使用ELK Stack收集kubernetes集群内的应用日志
概念
- 日志,对于任何系统来说都是及其重要的组成部分。在计算机系统里面,更是如此。但是由于现在的计算机系统大多比较复杂,很多系统都不是在一个地方,甚至都是跨国界的;即使是在一个地方的系统,也有不同的来源,比如,操作系统,应用服务,业务逻辑等等。他们都在不同生产各种各样的日志数据。根据不完全统计,我们全球每天大约要生产2EB的数据
- K8S系统里的业务应用是高度“动态化”的,随着容器编排的进行,业务容器在不断的被创建、被摧毁、被迁移(漂)、被扩容...
- 面对如此海量的数据,又是分布在各个不同地方,如果我们需要去查找一些重要的信息,难道还是使用传统的方法,去登录到一台台机器上查看?看来传统的工具和方法已经显得非常笨拙和低效了。于是,一些聪明人就提出了建立一套中式的方法,把不同来源的数据集中整合到一个地方。
要达到上述的概念,则我们需要这样一套日志收集、分析的系统:
- 收集 -- 能够采集多种来源的日志数据 (流式日志收集器:就是打一行日志收集一行)
- 传输 -- 能够稳定的把日志数据传输到中央系统 (消息队列,传输一种是基于tcp socket 的9300端口和es通讯,另一种是基于https的9200端口进行通信)
- 存储 -- 可以将日志以结构化数据(就是类似二维表的数据)的形式存储起来 (搜索引擎)
- 分析 -- 支持方便的分析、检索方法,最好有GUI管理系统 (前端)
- 警告 -- 能够提供错误报告,监控机制 (监控工具)
优秀的社区开源解决方案 -- ELK Stack
- E -- ElasticSearch
- L -- LogStash
- K -- Kibaba
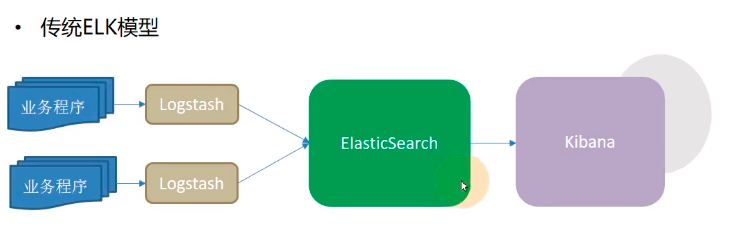
- 缺点:
- Logstash使用Jruby语言开发,吃资源,大量部署消耗极高
- 业务程序与logstash耦合过松,不利于业务迁移
- 日志收集与ES解耦又过紧,易打爆、丢数据
- 在容器云环境下,传统ELK模型难以完成工作
下面的架构模型为本章要部署的架构
终极版模型:
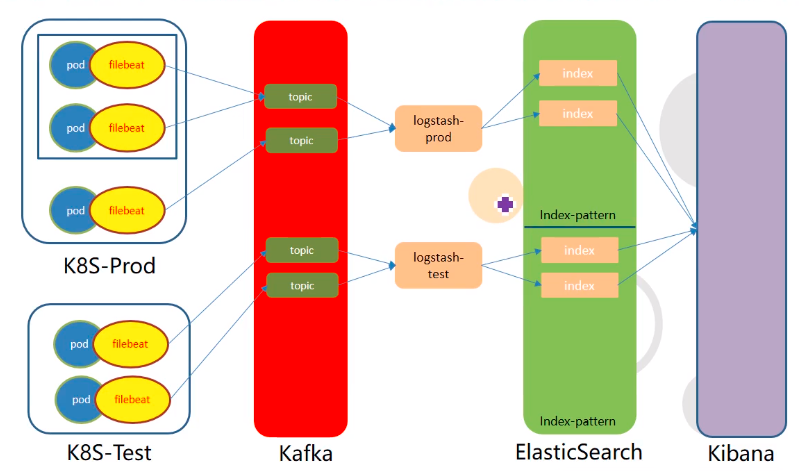
用filebeat来代替logstash来到一线收集pod的日志,把pod和filebeat用边车模式绑在一起运行,这样业务与日志收集的耦合度就紧了
Kafka,用kafka做解耦,将日志打到logstash,kafka支持订阅与发布,这里是filebeat以topic的形式发布到kafka,然后logstash去kafka里取topic,在往ES(ElasticSearch)打日志,这实际上是一个异步的过程
改造dubbo-demo-web项目为Tomcat启动项目
准备Tomcat的镜像底包
准备tomcat二进制包
运维主机HDSS7-200.host.com上:
Tomcat8下载链接
1 [root@hdss7-200 src]# pwd 2 /opt/src 3 4 [root@hdss7-200 src]# ll |grep tomcat 5 -rw-r--r-- 1 root root 5730658 8月 5 16:47 apache-tomcat-8.5.57-src.tar.gz 6 7 [root@hdss7-200 src]# mkdir -p /data/dockerfile/tomcat8 && tar xf apache-tomcat-8.5.57-src.tar.gz -C /data/dockerfile/tomcat8 8 9 [root@hdss7-200 src]# cd /data/dockerfile/tomcat8/
10 rm -fr apache-tomcat-8.5.57-src/webapps/*
简单配置tomcat
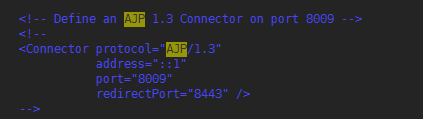
- 关闭AJP端口
1 [root@hdss7-200 tomcat8]# vim /data/dockerfile/tomcat8/apache-tomcat-8.5.57-src/conf/server.xml 2 3 # 用 <! -- 中间内容 --> 结尾注释内容 4 # 此版本tomcat已经默认注册
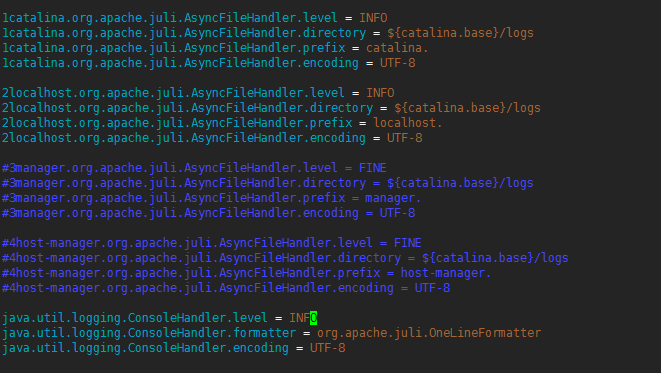
- 配置日志
- 删除3manager,4host-manager的handlers
1 [root@hdss7-200 tomcat8]# vim /data/dockerfile/tomcat8/apache-tomcat-8.5.57-src/conf/logging.properties 2 3 handlers = 1catalina.org.apache.juli.AsyncFileHandler, 2localhost.org.apache.juli.AsyncFileHandler,java.util.logging.ConsoleHandler

日志级别改为INFO
