


Spark:spark-streaming原理
如下图:
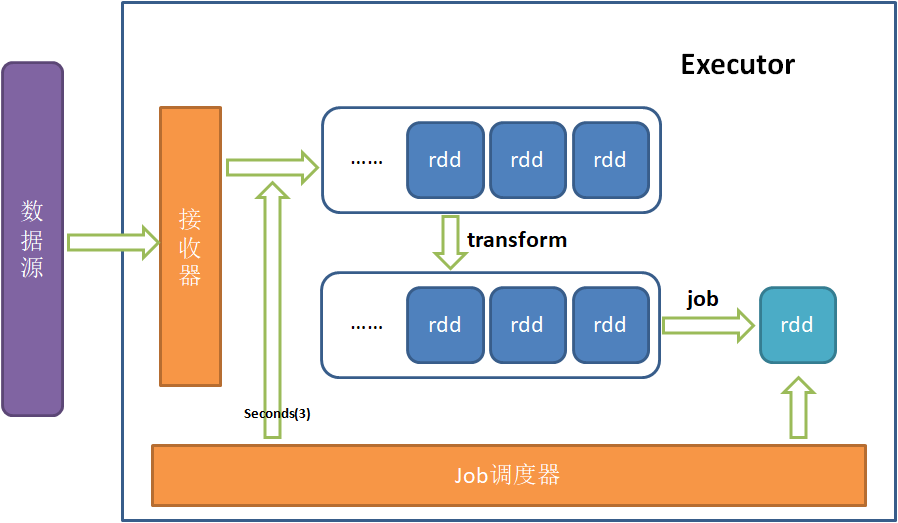
首先StreamingContext中设置的间隔秒数(此处为3秒),只是决定了job调度器每隔多久汇总接受器接收到的数据,作为一个批次处理(一个批次即一个rdd)。
rdd会放入一个未处理的队列,rdd数据可以是空,即没有真正数据,这时候rdd.count == 0。
在DStream上的转化(transform)操作会作用到每一个rdd上,而且其执行和job的生成是并行的,没有关系。
Job调度器会不断的生成job,job生成条件:在转换后的未处理队列里有rdd,就会立即生成job。
job是按照生成的先后顺序串行执行的,即同一时刻只有一个job在执行,并且只要有job且没有正在执行的job就会立即执行。
明白了原理,再看几个配置参数:
config("spark.streaming.backpressure.enabled", true)
控制接收器从数据源接受数据的速率,防止出现这样的情况:
- 接收速度太快,每个批次rdd的数据量太大,造成job执行时间大于批次间隔,从而rdd不断在队列里累计,从而造成内存溢出。
- 接受速度太慢,每个批次rdd的数据量太小,造成job执行时间小于批次间隔,从而没有job执行,一直等待浪费集群资源。
这个选项就是根据job处理速度,不断调节接收器的接收速率,从而不浪费资源又不内存溢出,这个是spark streaming的反压机制。
config("spark.streaming.stopGracefullyOnShutdown", true)
开启了这个选项后,在结束spark streaming程序时,程序不会立即结束,而会如下处理:
-
首先关闭接收器从数据源接受数据,然后job调度器会将接收器接收到但还未汇总的数据汇总为一个批次,放入队列。
-
等待job调度器继续生成job,直到将队列中的所有rdd处理完成。
-
当然上面的等待时长也是有最大值的,一旦超过最大值,不管有没有处理完rdd数据,直接结束程序。
等待最大时长受spark.streaming.gracefulStopTimeout(单位ms)参数控制,默认是10 * batch interval。 -
结束程序。
config("spark.streaming.kafka.maxRatePerPartition", 100)
这个选项决定了每个partition每一秒接受的记录数上限。
如一共10分区,间隔秒数为Seconds(10),则一个rdd.count最大值为:100*10*10=10000。
注意:若同时设置config("spark.streaming.backpressure.enabled", true),接收数据条数会调整,但是只会比spark.streaming.kafka.maxRatePerPartition少,不会比其大。
此参数只适用于Direct模式,Receiver模式下相同功能的参数说明见下面。
接收模式:
-
Receiver模式
Receiver模式下每个input DStream/receiver至少要占用一个core,如果分配给应用的core的数量小于或者等于input DStream/receiver数量,则系统只接收数据, 没有额外的core处理数据。 -
Direct 模式
Direct 模式则没有Receivers,所以接收数据不会占用额外的core。
Receiver模式下spark.streaming.receiver.*形式的配置由于作用于Receivers,在Direct模式下(无Receivers)无效,起代替功能的配置参数为 spark.streaming.kafka.*。
如对于参数spark.streaming.kafka.maxRatePerPartition ——
- Receiver模式下:
spark.streaming.receiver.maxRate(每个接收器每秒接收的最大记录数); - Direct模式下:
spark.streaming.kafka.maxRatePerPartition。

