


多线程同步精要
单机并发编程有两种基本模型:"消息传递"和"共享内存";分布式系统运行在多台机器上,只有一种实用模型:"消息传递"。
单机上多进程并发可以照搬"消息传递",多线程编程用"消息传递"更容易保证程序的正确性。
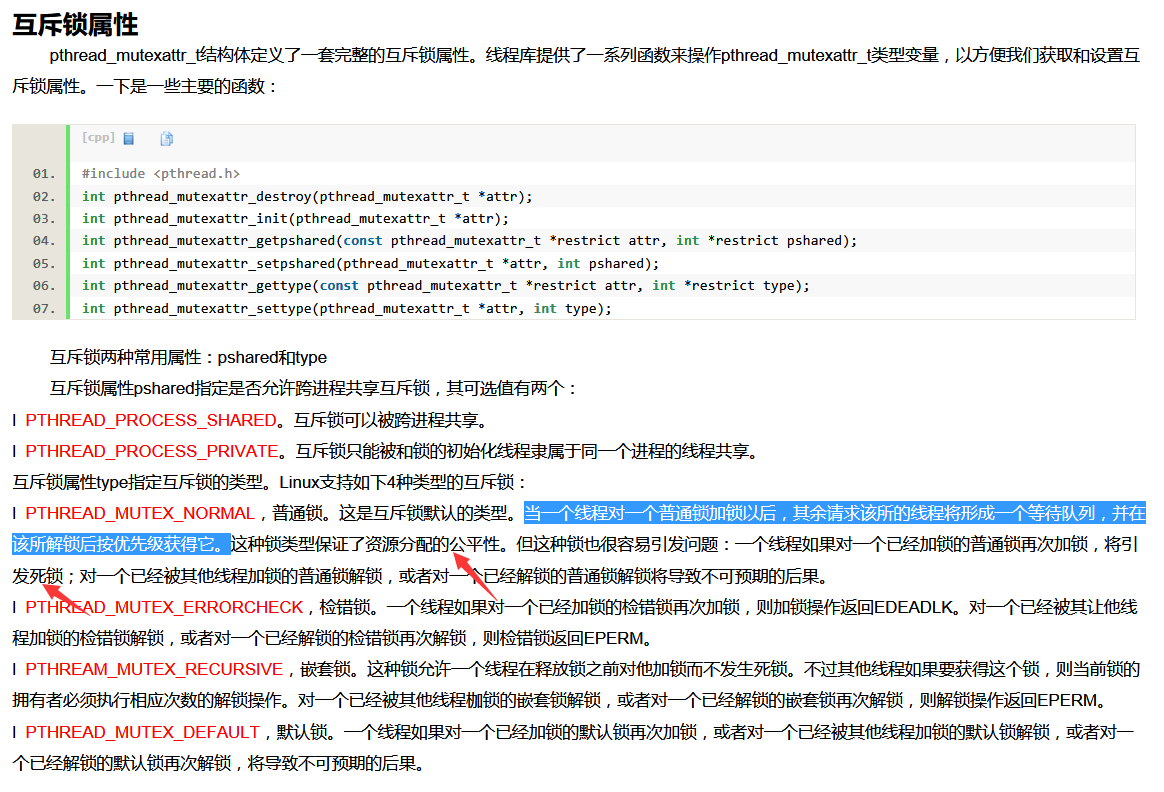
多线程同步有很多种方式:互斥量、条件变量、信号量、读写锁等。尽量不要用信号量和读写锁
Don’t use a semaphore where a mutex would suffice. A semaphore is a generic synchronization primitive originally described by Dijkstra that can be used to effect a wide range of behavior. It may be tempting to use semaphores in lieu of mutexes to protect critical sections, but there is an important difference between the two constructs: unlike a semaphore, a mutex has a notion of ownership—the lock is either owned or not, and if it is owned, it has a known owner. By contrast, a semaphore (and its kin, the condition variable) has no notion of ownership: when sleeping on a semaphore, one has no way of knowing which thread one is blocking upon.(引自《Real-World Concurrency》http://queue.acm.org/detail.cfm?id=1454462)
信号量的另一个问题是:它有自己的计数值,通常我们自己的数据结构也有长度值,这就造成了同样的信息存了两份,这就需要时刻保持一致,增加了程序员的负担和出错的可能。
mutex和condition variable是用的最多的,用他们两个足以应对大多数的使用场景。
互斥量mutex
原则:
