分库分表如何进行极致的优化
分库分表下极致的优化
题外话
这边说一句题外话,就是ShardingCore目前已经正式加入 NCC 开源组织了,也是希望框架和社区能发展的越来越好,希望为更多.netter提供解决方案和开源组件
介绍
依照惯例首先介绍本期主角:ShardingCore 一款ef-core下高性能、轻量级针对分表分库读写分离的解决方案,具有零依赖、零学习成本、零业务代码入侵
dotnet下唯一一款全自动分表,多字段分表框架,拥有高性能,零依赖、零学习成本、零业务代码入侵,并且支持读写分离动态分表分库,同一种路由可以完全自定义的新星组件框架
你的star和点赞是我坚持下去的最大动力,一起为.net生态提供更好的解决方案
项目地址
本次优化点
直奔主题来讲下本次的极致优化具体是优化了什么,简单说就是CircuitBreaker和FastFail.
断路器CircuitBreaker
我们假设这么一个场景,现在我们有一个订单order表,订单会按照月份进行分片,那么订单表会有如下几个order_202201、order_202202、order_202203、order_202204、order_202205,假设我们有5张表。
首先我们来看一条普通的语句
select * from order where id='xxx' limit 1
这是一条普通的不能在普通的sql了,查询第一条id是xxx的订单,
那么他在分表下面会如何运行
//开启5个线程并发查询
select * from order_202201 where id='xxx' limit 1
select * from order_202202 where id='xxx' limit 1
select * from order_202203 where id='xxx' limit 1
select * from order_202204 where id='xxx' limit 1
select * from order_202205 where id='xxx' limit 1
//查询出来的结果在内存中进行聚合成一个list集合
//然后在对这个list集合进行第一条的获取
list.Where(o=>o is not null).FirstOrDefault()
这个操作我相信很多同学都是可以了解的,稍微熟悉点分表分库的同学应该都知道这是基本操作了,但是这个操作看似高效(时间上)但是在连接数上而言并不是那么的高效,因为同一时间需要开打的连接数将由5个
那么在这个背景下ShardingCore参考ShardingSphere 提供了更加友好的连接控制和内存聚合模式ConnectionMode

这个张图上我们可以清晰的看到不同的数据库直接才用了一个并发限制,比如设置的是2,那么在相同库里面的查询将是每2个一组,进行查询,这样可以控制在同一个数据库下的连接数,进而解决了客户端连接模式下的连接数消耗猛烈的一个弊端。
//开启5个线程并发查询
{
//并行
select * from order_202201 where id='xxx' limit 1
select * from order_202202 where id='xxx' limit 1
}
//串行
{
//并行
select * from order_202203 where id='xxx' limit 1
select * from order_202204 where id='xxx' limit 1
}
//串行
{
select * from order_202205 where id='xxx' limit 1
}
//查询出来的结果在内存中进行聚合成一个list集合
//然后在对这个list集合进行第一条的获取
list.Where(o=>o is not null).FirstOrDefault()
到目前为止这边已经对分片的查询优化到了一个新的高度。但是虽然我们优化了连接数的处理,但是就查询速度而言基本上是没有之前的那么快,可以说和你分组的组数成线性增加时间的消耗。
所以到此为止ShardingCore又再一次进化出了全新的翅膀CircuitBreaker断路器,我们继续往下看
我们现在的sql是
select * from order where id='xxx' limit 1
那么如果我们针对这个sql进行优化呢,譬如
select * from order where id='xxx' order by create_time desc limit 1
同样是查询第一条,添加了一个order排序那么情况就会大大的不一样,首先我们来观察我们的分片查询
//开启5个线程并发查询
-- select * from order_202201 where id='xxx' order by create_time desc limit 1
-- select * from order_202202 where id='xxx' order by create_time desc limit 1
-- select * from order_202203 where id='xxx' order by create_time desc limit 1
-- select * from order_202204 where id='xxx' order by create_time desc limit 1
-- select * from order_202205 where id='xxx' order by create_time desc limit 1
