


Python:机器学习库 sklearn
安装:
pip install -U scikit-learn
数据标准化
from sklearn import preprocessing
a = np.array([[10, 2.7, 3.6],
[-100, 5, -2],
[120, 20, 40]], dtype=np.float64)
res = preprocessing.scale(a)
'''
[[ 0. -0.85170713 -0.55138018]
[-1.22474487 -0.55187146 -0.852133 ]
[ 1.22474487 1.40357859 1.40351318]]
'''
训练集测试集分割
分割的同时会打乱数据顺序
from sklearn.cross_validation import train_test_split
a = np.arange(40).reshape(10, 4)
train, test = train_test_split(a, test_size=0.3)
'''
[[20 21 22 23]
[28 29 30 31]
[ 0 1 2 3]
[ 4 5 6 7]
[12 13 14 15]
[16 17 18 19]
[32 33 34 35]]
[[24 25 26 27]
[36 37 38 39]
[ 8 9 10 11]]
'''
生成测试数据
from sklearn.datasets.samples_generator import make_classification
X, y = make_classification()
X, y = make_classification(n_samples=100, n_features=3, n_classes=3, n_redundant=0, n_informative=3, random_state=22, n_clusters_per_class=2, scale=100)
[[ 76.25530311 104.61848707 -124.51537604]
[ 14.00181364 218.02679285 -189.2891996 ]
[ 9.52106591 146.5469016 -19.52563088]
...
[ 49.31656749 74.3968861 -82.10408259]
[ 333.62879001 240.97683418 -262.34040171]
[-263.15760407 29.60401483 -267.22306047]]
[1 0 0 1 0 0 0 2 1 0 1 1 0 2 0 0 2 1 1 0 1 0 0 2 2 2 1 0 1 0 2 2 0 2 1 2 2
1 1 2 0 0 1 2 2 2 0 2 2 1 1 0 1 2 0 0 0 2 1 2 2 1 0 0 0 0 1 1 0 1 1 0 1 0
1 1 2 1 0 2 2 2 2 0 1 2 0 1 0 0 0 1 0 0 2 1 0 2 1 1]
分类算法
from sklearn.neighbors import KNeighborsClassifier
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
knn1 = KNeighborsClassifier()
knn2 = KNeighborsClassifier(n_neighbors=7)
knn1.fit(X_train, y_train)
print(knn1.score(X_test, y_test)) #训练模型在测试数据集上的准确率得分
knn2.fit(X_train, y_train)
print(knn2.score(X_test, y_test))
print(knn2.predict(X_test[:2])) #对测试数据集前两条进行分类预测:[1 2]
分类demo
直接对原数据和对原数据归一化后
from sklearn import preprocessing
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
X, y = make_classification()
print(X);print()
print(y);print()
X_train, X_test, y_train, y_test = train_test_split(X, y)
knn1 = KNeighborsClassifier()
knn1.fit(X_train, y_train)
r1_knn = knn1.score(X_test, y_test)
print('r1_knn: ', r1_knn)
clf1 = SVC()
clf1.fit(X_train, y_train)
r1_clf = clf1.score(X_test, y_test)
print('r1_clf: ', r1_clf)
X_s = preprocessing.minmax_scale(X, feature_range=(-1, 1))
X_train_s, X_test_s, y_train_s, y_test_s = train_test_split(X_s, y)
knn2 = KNeighborsClassifier()
knn2.fit(X_train_s, y_train_s)
r2_knn = knn2.score(X_test_s, y_test_s)
print('r2_knn: ', r2_knn)
clf2 = SVC()
clf2.fit(X_train_s, y_train_s)
r2_clf = clf2.score(X_test_s, y_test_s)
print('r2_clf: ', r2_clf)
交叉验证,可用于选择模型
所谓交叉验证就是自动将原始数据集做切分,一部分作为训练数据,另一部分作为测试数据。
然后用训练数据集进行模型训练,再计算训练出的模型在测试数据集上的准确率得分。
以上步骤进行多次。具体怎么切分和得分怎么计算要看交叉验证的参数配置。
from sklearn.cross_validation import cross_val_score
from sklearn.neighbors import KNeighborsClassifier
X, y = make_classification(n_samples=3000, n_features=5, n_classes=3, n_redundant=0, n_informative=4, random_state=22, n_clusters_per_class=2, scale=100)
score_arr = cross_val_score(KNeighborsClassifier(), X, y, cv=10) #cv=10会造成进行10次切分和计算,计算训练数据集训练出的模型在测试数据集上的得分
print(score_arr.mean())
辅助模型选择参数
import matplotlib.pyplot as plt
from sklearn.learning_curve import validation_curve #验证曲线
from sklearn.datasets.samples_generator import make_classification
from sklearn.svm import SVC
import numpy as np
X, y = make_classification(n_samples=1000, n_features=5, n_classes=3, n_redundant=0, n_informative=4, random_state=0, n_clusters_per_class=2, scale=100)
param_name = 'gamma' #验证在此数据集上SVC分类器在不同gamma参数下的分类效果
param_range = np.logspace(-8, -1, 8) #参数值:[1.e-08 1.e-07 1.e-06 1.e-05 1.e-04 1.e-03 1.e-02 1.e-01]
train_score, test_score = validation_curve(SVC(), X, y, param_name=param_name, param_range=param_range, cv=7, n_jobs=4) #n_jobs:线程数,默认1
'''上个语句说明:
分别计算gamma取不同值下,使用交叉验证,在X,y数据集上的训练数据得分和测试数据得分。
输出形式如下(此处交叉验证参数cv=7,也就是对每个gamma值计算7个得分结果,共对8个gamma值进行计算):
[[0.34813084 0.34889148 0.3453909 0.34305718 0.34189032 0.34305718
0.35040745]
[0.67640187 0.68494749 0.67677946 0.67911319 0.68494749 0.6907818
0.69383003]
...
