

学习笔记(11)- 文本生成RNNLG
https://github.com/shawnwun/RNNLG
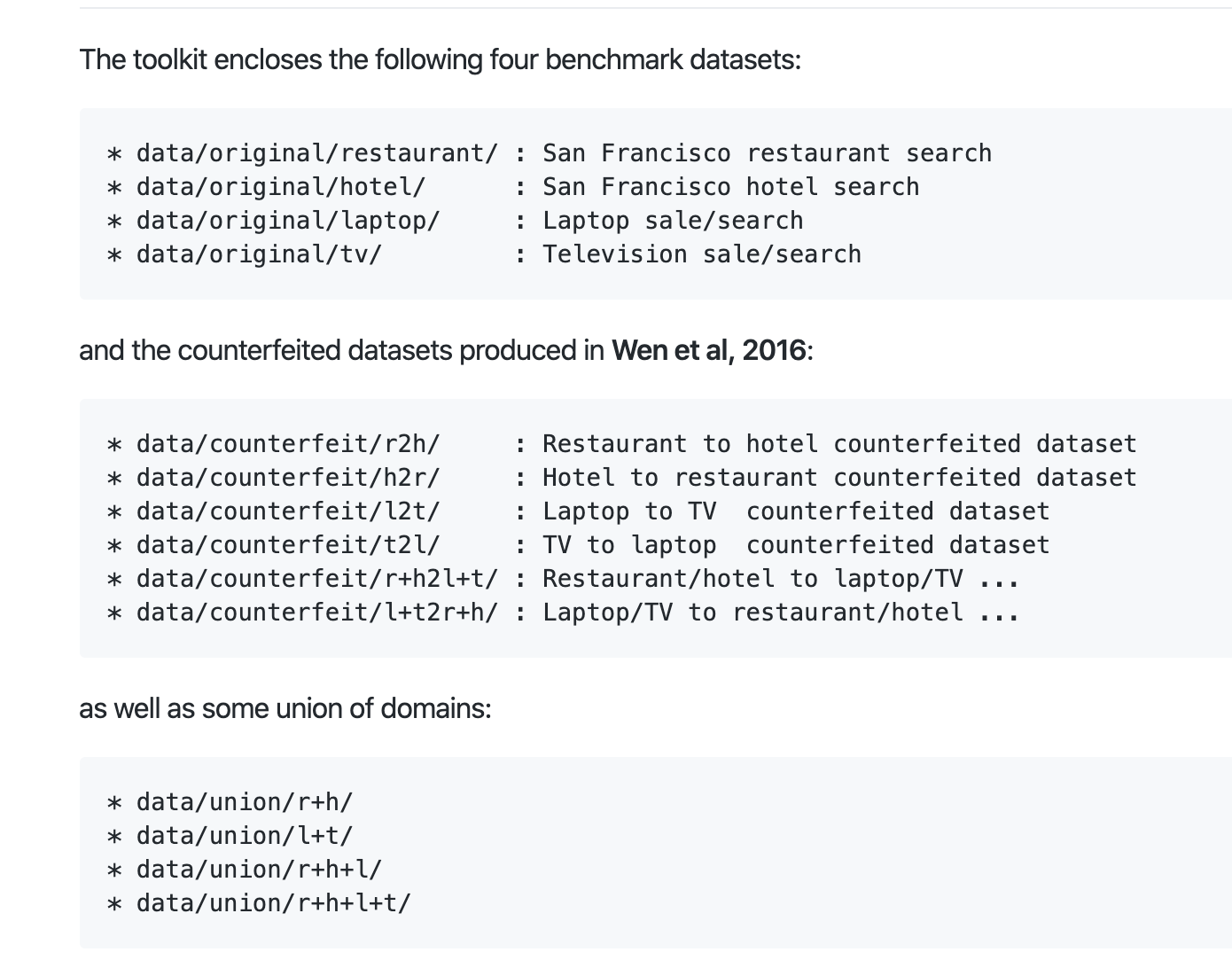
数据集
给出了4个行业的语料,餐馆、酒店、电脑、电视,及其组合数据。
数据格式

任务
根据给定格式的命令,生成自然语言。
方法、模型、策略
作者给出了5种模型,2种训练(优化)策略、2种解码方式
* Model
- (knn) kNN generator:
k-nearest neighbor example-based generator, based on MR similarty.
- (ngram) Class-based Ngram generator [Oh & Rudnicky, 2000]:
Class-based language model generator by utterance class partitions.
- (hlstm) Heuristic Gated LSTM [Wen et al, 2015a]:
An MR-conditioned LSTM generator with heuristic gates.
- (sclstm) Semantically Conditioned LSTM [Wen et al, 2015b]:
An MR-conditioned LSTM generator with learned gates.
- (encdec) Attentive Encoder-Decoder LSTM [Wen et al, 2015c]:
An encoder-decoder LSTM with slot-value level attention.
* Training Strategy
- (ml) Maximum Likehood Training, using token cross-entropy
- (dt) Discriminative Training (or Expected BLEU training) [Wen et al, 2016]
* Decoding Strategy
- (beam) Beam search
- (sample) Random sampling
快速开始
需要python2环境,依赖:
* Theano 0.8.2 and accompanying packages such as numpy, scipy ...
* NLTK 3.0.0
创建虚机,Python2
virtualenv env
source env/bin/activate
pip install theano==0.8.2
pip install nltk==3.0.0
训练:python main.py -config config/sclstm.cfg -mode train
测试:python main.py -config config/sclstm.cfg -mode test