-- 抛弃上述写法
select * from order_202205 where id='xxx' order by create_time desc limit 1
select * from order_202204 where id='xxx' order by create_time desc limit 1
select * from order_202203 where id='xxx' order by create_time desc limit 1
select * from order_202202 where id='xxx' order by create_time desc limit 1
select * from order_202201 where id='xxx' order by create_time desc limit 1
如果在连接模式下那么他们将会是2个一组,那么我们在查询第一组的结果后是否就可以直接抛弃掉下面的所有查询,也就是我们只需要查询
select * from order_202205 where id='xxx' order by create_time desc limit 1
select * from order_202204 where id='xxx' order by create_time desc limit 1
只要他们是有返回一个以上的数据那么本次分片查询将会被终止,ShardingCore目前的大杀器,本来年前已经开发完成了,奈何太懒只是发布了版本并没有相关的说明和使用方法
CircuitBreaker
断路器,它具有类似拉闸中断操作的功能,这边简单说下linq操作下的部分方法的断路器点在哪里
| 方法名 | 是否支持中断操作 | 中断条件 |
|---|---|---|
| First | 支持 | 按顺序查询到第一个时就可以放弃其余查询 |
| FirstOrDefault | 支持 | 按顺序查询到第一个时就可以放弃其余查询 |
| Last | 支持 | 按顺序倒叙查询到第一个时就可以放弃其余查询 |
| LastOrDefault | 支持 | 按顺序倒叙查询到第一个时就可以放弃其余查询 |
| Single | 支持 | 查询到两个时就可以放弃,因为元素个数大于1个了需要抛错 |
| SingleOrDefault | 支持 | 查询到两个时就可以放弃,因为元素个数大于1个了需要抛错 |
| Any | 支持 | 查询一个结果true就可以放弃其余查询 |
| All | 支持 | 查询到一个结果fasle就可以放弃其余查询 |
| Contains | 支持 | 查询一个结果true就可以放弃其余查询 |
| Count | 不支持 | -- |
| LongCount | 不支持 | -- |
| Max | 支持 | 按顺序最后一条并且查询最大字段是分片顺序同字段是,max的属性只需要查询一条记录 |
| Min | 支持 | 按顺序第一条并且查询最小字段是分片顺序同字段,min的属性只需要查询一条记录 |
| Average | 不支持 | -- |
| Sum | 不支持 | -- |
这边其实只有三个操作是任何状态下都可以支持中断,其余操作需要在额外条件顺序查询的情况下才可以,并且我们本次查询分片涉及到过多的后缀表那么性能和资源的利用将会大大提升
查询配置
废话不多说我们开始以mysql作为本次案例(不要问我为什么不用SqlServer,因为写文章的时候我是mac电脑),这边我们创建一个项目新建一个订单按月分表
新建项目
安装依赖

添加订单表和订单表映射
public class Order
{
public string Id { get; set; }
public string Name { get; set; }
public DateTime Createtime { get; set; }
}
public class OrderMap : IEntityTypeConfiguration<Order>
{
public void Configure(EntityTypeBuilder<Order> builder)
{
builder.HasKey(o => o.Id);
builder.Property(o => o.Id).HasMaxLength(32).IsUnicode(false);
builder.Property(o => o.Name).HasMaxLength(255);
builder.ToTable(nameof(Order));
}
}
添加DbContext
public class ShardingDbContext:AbstractShardingDbContext,IShardingTableDbContext
{
public ShardingDbContext(DbContextOptions<ShardingDbContext> options) : base(options)
{
}
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
base.OnModelCreating(modelBuilder);
modelBuilder.ApplyConfiguration(new OrderMap());
}
public IRouteTail RouteTail { get; set; }