1 [root@hdss7-200 tomcat8]# vim /data/dockerfile/tomcat8/apache-tomcat-8.5.57-src/conf/logging.properties 2 3 1catalina.org.apache.juli.AsyncFileHandler.level = INFO 4 2localhost.org.apache.juli.AsyncFileHandler.level = INFO 5 java.util.logging.ConsoleHandler.level = INFO
# 注释掉所有关于3manager,4host-manager日志的配置
准备Dockerfile
1 [root@hdss7-200 ~]# vi /data/dockerfile/tomcat8/Dockerfile 2 3 From harbor.xue.com/public/jre:8u112 4 RUN /bin/cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime &&\ 5 echo 'Asia/Shanghai' >/etc/timezone 6 ENV CATALINA_HOME /opt/tomcat 7 ENV LANG zh_CN.UTF-8 8 ADD apache-tomcat-8.5.57-src/ /opt/tomcat 9 ADD config.yml /opt/prom/config.yml 10 ADD jmx_javaagent-0.3.1.jar /opt/prom/jmx_javaagent-0.3.1.jar 11 WORKDIR /opt/tomcat 12 ADD entrypoint.sh /entrypoint.sh 13 CMD ["/entrypoint.sh"] 14 15 [root@hdss7-200 ~]# vi /data/dockerfile/tomcat8/config.yml 16 17 — 18 rules: 19 - pattern: '.*' 20 21 22 [root@hdss7-200 ~]# wget https://repo1.maven.org/maven2/io/prometheus/jmx/jmx_prometheus_javaagent/0.3.1/jmx_prometheus_javaagent-0.3.1.jar -O jmx_javaagent-0.3.1.jar 23 24 25 [root@hdss7-200 ~]# vi /data/dockerfile/tomcat8/entrypoint.sh (不要忘了给执行权限) 26 27 #!/bin/bash 28 M_OPTS="-Duser.timezone=Asia/Shanghai -javaagent:/opt/prom/jmx_javaagent-0.3.1.jar=$(hostname -i):${M_PORT:-"12346"}:/opt/prom/config.yml" 29 C_OPTS=${C_OPTS} # 连接apollo需要的环境变量 30 MIN_HEAP=${MIN_HEAP:-"128m"} 31 MAX_HEAP=${MAX_HEAP:-"128m"} 32 JAVA_OPTS=${JAVA_OPTS:-"-Xmn384m -Xss256k -Duser.timezone=GMT+08 -XX:+DisableExplicitGC -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=0 -XX:+CMSClassUnloadingEnabled -XX:LargePageSizeInBytes=128m -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=80 -XX:SoftRefLRUPolicyMSPerMB=0 -XX:+PrintClassHistogram -Dfile.encoding=UTF8 -Dsun.jnu.encoding=UTF8"} 33 CATALINA_OPTS="${CATALINA_OPTS}" 34 JAVA_OPTS="${M_OPTS} ${C_OPTS} -Xms${MIN_HEAP} -Xmx${MAX_HEAP} ${JAVA_OPTS}" 35 sed -i -e "1a\JAVA_OPTS=\"$JAVA_OPTS\"" -e "1a\CATALINA_OPTS=\"$CATALINA_OPTS\"" /opt/tomcat/bin/catalina.sh 36 37 cd /opt/tomcat && /opt/tomcat/bin/catalina.sh run 38 39 40 41 [root@hdss7-200 ~]# chmod +x /data/dockerfile/tomcat8/entrypoint.sh 42
制作镜像并推送
