

MultimodalSum学习笔记
自监督的多模态观点摘要
Self-Supervised Multimodal Opinion Summarization
韩国一家游戏公司的工作,ncsoft
2021.5,ACL

https://arxiv.org/pdf/2105.13135
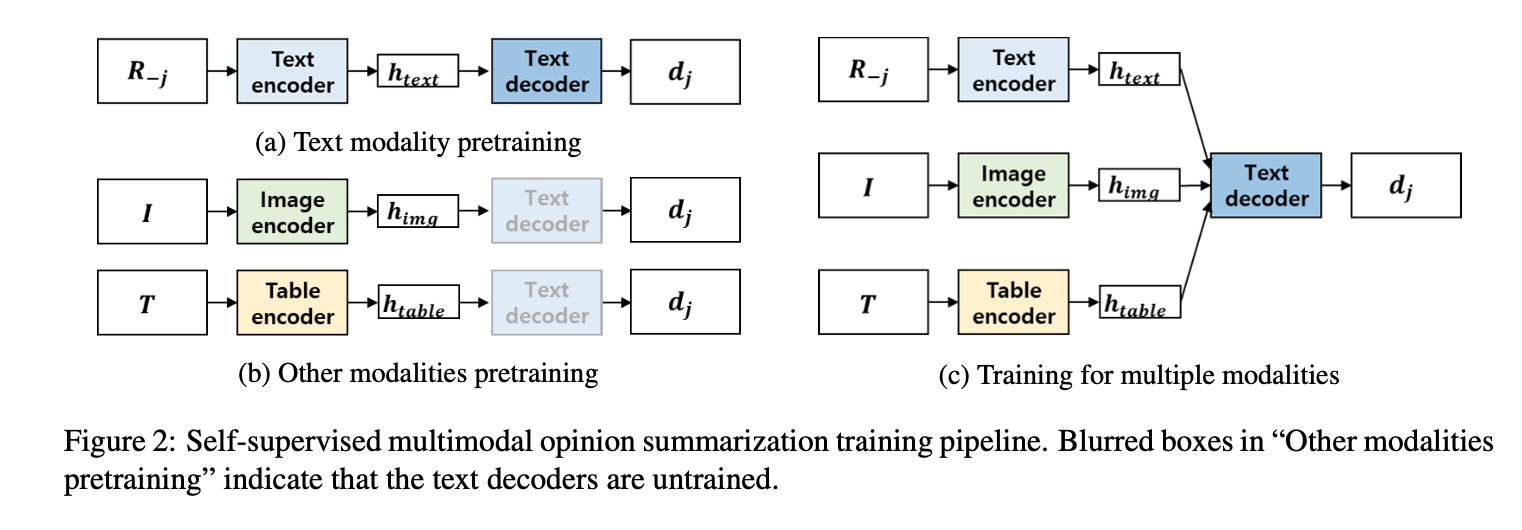