}
添加订单分片路由
从5月份开始按创建时间建表
public class OrderRoute:AbstractSimpleShardingMonthKeyDateTimeVirtualTableRoute<Order>
{
public override void Configure(EntityMetadataTableBuilder<Order> builder)
{
builder.ShardingProperty(o => o.Createtime);
}
public override bool AutoCreateTableByTime()
{
return true;
}
public override DateTime GetBeginTime()
{
return new DateTime(2021, 5, 1);
}
}
启动配置
简单的配置启动创建表和库,并且添加种子数据
ILoggerFactory efLogger = LoggerFactory.Create(builder =>
{
builder.AddFilter((category, level) => category == DbLoggerCategory.Database.Command.Name && level == LogLevel.Information).AddConsole();
});
builder.Services.AddControllers();
builder.Services.AddShardingDbContext<ShardingDbContext>()
.AddEntityConfig(op =>
{
op.CreateShardingTableOnStart = true;
op.EnsureCreatedWithOutShardingTable = true;
op.AddShardingTableRoute<OrderRoute>();
op.UseShardingQuery((conStr, b) =>
{
b.UseMySql(conStr, new MySqlServerVersion(new Version())).UseLoggerFactory(efLogger);
});
op.UseShardingTransaction((conn, b) =>
{
b.UseMySql(conn, new MySqlServerVersion(new Version())).UseLoggerFactory(efLogger);
});
}).AddConfig(op =>
{
op.ConfigId = "c1";
op.AddDefaultDataSource("ds0", "server=127.0.0.1;port=3306;database=db2;userid=root;password=root;");
op.ReplaceTableEnsureManager(sp=>new MySqlTableEnsureManager<ShardingDbContext>());
}).EnsureConfig();
var app = builder.Build();
app.Services.GetRequiredService<IShardingBootstrapper>().Start();
using (var scope=app.Services.CreateScope())
{
var shardingDbContext = scope.ServiceProvider.GetRequiredService<ShardingDbContext>();
if (!shardingDbContext.Set<Order>().Any())
{
var begin = new DateTime(2021, 5, 2);
List<Order> orders = new List<Order>(8);
for (int i = 0; i < 8; i++)
{
orders.Add(new Order()
{
Id = i.ToString(),
Name = $"{begin:yyyy-MM-dd HH:mm:ss}",
Createtime = begin
});
begin = begin.AddMonths(1);
}
shardingDbContext.AddRange(orders);
shardingDbContext.SaveChanges();
}
}
app.UseAuthorization();
app.MapControllers();
app.Run();
这边默认连接模式的分组是Environment.ProcessorCount
编写查询
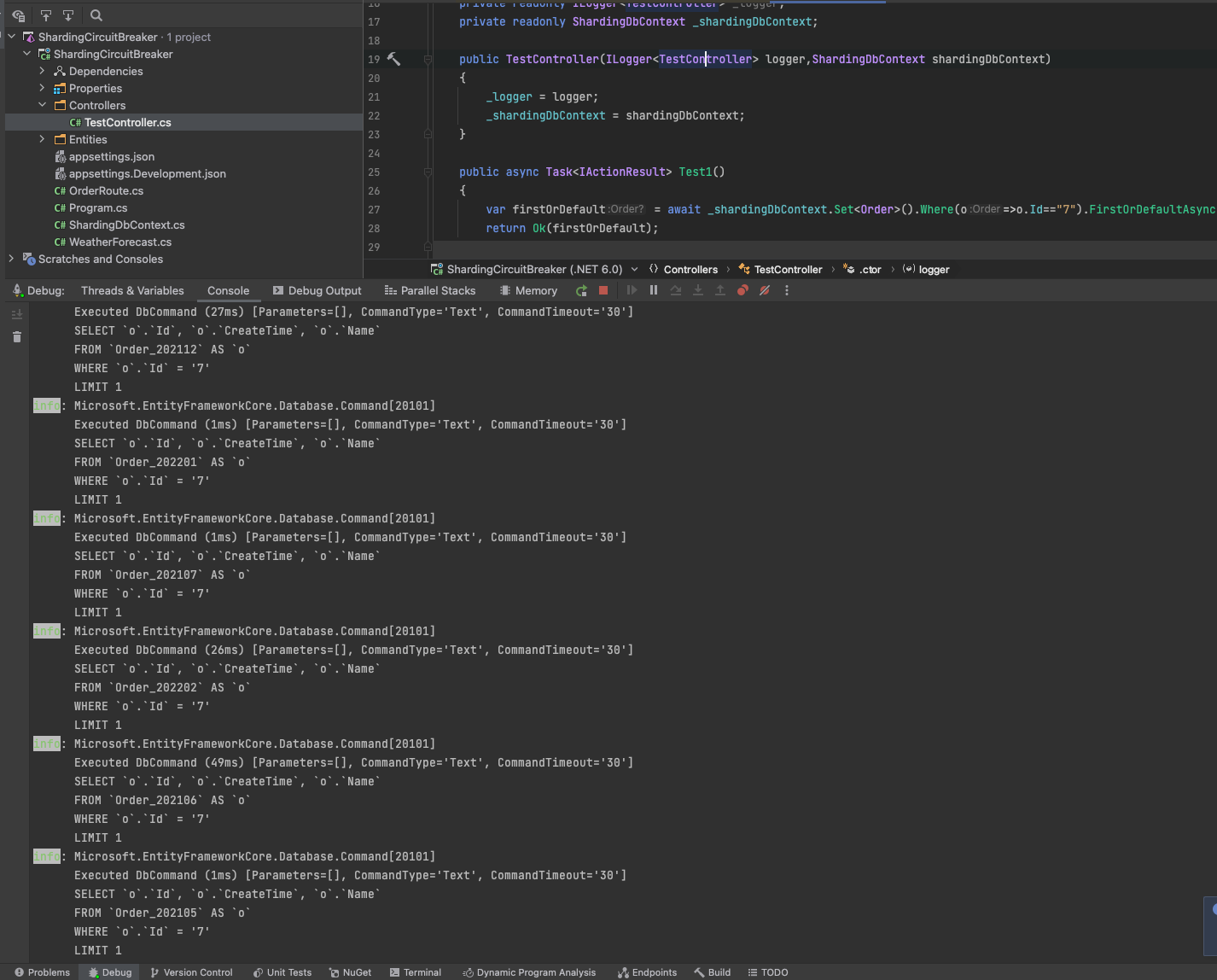
没有配置的情况下那么这个查询将是十分糟糕
接下来我们将配置Order的查询
public class OrderQueryConfiguration:IEntityQueryConfiguration<Order>
{
public void Configure(EntityQueryBuilder<Order> builder)
{
//202105,202106...是默认的顺序,false表示使用反向排序,就是如果存在分片那么分片的tail将进行反向排序202202,202201,202112,202111....