1 [root@hdss7-200 tomcat8]# docker build . -t harbor.xue.com/base/tomcat:v8.5.57 2 Sending build context to Docker daemon 32.79MB 3 Step 1/10 : From harbor.xue.com/public/jre:8u112 4 ---> fa3a085d6ef1 5 Step 2/10 : RUN /bin/cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && echo 'Asia/Shanghai' >/etc/timezone 6 ---> Using cache 7 ---> f0725fded125 8 Step 3/10 : ENV CATALINA_HOME /opt/tomcat 9 ---> Running in 09fae2052230 10 Removing intermediate container 09fae2052230 11 ---> 7c6546db577b 12 Step 4/10 : ENV LANG zh_CN.UTF-8 13 ---> Running in 22fc0f1fbbb5 14 Removing intermediate container 22fc0f1fbbb5 15 ---> f5d7c030e29d 16 Step 5/10 : ADD apache-tomcat-8.5.57-src/ /opt/tomcat 17 ---> 19d6c2a589b4 18 Step 6/10 : ADD config.yml /opt/prom/config.yml 19 ---> 8091dab091ec 20 Step 7/10 : ADD jmx_javaagent-0.3.1.jar /opt/prom/jmx_javaagent-0.3.1.jar 21 ---> 4d92814d8fa7 22 Step 8/10 : WORKDIR /opt/tomcat 23 ---> Running in 54c2ca87013d 24 Removing intermediate container 54c2ca87013d 25 ---> 948ff870712f 26 Step 9/10 : ADD entrypoint.sh /entrypoint.sh 27 ---> 3e36f14c0412 28 Step 10/10 : CMD ["/entrypoint.sh"] 29 ---> Running in 3584687deec1 30 Removing intermediate container 3584687deec1 31 ---> 17e4dfb6af7c 32 Successfully built 17e4dfb6af7c 33 Successfully tagged harbor.xue.com/base/tomcat:v8.5.57 34 35 [root@hdss7-200 tomcat8]# docker push !$ 36 docker push harbor.xue.com/base/tomcat:v8.5.57 37 The push refers to repository [harbor.xue.com/base/tomcat] 38 136ec47e7025: Pushed 39 48f30a377149: Pushed 40 8fb550cdedab: Pushed 41 aabcf63a9e94: Pushed 42 34469739c7f1: Mounted from base/jre8 43 0690f10a63a5: Mounted from base/jre8 44 c843b2cf4e12: Mounted from base/jre8 45 fddd8887b725: Mounted from base/jre8 46 42052a19230c: Mounted from base/jre8 47 8d4d1ab5ff74: Mounted from base/jre8 48 v8.5.57: digest: sha256:1ef721bf2bcf227cff4c0edaeaaae1c36207113c1ada83f1391b426cb55c1fe8 size: 2409
改造dubbo-demo-web项目
略
新建Jenkins的pipeline
基于tomcat跑的web项目,之前的那条popeline(流水线)是不适用的,因为上一条流水线是有10个参数,tomcat的参数要多一个(多的是ROOT dir)


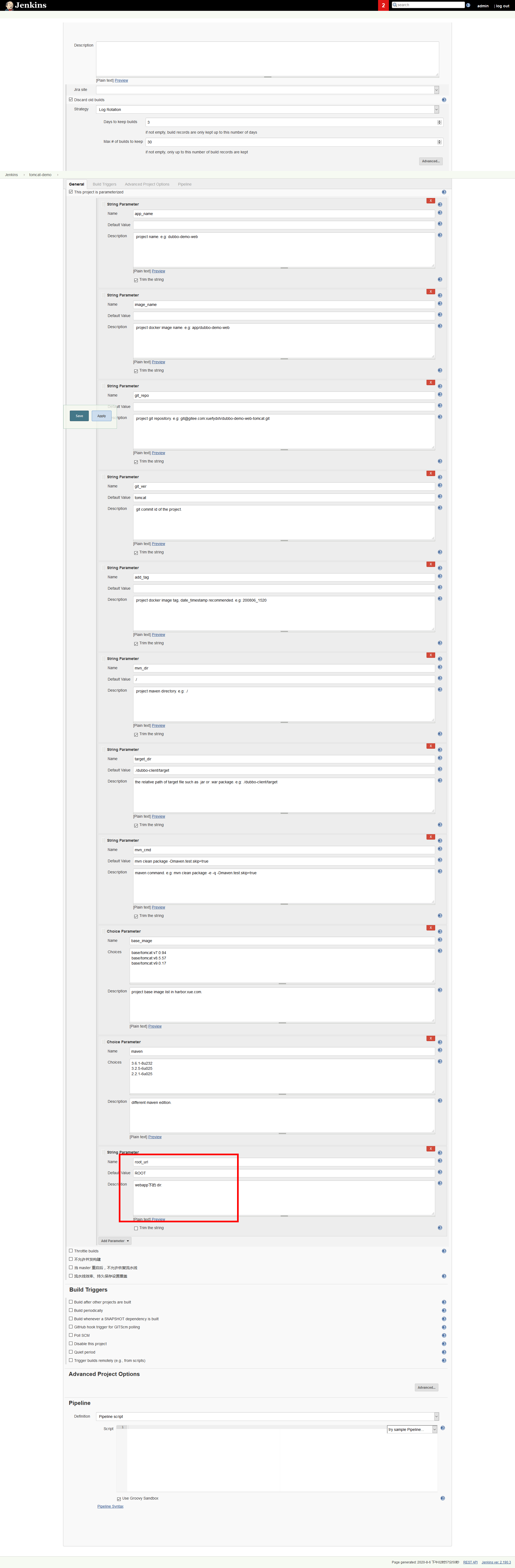
Pipeline Script
