

python之正则表达式
正则表达式(regular expression)一般应用于数据的筛选、查找。是比较常用的工具。正则表达式按照其用途可以分为几大类:匹配单个字符、匹配多个字符,匹配字符位置、匹配分组等。
一、正则表达式字符
1.匹配单个字符:
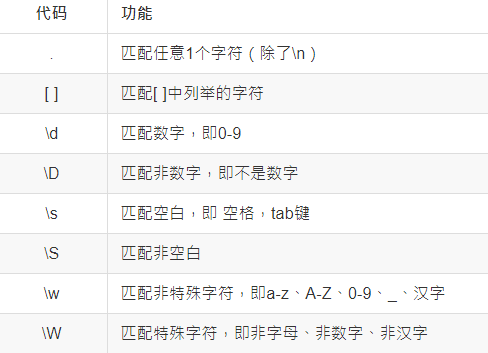
[^] 对中括号内的字符取反进行匹配
2. 匹配多个字符:

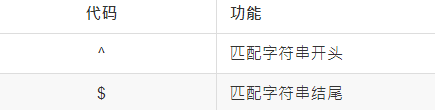
3.匹配位置字符:
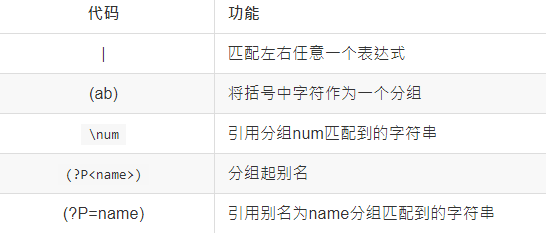
4. 匹配分组:
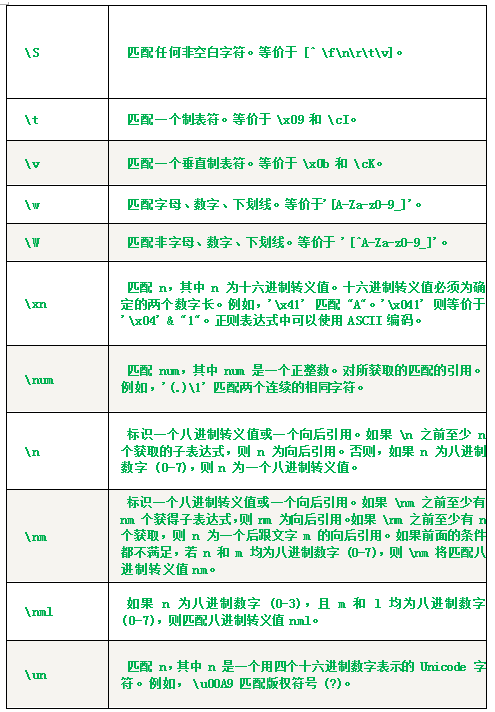
5.其他:
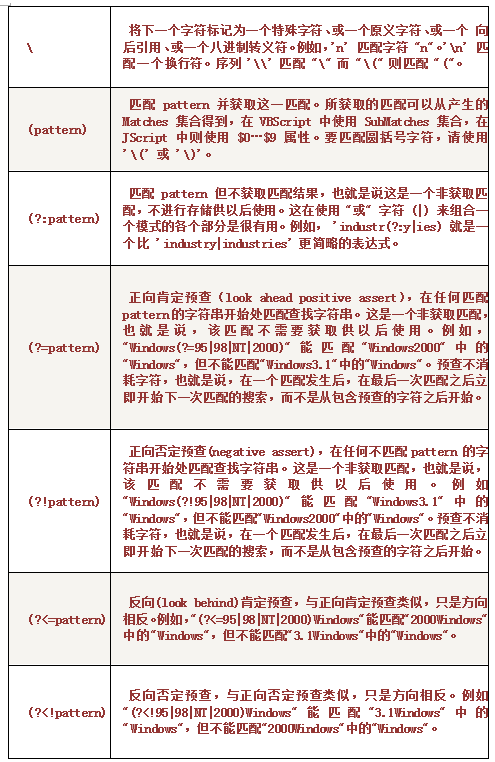
二、注意点:
1. 关于 | 的使用: 只能匹配到一个表达式,不能同时匹配两边表达式
例如:
a6="h(banana|pear)d"
s=re.match(a6,“hbananapeard”
print(s.group()) #报错
2. 关于 ?P<name>组号:命名时不能使用(?P<name>)报错。例如
a1="<((?P<H>)[a-zA-Z1-6]+)><(?P<H1>[a-zA-Z1-6]+)>"
b="<html><h2>fjslkfjwl , fjei</h2></html>"
s=re.match(a1,b)
print(s.group("H")) #结果空
print(s.group(1)) #结果是html
分析原因:加括号后,相当于又建立了一个分组,name分组内需要匹配的内容是空。
3、关于()分组及组号命名
在正则中,括号具有特殊的应用。[]表示匹配(捕获)单个字符,{}表示多次匹配,()表示对里面的内容进行分组。其命名为从左到右,组号0表示整个表达式本身,因此第一个括号的组号为1。当然也可以使用?P<name>对组号进行命名。
import re str='235 dfs 654 5648fdssd' pattern=re.compile(r'(\d+) (\d+)') a=re.search(pattern,str) print(a.group(2))#结果是5648
4.另一大难点是零宽断言。
零宽断言:一个正则表达式中,零宽断言部分匹配字符串成功后,正则的其他表达式,仍旧从零宽断言开始匹配的位置进行,零宽匹配不占用长度。
先行后行:先行是从断言标志的开头查找,后行是从断言标志的结尾处进行查找。
正向零宽断言:(?=regx)
负向零宽断言:(?!=regx)
实例:
import re
a="singER dancinger ldsjfldj"
b="(?=ing)[\S]*"#先行断言,先查找到ing的位置,然后从i的位置开始查找
b1="(?<=ing)[\S]*"#后行断言, 先查找到ing的位置,然后从g的位置开始查找
c=re.findall(b,a)
print(c)
c=re.findall(b1,a)
print(c)
#思路要提取出标签的名字,因此需要用到零寬断言,另需要屏蔽< 和>,
#先使用后向断言可以从<后开始匹配,结尾使用使用先行断言可以匹配到>结束,
a1="<html><h1>fdf</h1></html>"
a2="<html>"
b="(?<=<)[^/].*?(?=>)"
c=re.findall(b,a1)
print(c)
5.正则表达式中常用函数:
search():查找字符串中的内容,找到即返回
find_all():查找字符串中所有的内容,以列表形式展示
match():从头开始匹配,不符合即匹配失败,与其他三个的查询方式完全不同:一个是查找,一个是匹配
sub():查找并替换字符串中的内容
三、一些常用的正则表达式
非负整数:0|([1-9][0-9]*)
非零整数:-?[1-9]\d*
整数:(-?[1-9]\d*)|0
浮点数:-?(([1-9]\d*)|0)(\.\d*)?
5-10位英文数字或下划线:\w{5,10}
qq邮箱:[0-9a-zA-Z_]{4-20}@qq\.com
qq、sina、126邮箱:[0-9a-zA-Z_]{4-20}@(qq|163|126|sina)\.com
11位手机号码:^1\d{10}$
提取一堆html标签中内容:<([a-zA-Z1-6]+)>.*?</\\1>
微博内容:^#[^#]+#
身份证:^[1-9]\d{16}[0-9x]
日期:^[12]\d{3}-([1-9]|1[0-2])-([1-9]|[12][0-9]|3[01])$