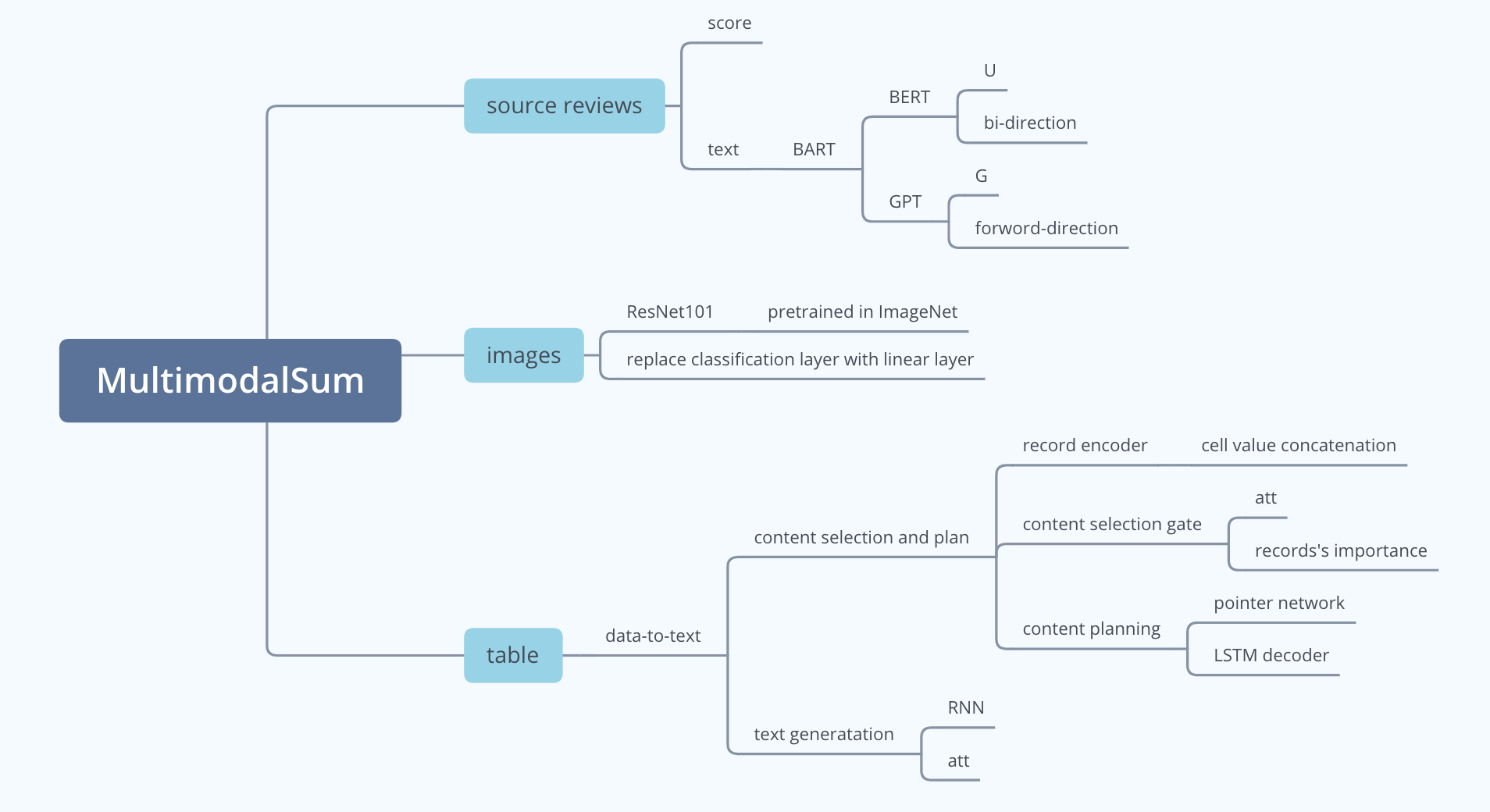
多模态:文本、图像、表格,分别建立模型
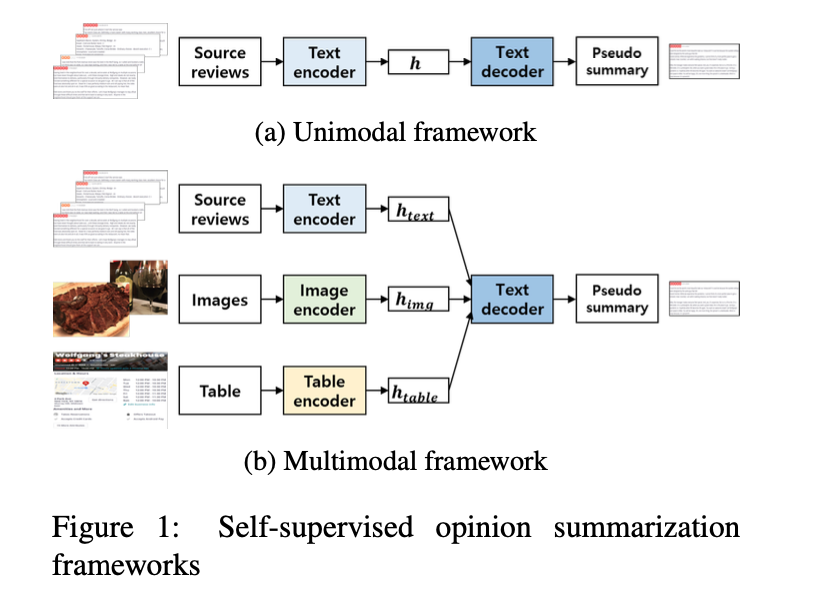
问题定义

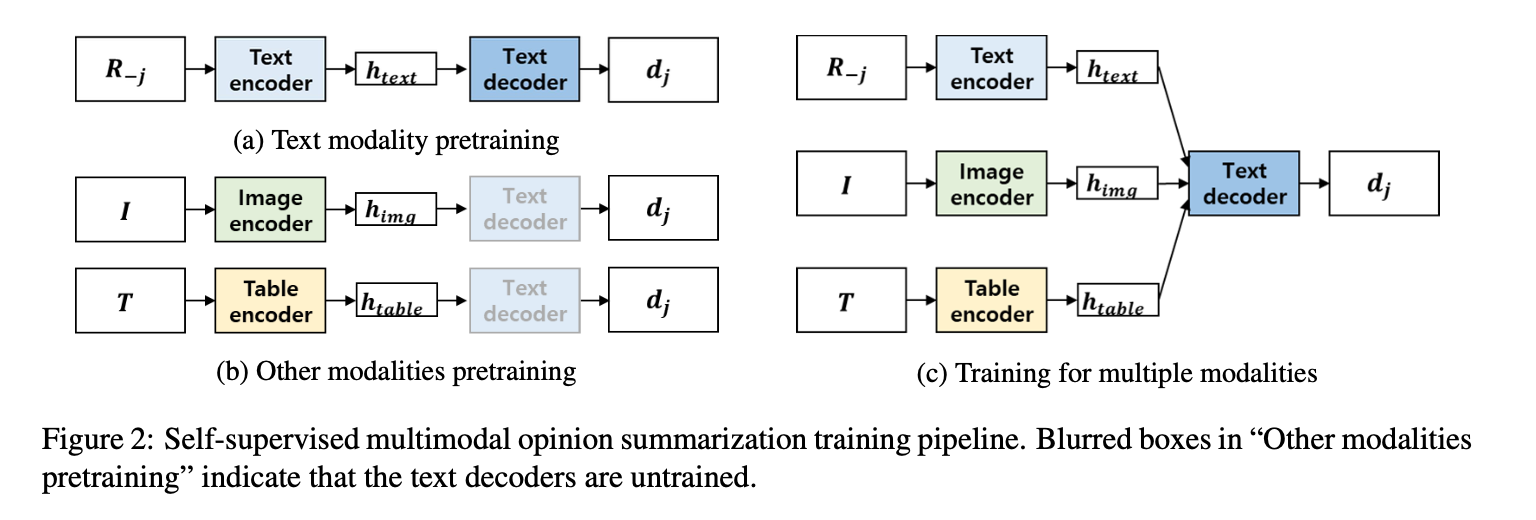
1 Text Encoder and Decoder
\[h_{text} = BART_{enc}(D_{-�j}),