1 pipeline { 2 agent any 3 stages { 4 stage('pull') { //get project code from repo 5 steps { 6 sh "git clone ${params.git_repo} ${params.app_name}/${env.BUILD_NUMBER} && cd ${params.app_name}/${env.BUILD_NUMBER} && git checkout ${params.git_ver}" 7 } 8 } 9 stage('build') { //exec mvn cmd 10 steps { 11 sh "cd ${params.app_name}/${env.BUILD_NUMBER} && /var/jenkins_home/maven-${params.maven}/bin/${params.mvn_cmd}" 12 } 13 } 14 stage('unzip') { //unzip target/*.war -c target/project_dir 15 steps { 16 sh "cd ${params.app_name}/${env.BUILD_NUMBER} && cd ${params.target_dir} && mkdir project_dir && unzip *.war -d ./project_dir" 17 } 18 } 19 stage('image') { //build image and push to registry 20 steps { 21 writeFile file: "${params.app_name}/${env.BUILD_NUMBER}/Dockerfile", text: """FROM harbor.xue.com/${params.base_image} 22 ADD ${params.target_dir}/project_dir /opt/tomcat/webapps/${params.root_url}""" 23 sh "cd ${params.app_name}/${env.BUILD_NUMBER} && docker build -t harbor.xue.com/${params.image_name}:${params.git_ver}_${params.add_tag} . && docker push harbor.xue.com/${params.image_name}:${params.git_ver}_${params.add_tag}" 24 } 25 } 26 } 27 }
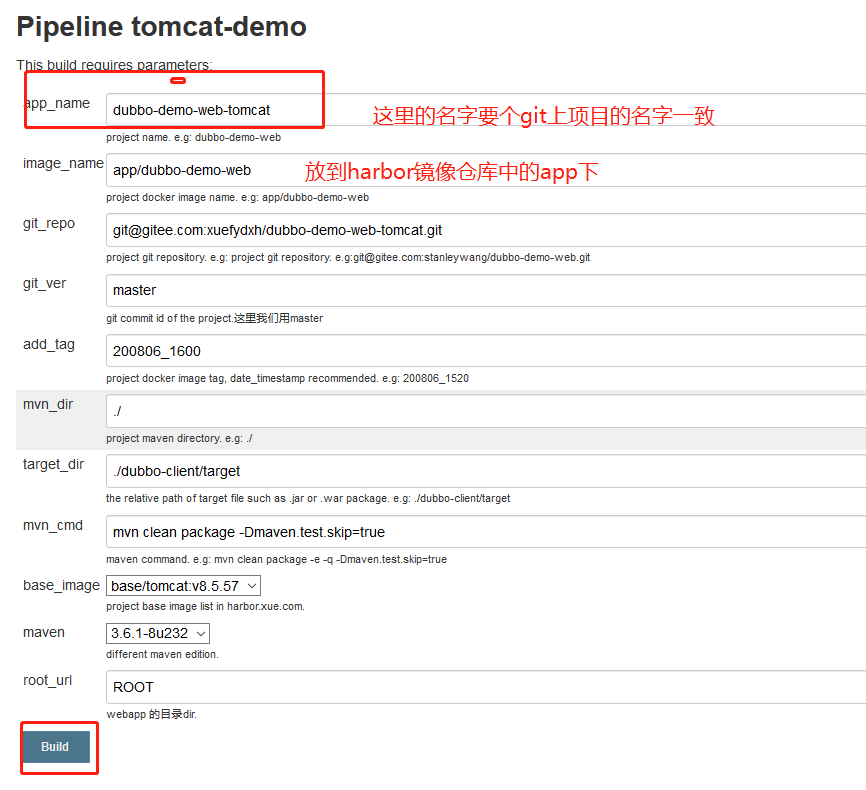
构建应用镜像
使用Jenkins进行CI,并查看harbor仓库

准备k8s的资源配置清单
不再需要单独准备资源配置清单,在test名称空间启动 apollo和dubbo-demo和修改
k8s的dashboard上直接修改image的值为jenkins打包出来的镜像
文档里的例子是:harbor.xue.com/app/dubbo-demo-web-tomcat:master_200806_1640
使用ELK Stack收集kubernetes集群内的应用日志
部署ElasticSearch
官网
官方github地址
下载地址HDSS7-12.host.com上:
这里用6.8一下,因为更新的版本需要jkd11+
安装
[root@hdss7-12 src]# ls -l|grep elasticsearch-5.6.15.tar.gz -rw-r--r-- 1 root root 72262257 Jan 30 15:18 elasticsearch-5.6.15.tar.gz [root@hdss7-12 src]# tar xf elasticsearch-5.6.15.tar.gz -C /opt [root@hdss7-12 src]# ln -s /opt/elasticsearch-5.6.15/ /opt/elasticsearch
配置
elasticsearch.yml
[root@hdss7-12 src]# mkdir -p /data/elasticsearch/{data,logs} [root@hdss7-12 elasticsearch]# vi config/elasticsearch.yml cluster.name: es.xue.com node.name: hdss7-12.host.com path.data: /data/elasticsearch/data path.logs: /data/elasticsearch/logs bootstrap.memory_lock: true network.host: 10.4.7.12 http.port: 9200
jvm.options
1 [root@hdss7-12 elasticsearch]# vi config/jvm.options 2 -Xms512m 3 -Xmx512m
创建普通用户
1 [root@hdss7-12 elasticsearch]# useradd -s /bin/bash -M es 2 [root@hdss7-12 elasticsearch]# chown -R es.es /opt/elasticsearch-5.6.15 3 [root@hdss7-12 elasticsearch]# chown -R es.es /data/elasticsearch
文件描述符
[root@hdss7-12 src]# vi /etc/security/limits.d/es.conf es hard nofile 65536 es soft fsize unlimited es hard memlock unlimited es soft memlock unlimited