builder.ShardingTailComparer(Comparer<string>.Default, false);
//true:当前属性正序和comparer正序一样,false:当前属性倒序和comparer正序一样
//sameAsShardingTailComparer,true表示当前添加的属性也是采用倒序,false表示当前添加的属性使用正序
builder.AddOrder(o => o.CreateTime,true);
//配置当不存在Order的时候如果我是FirstOrDefault那么将采用和ShardingTailComparer相反的排序执行因为是false
//默认从最早的表开始查询
builder.AddDefaultSequenceQueryTrip(false, CircuitBreakerMethodNameEnum.FirstOrDefault);
////默认从最近表开始查询
//builder.AddDefaultSequenceQueryTrip(true, CircuitBreakerMethodNameEnum.FirstOrDefault);
//内部配置单表查询的FirstOrDefault connections limit限制为1
builder.AddConnectionsLimit(1, LimitMethodNameEnum.FirstOrDefault);
}
}
public class OrderRoute:AbstractSimpleShardingMonthKeyDateTimeVirtualTableRoute<Order>
{
//......
//配置路由才用这个对象查询
public override IEntityQueryConfiguration<Order> CreateEntityQueryConfiguration()
{
return new OrderQueryConfiguration();
}
}
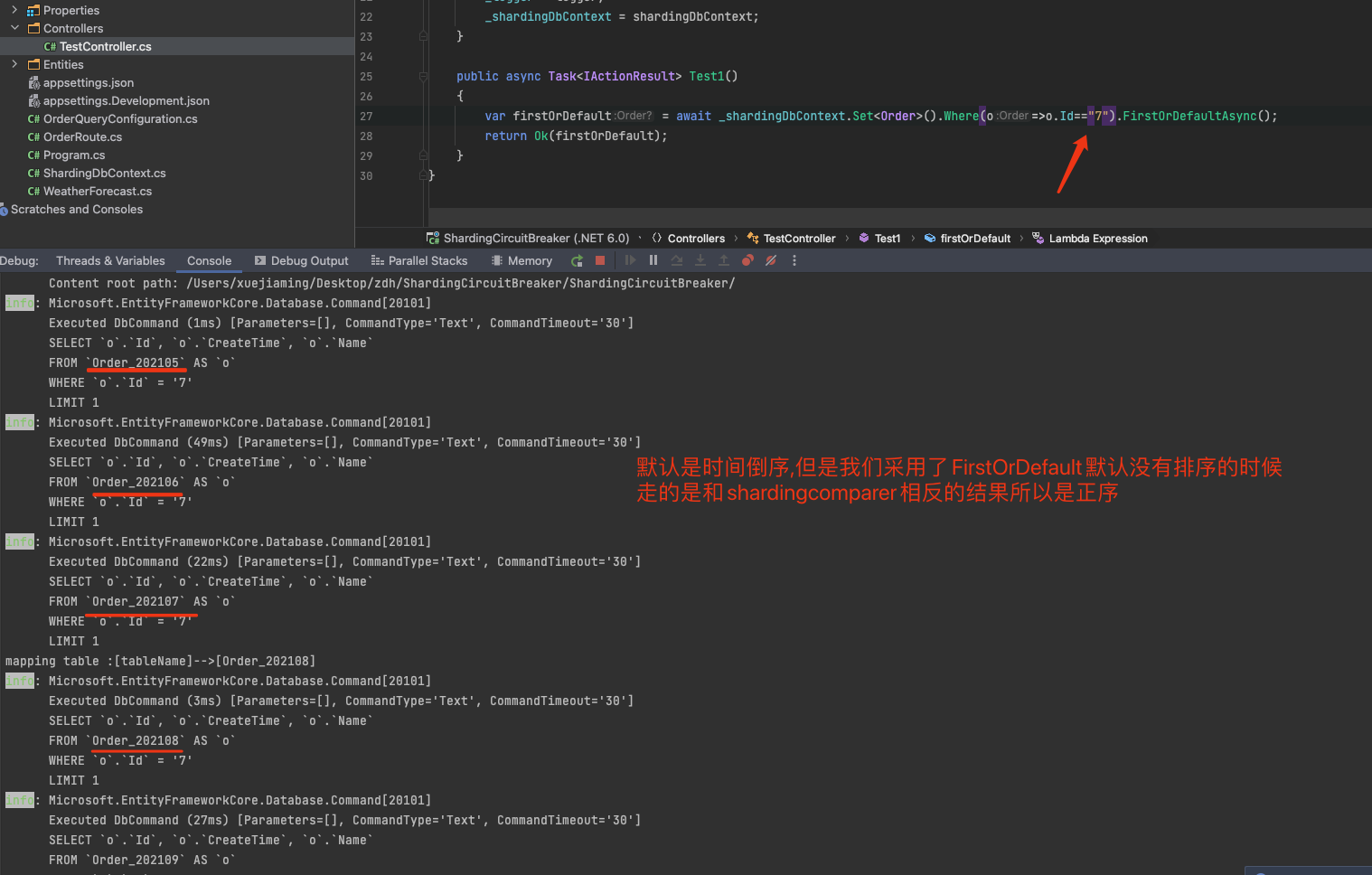
带配置的Order

现在我们将默认的配置修改回正确
//不合适因为一般而言我们肯定是查询最新的所以应该和ShardingComparer一样都是倒序查询
//builder.AddDefaultSequenceQueryTrip(false, CircuitBreakerMethodNameEnum.FirstOrDefault);
builder.AddDefaultSequenceQueryTrip(true, CircuitBreakerMethodNameEnum.FirstOrDefault);
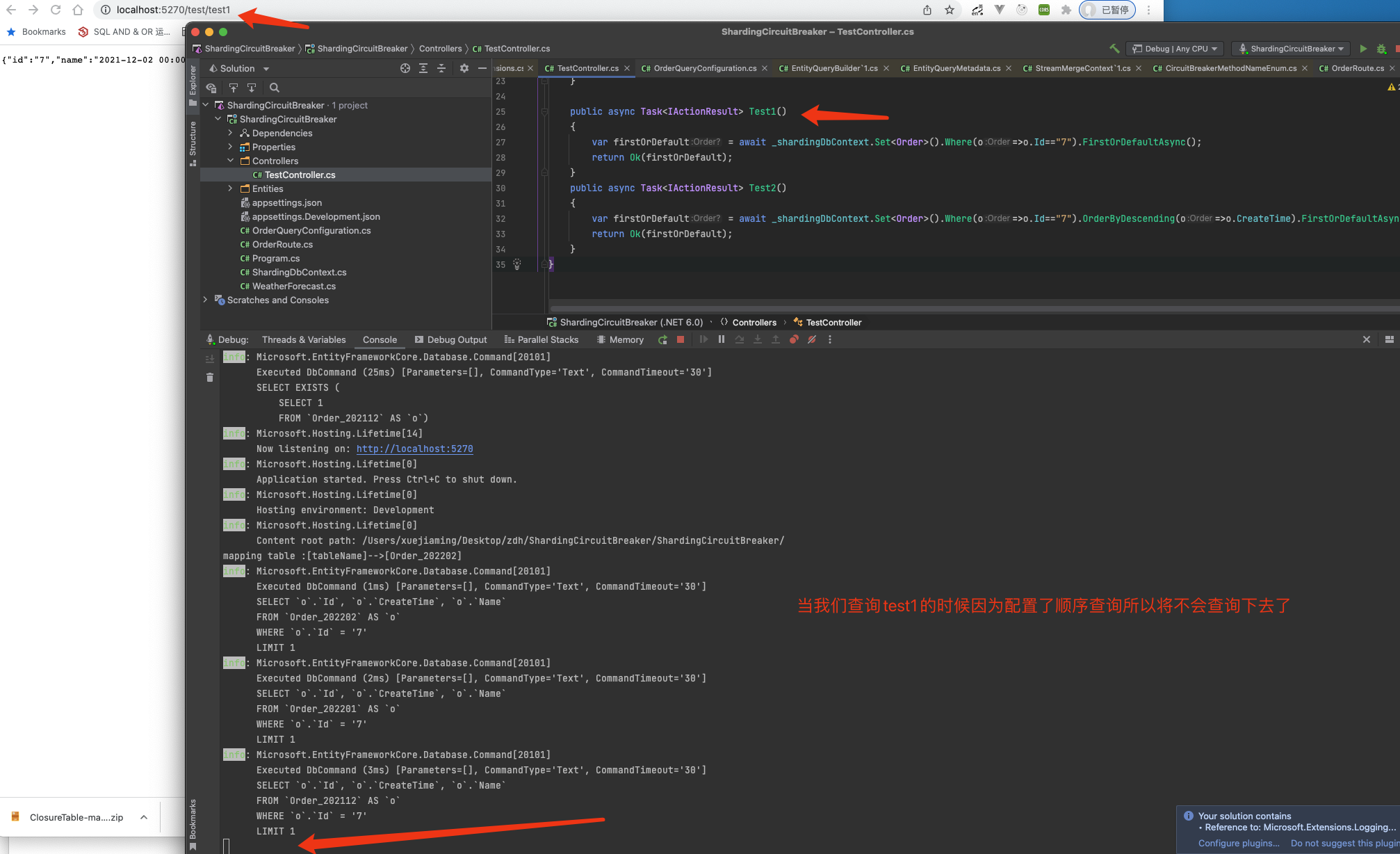
当然如果你希望本次查询不使用配置的连接数限制可以进行如下操作
_shardingDbContext.Set<Order>().UseConnectionMode(2).Where(o=>o.Id=="7").FirstOrDefaultAsync();
结论:当我们配置了默认分片表应该以何种顺序进行分片聚合时,如果相应的查询方法也进行了配置那么将这种查询视为顺序查询,
所有的顺序查询都符合上述表格模式,遇到对应的将直接进行熔断,不在进行后续的处理直接返回,保证高性能和防止无意义的查询。
快速失败FastFail
顾名思义就是快速失败,但是很多小伙伴可能不清楚这个快速失败的意思,失败就是失败了为什么有快速失败一说,因为ShardingCore内部的本质是将一个sql语句进行才分N条然后并行执行
-- 普通sql
select * from order where id='1' or id='2'
-- 分片sql