[1. 1. 1. 1. 1. 1.
1. ]
[1. 1. 1. 1. 1. 1.
1. ]]
[[0.36111111 0.34265734 0.34265734 0.34265734 0.33566434 0.34265734
0.35460993]
[0.70138889 0.67832168 0.6993007 0.67832168 0.6993007 0.67132867
0.65248227]
...
[0.34027778 0.33566434 0.33566434 0.33566434 0.33566434 0.33566434
0.34042553]
[0.34027778 0.33566434 0.33566434 0.33566434 0.33566434 0.33566434
0.34042553]]
'''
plt.figure()
plt.semilogx(param_range, train_score.mean(axis=1), label='train') # 画出每个gamma值下计算的训练集交叉验证平均得分
plt.semilogx(param_range, test_score.mean(axis=1), 'r--', label='test') # 画出每个gamma值下计算的测试集交叉验证平均得分
plt.xlabel(param_name)
plt.ylabel('score')
plt.ylim(0.3, 1.05) # Y轴范围
plt.title("validation_curve")
plt.legend() # 显示图例
plt.show()
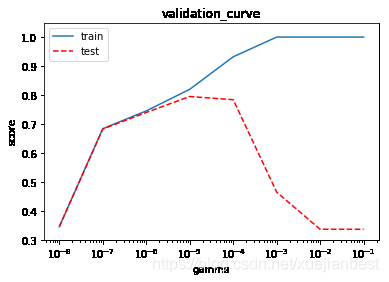
可以看出,随着gamma值的增大,模型从拟合不足到拟合良好再到过拟合(对训练数据得分很高,但对测试数据得分低)。
最佳的gamma值为测试数据得分最高的地方(红虚线最高点)。
输出学习曲线
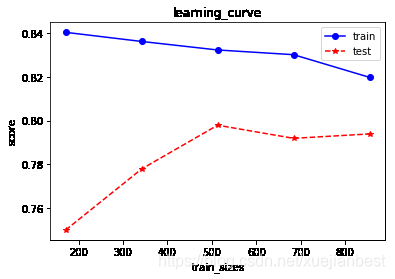
from sklearn.model_selection import learning_curve # sklearn.learning_curve和sklearn.model_selection下相同函数目前没发现区别
train_sizes = [0.2, 0.4, 0.6, 0.8, 1] # 训练样本数量,如0.2会用X的20%样本数据进行(训练集和测试集的)切分,然后进行交叉验证
train_size, train_scores, test_scores = learning_curve(SVC(gamma=0.00001), X, y, cv=7, train_sizes=train_sizes) # train_size:参与此次训练的样本数量,非百分比
plt.plot(train_size, train_scores.mean(1), 'o-', c='b', label='train')
plt.plot(train_size, test_scores.mean(1), '*--', c='r', label='test')
plt.xlabel('train_sizes')
plt.ylabel('score')
plt.title("learning_curve")
plt.legend(loc='best')
plt.show()
print(train_size)
保存、加载模型文件
from sklearn.externals import joblib
joblib.dump(knn1, 'd:/train100.knn')
knn = joblib.load('d:/train100.knn')
knn.predict(X[0:1])
要获取一个对象构造方法的参数列表和参数默认值用get_params():
knn = KNeighborsClassifier()
knn.get_params()
'''
{'algorithm': 'auto',
'leaf_size': 30,
'metric': 'minkowski',
'metric_params': None,
'n_neighbors': 5,
'p': 2,
'weights': 'uniform'}
'''