调整内核参数
1 [root@hdss7-12 elasticsearch]# sysctl -w vm.max_map_count=262144 2 or 3 4 [root@hdss7-12 elasticsearch]# echo "vm.max_map_count=262144" > /etc/sysctl.conf 5 6 [root@hdss7-12 elasticsearch]# sysctl -p
启动
1 [root@hdss7-12 src]# su -c "/opt/elasticsearch/bin/elasticsearch -d" es 2 3 4 [root@hdss7-12 src]# ps -ef|grep elastic|grep -v grep 5 es 2684 1 7 14:54 ? 00:00:43 /usr/java/jdk/bin/java -Xms512m -Xmx512m -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -XX:+AlwaysPreTouch -server -Xss1m -Djava.awt.headless=true -Dfile.encoding=UTF-8 -Djna.nosys=true -Djdk.io.permissionsUseCanonicalPath=true -Dio.netty.noUnsafe=true -Dio.netty.noKeySetOptimization=true -Dio.netty.recycler.maxCapacityPerThread=0 -Dlog4j.shutdownHookEnabled=false -Dlog4j2.disable.jmx=true -Dlog4j.skipJansi=true -XX:+HeapDumpOnOutOfMemoryError -Des.path.home=/opt/elasticsearch -cp /opt/elasticsearch/lib/* org.elasticsearch.bootstrap.Elasticsearch -d 6 7 8 [root@hdss7-12 logs]# netstat -tulanp | grep 9200 9 tcp6 0 0 10.4.7.12:9200 :::* LISTEN 2684/java 10 11 [root@hdss7-12 logs]# netstat -tulanp | grep 9300 12 tcp6 0 0 10.4.7.12:9300 :::* LISTEN 2684/java
调整ES日志模板
[root@hdss7-12 elasticsearch]# curl -XPUT http://10.4.7.12:9200/_template/k8s -d '{ "template" : "k8s*", "index_patterns": ["k8s*"], "settings": { "number_of_shards": 5, "number_of_replicas": 0 } }' # 就是调整副本数为0 分片为5,生产环境正建议副本数调成2,因为工业中3份数据定义为安全
部署kafka
官网
官方github地址
下载地址HDSS7-11.host.com上:
安装
[root@hdss7-11 src]# pwd /opt/src [root@hdss7-11 src]# ll | grep kafka_2.12-2.2.0.tgz -rw-r--r-- 1 root root 57028557 8月 10 21:28 kafka_2.12-2.2.0.tgz [root@hdss7-11 src]# tar xf kafka_2.12-2.2.0.tgz -C /opt/ [root@hdss7-11 src]# ln -s /opt/kafka_2.12-2.2.0/ ../kafka
配置
[root@hdss7-11 kafka]# vim config/server.properties log.dirs=/data/kafka/logs zookeeper.connect=localhost:2181 log.flush.interval.messages=10000 log.flush.interval.ms=1000 delete.topic.enable=true host.name=hdss7-11.host.com advertised.listeners=PLAINTEXT://10.4.7.11:9092
启动
[root@hdss7-11 kafka]# bin/kafka-server-start.sh -daemon config/server.properties [root@hdss7-11 kafka]# netstat -luntp|grep 9092 tcp6 0 0 10.4.7.12:9092 :::* LISTEN 17543/java
启动报错