select * from order_1 where id='1' or id='2'
select * from order_2 where id='1' or id='2'
-- 分别对这两个sql进行并行执行
在正常情况下程序是没有什么问题的,但是由于程序是并行查询后迭代聚合所以会带来一个问题,就是假设执行order_1的线程挂掉了,那么Task.WhenAll会一致等待所有线程完成,然后抛出响应的错误,
那么这在很多情况下等于其余线程都在多无意义的操作,各自管各自。
static async Task Main(string[] args)
{
try
{
await Task.WhenAll(DoSomething1(), DoSomething2());
Console.WriteLine("execute success");
}
catch
{
Console.WriteLine("error");
}
Console.ReadLine();
}
static async Task<int> DoSomething1()
{
for (int i = 0; i < 10; i++)
{
if (i == 2)
throw new Exception("111");
await Task.Delay(1000);
Console.WriteLine("DoSomething1"+i);
}
return 1;
}
static async Task<int> DoSomething2()
{
for (int i = 0; i < 10; i++)
{
await Task.Delay(1000);
Console.WriteLine("DoSomething2"+i);
}
return 1;
}
代码很简单就是Task.WhenAll的时候执行两个委托方法,然后让其中一个快速抛异常的情况下看看是否马上返回
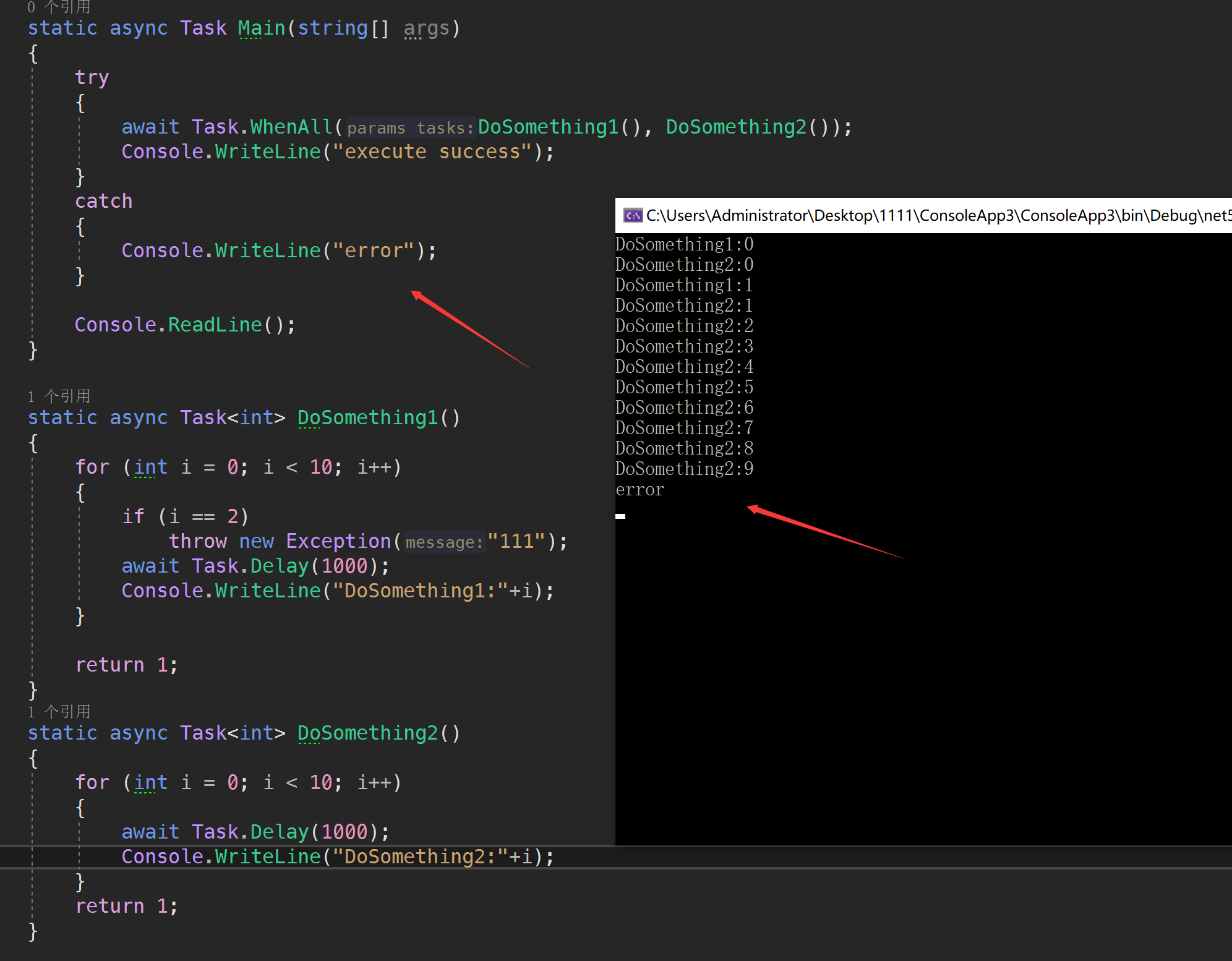
结果是TaskWhenAll哪怕出现异常也需要等待所有的线程完成任务,这会在某些情况下浪费不必要的性能,所以这边ShardingCore参考资料采用了FastFail版本的
public static Task WhenAllFailFast(params Task[] tasks)
{
if (tasks is null || tasks.Length == 0) return Task.CompletedTask;
// defensive copy.
var defensive = tasks.Clone() as Task[];
var tcs = new TaskCompletionSource();
var remaining = defensive.Length;
Action<Task> check = t =>
{
switch (t.Status)
{
case TaskStatus.Faulted:
// we 'try' as some other task may beat us to the punch.
tcs.TrySetException(t.Exception.InnerException);
break;
case TaskStatus.Canceled:
// we 'try' as some other task may beat us to the punch.
tcs.TrySetCanceled();
break;
default:
// we can safely set here as no other task remains to run.
if (Interlocked.Decrement(ref remaining) == 0)
{
// get the results into an array.
