

行驶证识别算法以及在中科麒麟系统的离线部署
行驶证作为车辆合法上路的证明文件,包含车辆的基本信息和车主的详细资料,是政府部门、保险公司、租赁公司以及交通管理系统中常用的文档。在日常业务操作中,快速、准确地录入行驶证信息对于提高工作效率、减少人工错误有着重要意义。然而,传统的手工输入过程不仅费时,还存在一定的错误率。为此,OCR(Optical Character Recognition,光学字符识别)技术被广泛应用于行驶证的自动识别中。
OCR技术在行驶证识别中的应用
OCR技术能够通过扫描或拍摄行驶证图像,将其中的文字内容转化为可编辑的文本数据。基于深度学习的现代OCR模型不仅能够识别印刷体和手写体,还能够应对复杂的背景、模糊或不清晰的图片。这使得OCR在行驶证识别场景中具有广泛的应用。
行驶证的结构通常包括:
- 车辆信息:如品牌型号、发动机号码、车辆识别代码、核定载人数等。
- 车主信息:如车主姓名、住址、证件号码等。
对于这种多种格式的文本,OCR模型需要具备多字段、多格式的识别能力。相比于传统的手工录入,OCR的优势在于:
- 提高效率:OCR能够在几秒钟内自动识别并录入行驶证信息,大幅缩短了信息处理的时间。
- 准确性高:通过先进的算法,OCR能够减少人工输入中的错误,提高信息录入的准确度。
- 无纸化办公:OCR的应用推动了行驶证信息管理的数字化和无纸化,有助于环保和资源节约。
- 可扩展性强:OCR能够与其他系统集成,如车辆管理系统、保险理赔系统等,自动将识别出的数据导入到业务流程中,实现信息的自动化处理。
OCR技术在国产系统中的适应性
在国产化系统的背景下,如麒麟操作系统中部署OCR行驶证识别服务,需要保证技术的安全性和离线部署能力。通过将OCR服务与国产操作系统、硬件环境深度集成,可以确保行驶证信息的本地化处理,避免数据外泄风险,符合国内对敏感信息的安全要求。这种解决方案不仅能确保业务的高效运行,还能在国家安全政策框架下推动数字化转型。
技术方案
行驶证识别可以看作OCR的一个具体应用,整个系统的部署可以参考 https://www.cnblogs.com/xueliangliu/articles/18412436 一般最简单的行驶证识别方法可以采用OCR后处理的方式来完成,即将OCR识别到的结果,通过分析其位置,文本模式等方式,来确定其字段的上下文语义。
比如,以下的代码用来检测行驶证中的证芯编号:
def number(self):
"""
证芯编号
"""
numbers = {}
numbers['行驶证证芯编号'] = "未识别"
self.res.update(numbers)
for i in range(int(self.N/4*3), self.N):
if self.result[i]['box']['cy'] < 0.8 or self.result[i]['box']['cx'] < 0.4 :
continue
txt = self.result[i]['text'].replace(' ', '').replace('.', '').replace('·', '')
txt = txt.replace(' ', '')
res = re.findall('[A-Za-z0-9]{8,14}', txt)
if len(res) > 0:
numbers['行驶证证芯编号'] = res[0]
self.res.update(numbers)
break
else:
numbers['行驶证证芯编号'] = "未识别"
self.res.update(numbers)
结果

识别结果: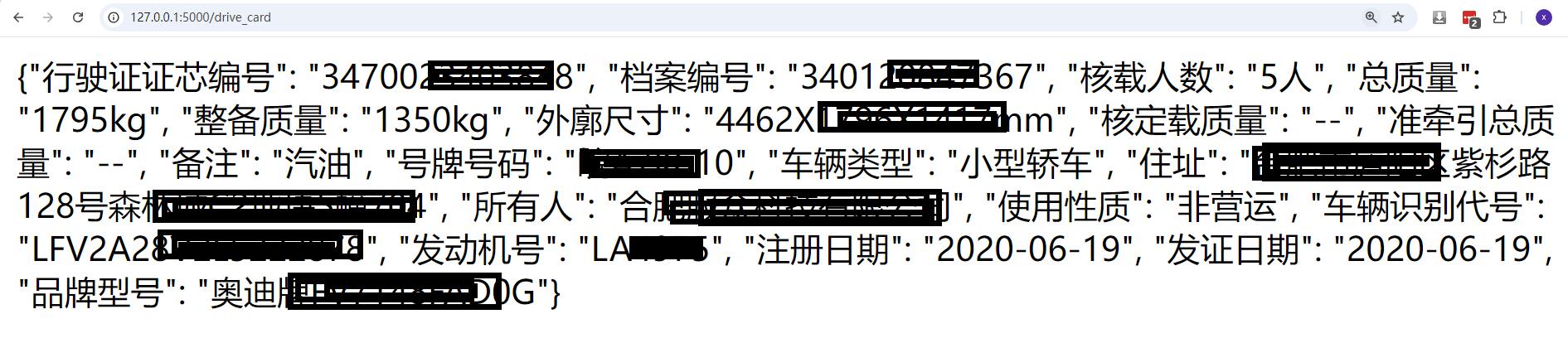
posted on 2024-09-13 17:07 xueliangliu 阅读(28) 评论(0) 编辑 收藏 举报