[root@hdss7-11 kafka]# ./bin/kafka-server-start.sh config/server.properties [2020-08-12 10:02:49,304] FATAL (kafka.Kafka$) java.lang.VerifyError: Uninitialized object exists on backward branch 146 Exception Details: Location: scala/util/matching/Regex.unapplySeq(Ljava/lang/CharSequence;)Lscala/Option; @200: goto Reason: Error exists in the bytecode Bytecode: 0000000: 2bc7 000a b200 524d a700 db2a b600 542b 0000010: b600 5a4e 2a2d b600 5e99 00c6 bb00 6059 0000020: b200 65b2 006a 0436 04c7 0005 01bf 1504 0000030: 2db6 0070 b600 74b6 0078 2dba 008e 0000 0000040: b200 93b6 0097 3a07 3a06 59c7 0005 01bf 0000050: 3a05 1907 b200 93b6 009b a600 7619 05b2 0000060: 00a0 a600 09b2 00a0 a700 71bb 00a2 5919 0000070: 05b6 00a8 3a0c 2d19 0cb8 0085 b200 a0b7 0000080: 00ac 3a08 1908 3a09 1905 b600 afc0 00a4 0000090: 3a0a 190a b200 a0a5 0034 bb00 a259 190a 00000a0: b600 a83a 0c2d 190c b800 85b2 00a0 b700 00000b0: ac3a 0b19 0919 0bb6 00b3 190b 3a09 190a 00000c0: b600 afc0 00a4 3a0a a7ff ca19 08a7 000c 00000d0: 1905 1906 1907 b800 b9b7 00bc a700 06b2 00000e0: 0052 4d2c b0 Stackmap Table: same_frame(@11) full_frame(@46,{Object[#2],Object[#204],Top,Object[#108],Integer},{Uninitialized[#28],Uninitialized[#28],Object[#98]}) full_frame(@80,{Object[#2],Object[#204],Top,Object[#108],Integer,Top,Object[#206],Object[#208]},{Uninitialized[#28],Uninitialized[#28],Object[#164]}) full_frame(@107,{Object[#2],Object[#204],Top,Object[#108],Integer,Object[#164],Object[#206],Object[#208]},{Uninitialized[#28],Uninitialized[#28]}) full_frame(@146,{Object[#2],Object[#204],Top,Object[#108],Integer,Object[#164],Object[#206],Object[#208],Object[#162],Object[#162],Object[#164],Top,Object[#4]},{Uninitialized[#28],Uninitialized[#28]}) full_frame(@203,{Object[#2],Object[#204],Top,Object[#108],Integer,Object[#164],Object[#206],Object[#208],Object[#162],Object[#162],Object[#164],Top,Object[#4]},{Uninitialized[#28],Uninitialized[#28]}) full_frame(@208,{Object[#2],Object[#204],Top,Object[#108],Integer,Object[#164],Object[#206],Object[#208]},{Uninitialized[#28],Uninitialized[#28]}) full_frame(@217,{Object[#2],Object[#204],Top,Object[#108],Integer,Object[#164],Object[#206],Object[#208]},{Uninitialized[#28],Uninitialized[#28],Object[#4]}) full_frame(@223,{Object[#2],Object[#204],Top,Object[#108]},{}) same_locals_1_stack_item_frame(@226,Object[#210]) full_frame(@227,{Object[#2],Object[#204],Object[#210]},{}) at