tcs.SetResult();
}
break;
}
};
foreach (var task in defensive)
{
task.ContinueWith(check, default, TaskContinuationOptions.ExecuteSynchronously, TaskScheduler.Default);
}
return tcs.Task;
}
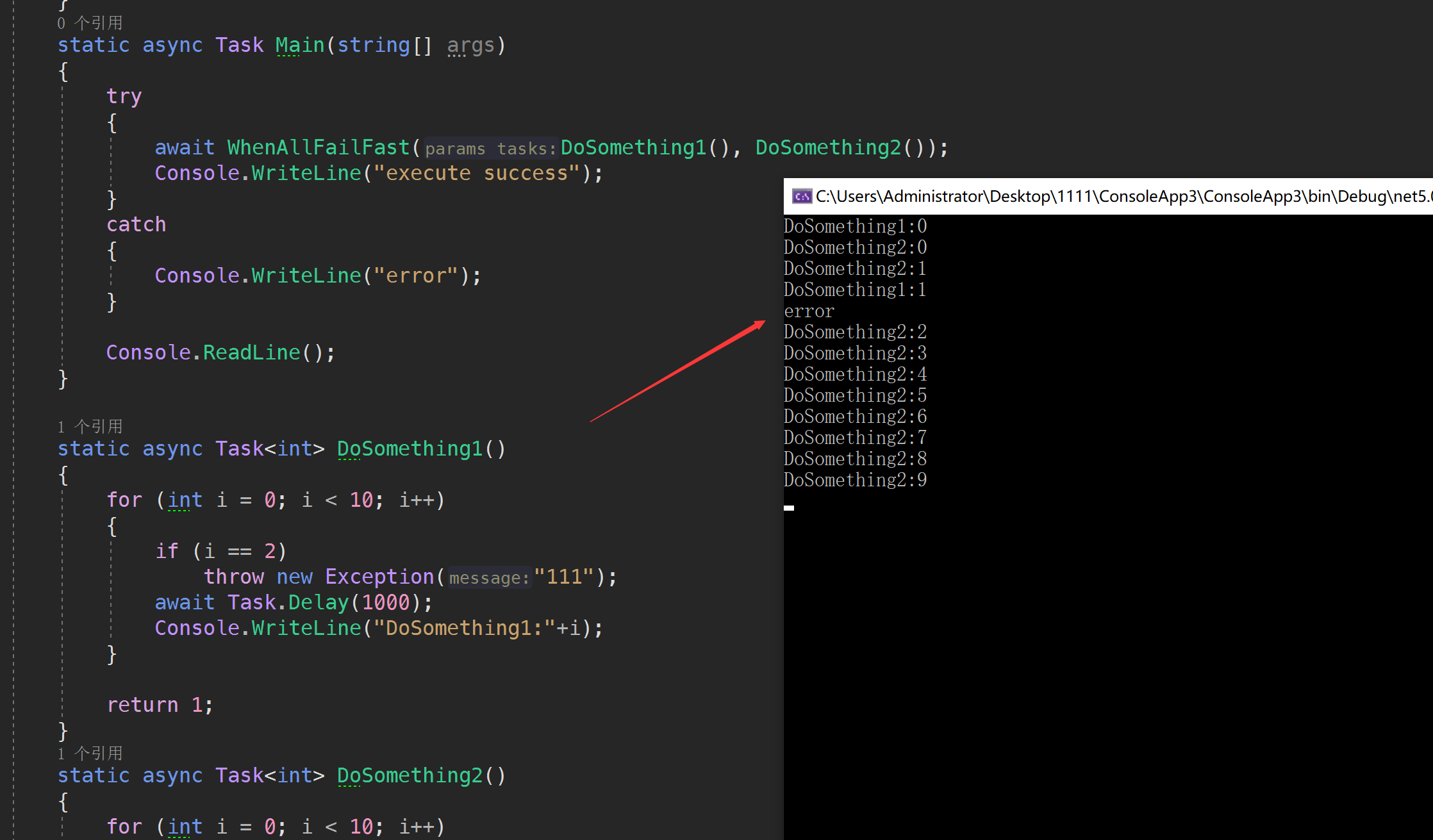
采用failfast后当前主线程会直接在错误时返回,其余线程还是继续执行,需要自行进行canceltoken.cancel或者通过共享变量来取消执行
总结
ShardngCore目前还在不断努力成长中,也希望各位多多包涵可以在使用中多多提出响应的意见和建议
参考资料
下期预告
下一篇我们将讲解如何让流式聚合支持更多的sql查询,如何将不支持的sql降级为union all
分表分库组件求赞求star
您的支持是开源作者能坚持下去的最大动力
- Github ShardingCore
QQ群:771630778
个人QQ:326308290(欢迎技术支持提供您宝贵的意见)
个人邮箱:326308290@qq.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号