1.利用RAII自动创建、销毁、加锁、解锁,不手动调用lock() unlock()函数。
2.只用在线程同步中,不用跨进程的mutex。
3.首选非递归mutex(不可重入mutex)。附:windows的CRITICAL_SECTION是可重入的,linux下要设置PTHREAD_MUTEX_NORMAL属性。不可重入mutex的优点是:在同一个线程里多次对non-recursive mutex加锁会立刻导致死锁,这能够帮助我们思考代码对锁的期求,并且及早(在编码阶段)发现问题。
mutex是加锁原语,用来排他性的访问共享数据,它不是等待原语。在使用mutex的时候,我们一般都会期望加锁不要阻塞,总是能立刻拿到锁。然后尽快访问数据,用完之后尽快解锁,这样才能不影响并发性和性能。
条件变量condition variable
如果需要等待某个条件成立,我们应该使用条件变量。条件变量是一个或多个线程等待某个bool表达式为真,即等待别的线程“唤醒”它。
条件变量只要一种正确的使用方式,几乎不可能用错。对于wait端书写顺序:
1.用mutex保护(必须)。
2.while循环判断布尔表达式,循环内调用wait();
3.实际的数据操作(读写布尔表达式)。
代码如下:
int dequeue() { MutexLock lock(g_mutex);
while (g_queue.empty()) { g_cond.Wait();//wait这一步会原子性的释放mutex并进入等待,不会与其他线程死锁(卡在这里两三个小时) //g_cond.Wait()执行完毕后自动重新加锁 } assert(!g_queue.empty()); int data = g_queue.front(); g_queue.pop_front();
return data; }
linux的源码说明:
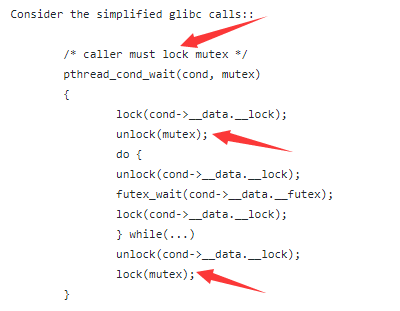
pthread.h文件注释:
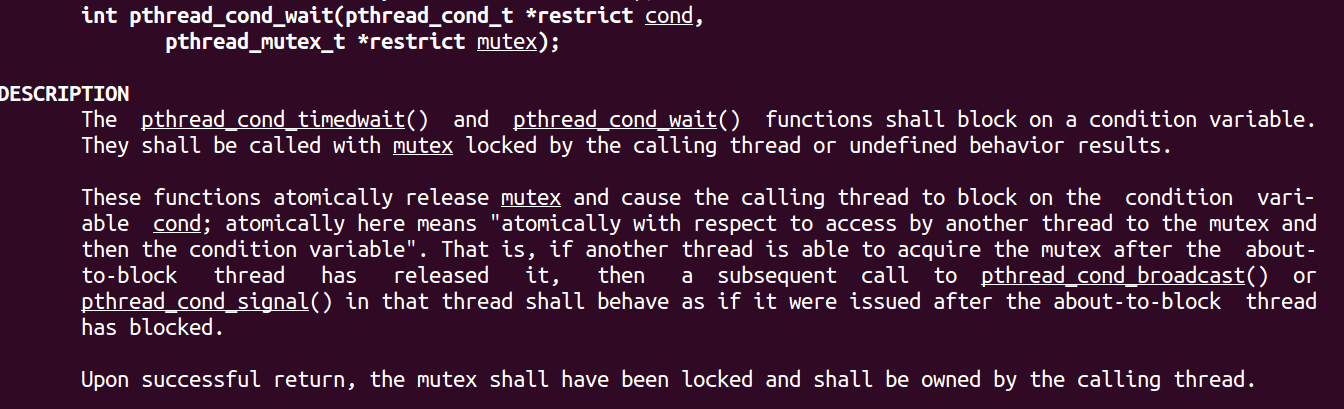
manpage说明:
对于signal/broadcast端书写顺序:
1.用mutex保护(2);
2.修改布尔表达式值;
3.发送signal/broadcast。
代码如下:
void enqueue(int x) { { MutexLock lock(g_mutex); g_queue.push_back(x); } g_cond.Signal(); }


