


YARN简介
YARN(Yet Another Resource Negotiator)是hadoop2.0提供的新功能,它是一个集群资源调度管理的软件,其产生是为了更好的管理集群资源,突破hadoop1.0集群管理方式的缺陷。
先看原来方式的缺陷
hadoop最初采取的集群管理方式是这样的:
一个JobTracker进程,主要负责协调Client提交过来的Job,分配要在TaskTracker上运行的task。具体的,要负责以下两点功能:
- 管理集群中的计算资源,这涉及到维护活动节点列表、可用和占用的 map 和 reduce slots列表,以及依据所选的调度策略将可用的slot分配给合适的task。
- 协调在集群上运行的所有任务,这涉及到指导 TaskTracker 启动 map 和 reduce task,监视任务的执行,重新启动失败的任务,推测性地运行缓慢的任务,计算作业计数器值的总和,等等。
多个TaskTracker进程,负责执行JobTracker分配过来的任务,并向JobTracher发送报告。
[1]:一个Job分多个Task,Task分为map task和reduce task两种,map task只能在map slot上面运行,reduce task只能在reduce slot上运行。
[2]:集群管理员会把从属节点上的计算资源分解为固定数量的 map 和 reduce slot(插槽),也就是说可用的slot代表集群可用的计算资源。

MRv1集群资源管理方式主要有以下三个缺点:
- 当集群中有 5,000 个节点和 40,000 个任务同时运行时,JobTracker 必须不断跟踪数千个 TaskTracker、数百个Job作业,以及数万个 map 和 reduce task。这就会显现出由单个 JobTracker 导致的可伸缩性瓶颈。
- 每个从属节点上的计算资源由集群管理员分解为固定数量的 map 和 reduce slot,这些 slot 不可替代。如当map slot占满后,即使有空闲的reduce solt也无法运行更多的map任务,造成资源浪费。
- 这种集群管理方式仅适用运行 MapReduce作业,无法处理使用其他编程模型编写的作业程序。而随着替代性的编程模型(比如 Apache Giraph 所提供的图形处理)的到来,除 MapReduce 外,越来越需要为在同一个集群上运行其他编程模型提供支持。
[3]:MapReduce(简称MR)是Google推广的一种编程模型,它对以高度并行和可扩展的方式处理大数据集很有用。采用MR编程模型的开源实现很多,其中Hadoop MapReduce是最成功的。
为了解决以上问题,产生了YARN。
上面已经提到,JobTracker负责两点功能(集群资源管理和任务协调)。
YARN设计中,将这两点分开,让两种进程完成。
-
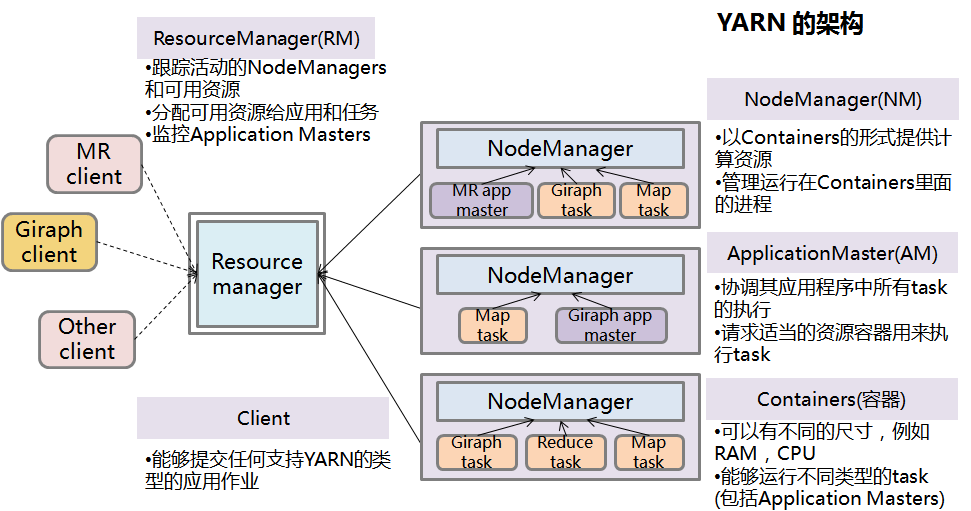
一个全局进程叫ResourceManager(RM)
负责跟踪集群中的活动节点和可用资源,并将它们分配给任务。 -
一种进程叫ApplicationMaster(AM)
这是一个专用的、短暂的进程(每一个应用作业会产生一个AM进程,此进程会随应用结束而终止),用来控制该作业中的任务的执行。这个进程由从节点上运行的 TaskTracker 启动。 -
此外原来的TaskTracker进程现在叫做NodeManager(NM)。
NodeManager 是 TaskTracker 的一种更加普通和高效的版本。没有固定数量的 map 和 reduce slots,NodeManager 拥有许多动态创建的资源容器(Containers)。容器的大小取决于它所包含的资源量,比如内存、CPU等。
ApplicationMaster 可在容器内运行任何类型的任务。例如,MapReduce ApplicationMaster利用一个容器执行来 map 或 reduce task,而 Giraph ApplicationMaster利用一个容器来执行Giraph task。还可以实现一个自定义的 ApplicationMaster 来运行特定的任务,进而发明出一种全新的分布式应用程序框架。
(可以查阅 Apache Twill,它旨在简化 YARN 之上的分布式应用程序的编写。)
这样YARN不再只适用于MR框架的作业,而可以适用于任何分布式框架作业,只要这个框架实现了相应的ApplicationMaster。
在YARN上提交一个作业的过程:
ResourceManager 使用一个可插拔的 Scheduler。Scheduler 仅执行调度,它仅管理谁在何时获取容器资源。
在 ResourceManager 接受一个新应用程序提交时,Scheduler首先选择将用来运行 ApplicationMaster 的容器。
然后相应的NodeManager会在容器中启动 ApplicationMaster,ApplicationMaster将负责此应用程序的整个生命周期。
NodeManager会监视容器中的资源使用情况,举例而言,如果一个容器消耗的内存比最初分配的更多,它会结束该容器。
NodeManager还会监视ApplicationMaster的健康状况,若ApplicationMaster失败,ResourceManager可在一个新容器中重新启动它。
ApplicationMaster会监视容器中自己应用的task的执行情况,若task失败则重新要求NodeManager去执行。
应用程序完成后,ApplicationMaster 会关闭自己并释放自己的容器。
此笔记主要参考IBM资料库:
https://www.ibm.com/developerworks/cn/data/library/bd-yarn-intro/

