数是一个可迭代对象,表示待比较的对象范围。在这里,我们传递了一个范围对象 range(tot_player),表示从 0 到 tot_player - 1 的整数范围。第二个参数是 key 函数,表示比较的方法。我们使用了一个 lambda 函数,表示对于范围中的每个元素 x,返回 word_times[x],即该玩家说出该单词所用的时间。这样,min 函数会比较所有玩家所用的时间,找到其中使用时间最短的玩家的索引 idx,并将其返回。
因此,这行代码的作用是找到使用时间最短的玩家的索引 idx。]
我的理解:
1.首先我们要知道这个max with key 的作用是什么?
其实就是原来的max中的elements 在经过key 这个函数变化后,再进行比较。
2.分解:
range(tot_player)-> 就是所有的选手人数,形成列表。(0,N-1)
在带入到word_time[x]中,即转化为所有选手type 第 i个单词的时间。形成list,最后进行比较,选出最小的元素。
加分题二:
代码:
1 def memo(f): 2 """A memoization function as seen in John Denero's lecture on Growth""" 3 4 cache = {} 5 def memoized(*args): 6 if args not in cache: 7 cache[args] = f(*args) 8 return cache[args] 9 return memoized 10 11 key_distance_diff = memo(key_distance_diff) 12 key_distance_diff = count(key_distance_diff) 13 memo_for_fa = {} 14 15 def faster_autocorrect(user_word, valid_words, diff_function, limit): 16 """A memoized version of the autocorrect function implemented above.""" 17 18 # BEGIN PROBLEM EC2 19 "*** YOUR CODE HERE ***" 20 idx = tuple([user_word, tuple(valid_words), diff_function, limit]) 21 if user_word in valid_words: 22 return user_word 23 if idx in memo_for_fa: 24 return memo_for_fa[idx] 25 else: 26 # print("DEBUG: will is in the valid_words", "will" in valid_words) 27 # print("DEBUG: dist(woll, will) = ", diff_function(user_word, "will", limit)) 28 # print("DEBUG: dist(woll, well) = ", diff_function(user_word, "well", limit)) 29 words_diff = [diff_function(user_word, w, limit) for w in valid_words] 30 similar_word, similar_diff = min(zip(valid_words, words_diff), key=lambda item: item[1]) 31 print("DEBUG:", similar_word) 32 if similar_diff > limit: 33 ret = user_word 34 else: 35 ret = similar_word 36 memo_for_fa[idx] = ret 37 return ret

 浙公网安备 33010602011771号
浙公网安备 33010602011771号