d_{j} = BART_{dec}(h_{text}),
\]
2 Image Encoder
\[h_{img} = ResNet101(I)W_{img},
\]
3 Table Encoder
\[f_{k} =ReLU([n_{k};v_{k}]W_{f} +b_{f}), h_{table} = F W_{table},
\]
多模态融合


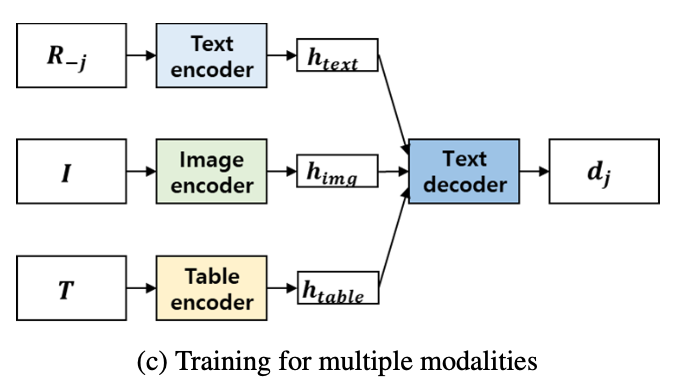
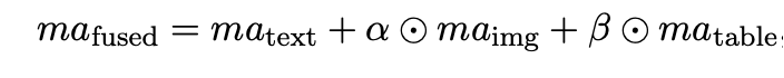
整体流程
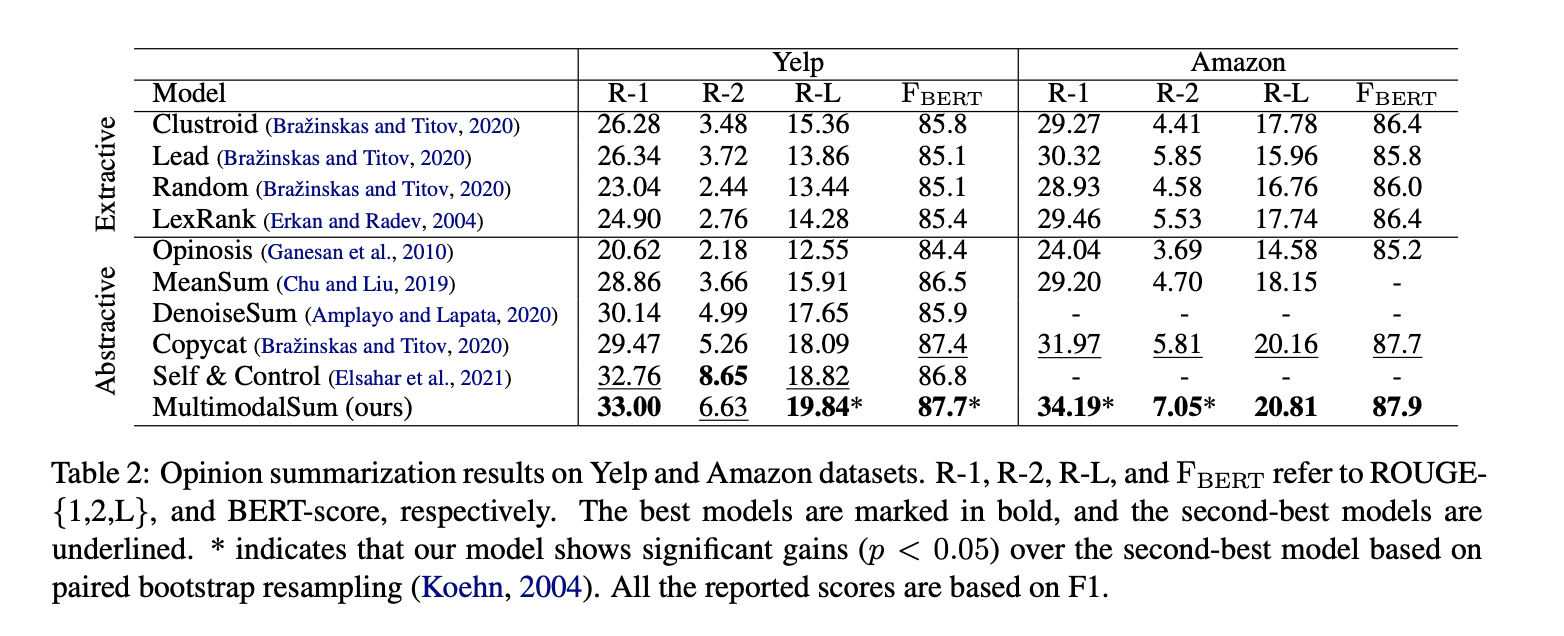
实验
代码
https://github.com/nc-ai/knowledge/tree/master/publications/MultimodalSum
