

IDEA研究院
粤港澳大湾区数字经济研究院(International Digital Economy Academy,简称“IDEA研究院”), https://idea.edu.cn/
论文阅读平台ReadPaper,https://idea.edu.cn/readpaper.html
目前NLP方向的工作已经公开很多,可以使用的模型涉及到了NLU、NLG、多模态等领域。
| 系列名称 | 需求 | 适用任务 | 参数规模 | 备注 |
|---|---|---|---|---|
| 二郎神 | 通用 | 语言理解 | 9千万-39亿参数 | 处理理解任务,拥有开源时最大的中文bert模型,2021登顶FewCLUE和ZeroCLUE |
| 闻仲 | 通用 | 语言生成 | 1亿-35亿参数 | 专注于生成任务,提供了多个不同参数量的生成模型,例如GPT2等 |
| 燃灯 | 通用 | 语言转换 | 7千万-7亿参数 | 处理各种从源文本转换到目标文本类型的任务,例如机器翻译,文本摘要等 |
| 太乙 | 特定 | 多模态 | 8千万-1亿参数 | 应用于跨模态场景,包括文本图像生成,蛋白质结构预测, 语音-文本表示等 |
| 余元 | 特定 | 领域 | 1亿-35亿参数 | 应用于领域,如医疗,金融,法律,编程等。拥有目前最大的开源GPT2医疗模型 |
余元是医疗领域的模型
数据集列表
- AFQMC 蚂蚁金融语义相似度
- LSCTC 中文文本摘要
- NLI 阅读理解合集
- Sentiment 情感分析合集
- Similarity 文本相似度合集
- WuDao_180G 悟道开源预训练数据集
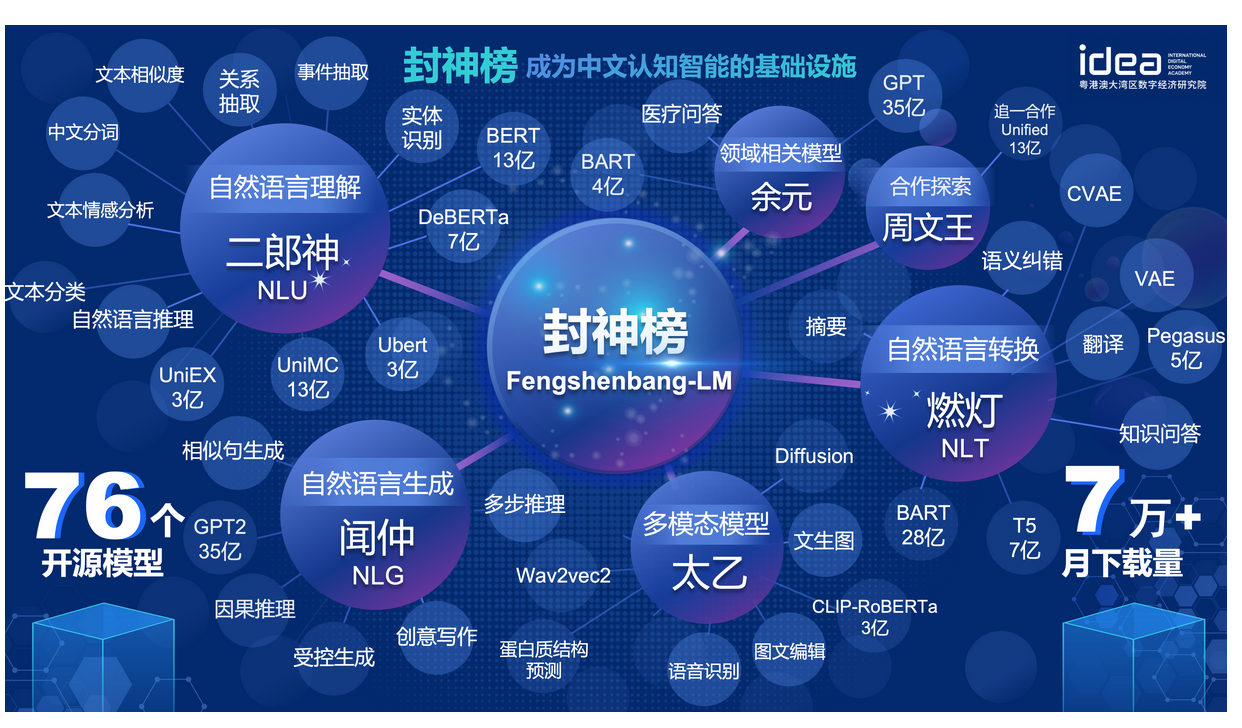

Fengshenbang-LM(封神榜大模型)是IDEA研究院认知计算与自然语言研究中心主导的大模型开源体系,成为中文认知智能的基础设施。
https://github.com/IDEA-CCNL/Fengshenbang-LM
首个中文Stable Diffusion模型开源,IDEA研究院封神榜团队开启中文AI艺术时代,https://mp.weixin.qq.com/s/WrzkiJOxqNcFpdU24BKbMA,生成图片
封神榜 中文语言预训练模型,https://fengshenbang-doc.readthedocs.io/zh/latest/
本文仅供学习交流使用!!