scala.collection.immutable.StringLike.r(StringLike.scala:281) at scala.collection.immutable.StringLike.r$(StringLike.scala:281) at scala.collection.immutable.StringOps.r(StringOps.scala:29) at scala.collection.immutable.StringLike.r(StringLike.scala:270) at scala.collection.immutable.StringLike.r$(StringLike.scala:270) at scala.collection.immutable.StringOps.r(StringOps.scala:29) at kafka.cluster.EndPoint$.<init>(EndPoint.scala:29) at kafka.cluster.EndPoint$.<clinit>(EndPoint.scala) at kafka.server.Defaults$.<init>(KafkaConfig.scala:63) at kafka.server.Defaults$.<clinit>(KafkaConfig.scala) at kafka.server.KafkaConfig$.<init>(KafkaConfig.scala:673) at kafka.server.KafkaConfig$.<clinit>(KafkaConfig.scala) at kafka.server.KafkaServerStartable$.fromProps(KafkaServerStartable.scala:28) at kafka.Kafka$.main(Kafka.scala:58) at kafka.Kafka.main(Kafka.scala) # 如果遇到上面的这种错误,请排查 一: kafka无法启动或卡死 <可能原因:虚拟机内存不足 解决方法:修改启动脚本的初始内存1G -> 200m 1、打开脚本 vim bin/kafka-server-start.sh 2、找到:export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G" 3、修改为:export KAFKA_HEAP_OPTS="-Xmx200m -Xms200m" 4、重启kafka:bin/kafka-server-start.sh config/server.properties> 二: kafka的对jdk的版本要求比较苛刻, 本人下载的版本是 kafka_2.12-2.2.0,要下载对应的jdk,精确到小版本JDK1.8.0_251 下载地址(https://www.cnblogs.com/congliang/p/13124474.html) 解压更换环境变量中的路径即可
参考播客
https://blog.csdn.net/QYHuiiQ/article/details/86556591
常用命令
测试kafka: 1.切换到 /usr/local/kafka,创建topics ./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test-topic 2.创建生产者 ./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test_topics 3.重新打开新终端创建消费者: ./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test_topics --from-beginning 后台启动: 方法一: sh kafka-server-start.sh ../config/server.properties 1>/dev/null 2>&1 & 方法二: nohup bin/kafka-server-start.sh config/server.properties >>kafka.log &
部署kafka-manager
官方github地址
源码下载地址
运维主机HDSS7-200.host.com上:
直接下载docker镜像
[root@hdss7-200 ~]# docker pull sheepkiller/kafka-manager Using default tag: latest latest: Pulling from sheepkiller/kafka-manager 469cfcc7a4b3: Pull complete 4458b033eac3: Pull complete 838a0ff6e24f: Pull complete 0128a98dafdb: Pull complete Digest: sha256:615f3b99d38aba2d5fdb3fb750a5990ba9260c8fb3fd29c7e776e8c150518b78 Status: Downloaded newer image for sheepkiller/kafka-manager:latest docker.io/sheepkiller/kafka-manager:latest [root@hdss7-200 ~]# docker tag 4e4a8c5dabab harbor.xue.com/infra/kafka-manager:stable [root@hdss7-200 ~]# docker push !$