配置文件和参数
从上面的训练和测试的命令可以看出,参数在config目录下的文件配置,看看config/sclstm.cfg文件的内容
[learn] // parameters for training
lr = 0.1 : learning rate of SGD.
lr_decay = 0.5 : learning rate decay.
lr_divide = 3 : the maximum number of times when validation gets worse.
for early stopping.
beta = 0.0000001 : regularisation parameter.
random_seed = 5 : random seed.
min_impr = 1.003 : the relative minimal improvement allowed.
debug = True : debug flag
llogp = -100000000 : log prob in the last epoch
[train_mode]
mode = all : training mode, currently only support 'all'
obj = ml : training objective, 'ml' or 'dt'
###################################
* Training Strategy
- (ml) Maximum Likehood Training, using token cross-entropy
- (dt) Discriminative Training (or Expected BLEU training) [Wen et al, 2016]
###################################
gamma = 5.0 : hyperparameter for DT training
batch = 1 : batch size
[generator] // structure for generator
type = sclstm : the model type, [hlstm|sclstm|encdec]
hidden = 80 : hidden layer size
[data] // data and model file
domain = restaurant 作者给出4种领域:餐馆、酒店、电脑、电视
train = data/original/restaurant/train.json
valid = data/original/restaurant/valid.json
test = data/original/restaurant/test.json
vocab = resource/vocab 词典
percentage = 100 : the percentage of train/valid considered
wvec = vec/vectors-80.txt : pretrained word vectors 预训练的词向量,有多个维度
model = model/sclstm-rest.model : the produced model path 生成的模型文件名称
[gen] // generation parameters, decode='beam' or 'sample'
topk = 5 : the N-best list returned
overgen = 20 : number of over-generation
beamwidth = 10 : the beam width used to decode utterances
detectpairs = resource/detect.pair : the mapping file for calculating the slot error rate 见下文
verbose = 1 : verbose level of the model, not supported yet
decode = beam : decoding strategy, 'beam' or 'sample'
Below are knn/ngram specific parameters:
* [ngram]
- ngram : the N of ngram
- rho : number of slots considered to partition the dataset
结果
我在自己机器试了一下
inform(name=fresca;phone='4154472668')
Penalty TSER ASER Gen
0.0672 0 0 the phone number for fresca is 4154472668
0.1272 0 0 fresca s phone number is 4154472668
0.1694 0 0 the phone number of fresca is 4154472668
0.1781 0 0 the phone number for the fresca is 4154472668
0.2153 0 0 the phone number to fresca is 4154472668
文件resource/detect.pair
{
"general" : {
"address" : "SLOT_ADDRESS",
"area" : "SLOT_AREA",
"count" : "SLOT_COUNT",
"food" : "SLOT_FOOD",
"goodformeal": "SLOT_GOODFORMEAL",
"name" : "SLOT_NAME",
"near" : "SLOT_NEAR",
"phone" : "SLOT_PHONE",
"postcode" : "SLOT_POSTCODE",
"price" : "SLOT_PRICE",
"pricerange" : "SLOT_PRICERANGE",
"battery" : "SLOT_BATTERY",
"batteryrating" : "SLOT_BATTERYRATING",
"design" : "SLOT_DESIGN",
"dimension" : "SLOT_DIMENSION",
"drive" : "SLOT_DRIVE",
"driverange" : "SLOT_DRIVERANGE",
"family" : "SLOT_FAMILY",
"memory" : "SLOT_MEMORY",
"platform" : "SLOT_PLATFORM",
"utility" : "SLOT_UTILITY",
"warranty" : "SLOT_WARRANTY",
"weight" : "SLOT_WEIGHT",
"weightrange": "SLOT_WEIGHTRANGE",
"hdmiport" : "SLOT_HDMIPORT",
"ecorating" : "SLOT_ECORATING",
"audio" : "SLOT_AUDIO",
"accessories": "SLOT_ACCESSORIES",
"color" : "SLOT_COLOR",
"powerconsumption" : "SLOT_POWERCONSUMPTION",
"resolution" : "SLOT_RESOLUTION",
"screensize" : "SLOT_SCREENSIZE",
"screensizerange" : "SLOT_SCREENSIZERANGE"
},
"binary" : {
"kidsallowed":["child","kid","kids","children"],
"dogsallowed":["dog","dogs","puppy"],
"hasinternet":["internet","wifi"],
"acceptscreditcards":["card","cards"],
"isforbusinesscomputing":["business","nonbusiness","home","personal","general"],
"hasusbport" :["usb"]
}
}
总结
将结构化的数据,转为非结构化的文本。整个任务的核心就是这个吧

 浙公网安备 33010602011771号
浙公网安备 33010602011771号