准备资源配置清单
[root@hdss7-200 ~]# mkdir /data/k8s-yaml/kafka-manager/ [root@hdss7-200 ~]# cd !$ cd /data/k8s-yaml/kafka-manager/ # dp vi [root@hdss7-200 kafka-manager]# vi dp.yaml kind: Deployment apiVersion: extensions/v1beta1 metadata: name: kafka-manager namespace: infra labels: name: kafka-manager spec: replicas: 1 selector: matchLabels: name: kafka-manager template: metadata: labels: app: kafka-manager name: kafka-manager spec: containers: - name: kafka-manager image: harbor.xue.com/infra/kafka-manager:stable ports: - containerPort: 9000 protocol: TCP env: - name: ZK_HOSTS value: zk1.xue.com:2181 - name: APPLICATION_SECRET value: letmein imagePullPolicy: IfNotPresent imagePullSecrets: - name: harbor restartPolicy: Always terminationGracePeriodSeconds: 30 securityContext: runAsUser: 0 schedulerName: default-scheduler strategy: type: RollingUpdate rollingUpdate: maxUnavailable: 1 maxSurge: 1 revisionHistoryLimit: 7 progressDeadlineSeconds: 600 # svc.yaml kind: Service apiVersion: v1 metadata: name: kafka-manager namespace: infra spec: ports: - protocol: TCP port: 9000 targetPort: 9000 selector: app: kafka-manager clusterIP: None type: ClusterIP sessionAffinity: None # ingress.yaml kind: Ingress apiVersion: extensions/v1beta1 metadata: name: kafka-manager namespace: infra spec: rules: - host: km.xue.com http: paths: - path: / backend: serviceName: kafka-manager servicePort: 9000
解析域名
HDSS7-11.host.com上
km 60 IN A 10.4.7.10
应用资源配置清单
任意一台运算节点上:
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.xue.com/kafka-manager/dp.yaml deployment.extensions/kafka-manager created [root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.xue.com/kafka-manager/svc.yaml service/kafka-manager created [root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.xue.com/kafka-manager/ingress.yaml ingress.extensions/kafka-manager created
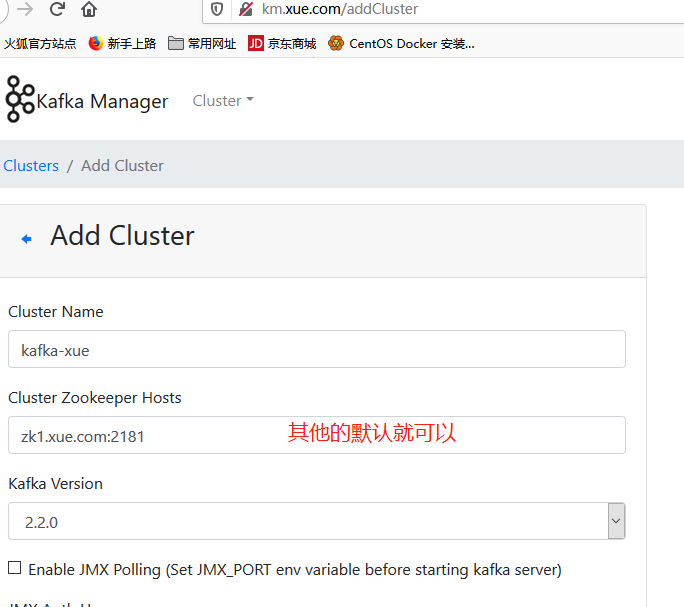
浏览器访问
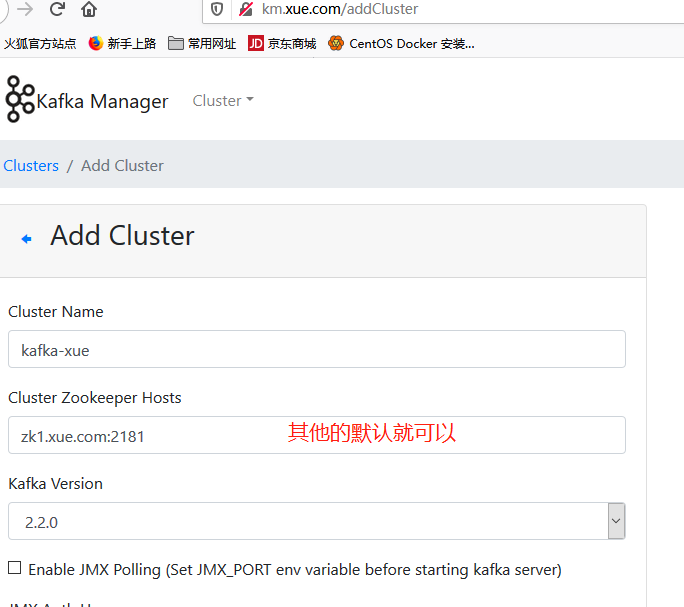
添加集群

 浙公网安备 33010602011771号
浙公网安备 33010602011771号