第11次预习课-20180905 正则表达式
正则表达式
精确匹配或者模糊匹配
比如:匹配所有日志中的ip,匹配所有的响应时间。
Re: regular expression
所有的语言使用的正则大同小异
Match:(匹配一次)表示从字符串的开头匹配,如果从第一个字符就不能匹配,则匹配失败
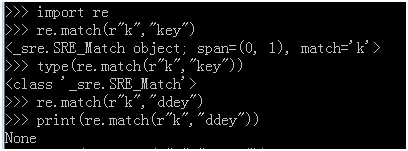
Search (匹配一次)从任意位置匹配

>>> print(re.search(r"k","ddkey"))
<_sre.SRE_Match object; span=(2, 3), match='k'>
>>> re.search(r"ke","ddkey")
<_sre.SRE_Match object; span=(2, 4), match='ke'>
>>> re.search(r"\d","ddk3ey")
<_sre.SRE_Match object; span=(3, 4), match='3'>
.group() 将匹配的结果显示出来
>>> re.search(r"\d","ddk3ey").group()
'3'
+加号代表匹配1个或多个符合的,但匹配一次
>>> re.search(r"\d+","a1b2c3d4").group()
'1'
>>> re.search(r"\d+","a1234bcd").group()
'1234'
Findall (匹配多次)将所有的匹配的放在列表中
>>> re.findall(r"\d+","a1b2c3d4")
['1', '2', '3', '4']
\D 表示匹配非数字
>>> re.search(r"\D","123a1234bcd").group()
'a'
\w 会将数字和字母都匹配出来
>>> re.search(r"\w","123a1234bcd").group()
'1'
>>> re.search(r"\w+","123a1234bcd").group()
'123a1234bcd'
>>> re.search(r"\w+","123a1234b cd").group()
'123a1234b'
\W 匹配非数字和字母
>>> re.search(r"\W+","123a1234b@#$@#%$#cd").group()
'@#$@#%$#'
\s 匹配空格 \t \r \n 等
>>> re.search(r"\s+","123a1234b@#$ $#cd").group()
' '
>>> re.search(r"2\s+3","123a12 34b@#$ $#cd").group()
'2 3'
*表示匹配0个或多个
>>> re.match(r"\w*","abc").group()
'abc'
正则表达式的贪婪性,尽量多匹配
>>> re.match(r"\w*","abc").group()
'abc'
>>> re.match(r"\w*"," abc").group()
''
? 限制贪婪性
>>> re.match(r"\w+","abc").group()
'abc'
>>> re.match(r"\w+?","abc").group()
'a'
{} 表示,{a,b} 匹配a到b个
>>> re.match(r"a{3}","aaaaabc").group()
'aaa'
>>> re.match(r"a{1,3}","aaaaabc").group()
'aaa'
>>> re.match(r"a{1,3}?","aaaaabc").group()
'a'
>>> s ="abc12 33"
>>> if re.search(r"\d",s):
... print("字符串有数字")
... else:
... print("字符串没有数字")
...
字符串有数字
[a-zA-Z] [0-9] 方括号是代表匹配或的关系
例子
>>> s = "12345aaaaa"
>>> if re.search(r"[1-9]{5}",s):
... print("hhhh")
...
Hhhh
>>> re.search(r"[1-3|a-d]+","sfwejfasasz12314324").group()
'a'
>>> re.search(r"[1-2|3-4]+","sfwejfasasz12314324").group()
'12314324'
>>>
?表示0次或1次
>>> re.search(r"1?","1234").group()
'1'
>>> re.search(r"1?","fsdfsd").group()
''
>>>
分组
>>> re.search(r"(a)(\d+)(c)","a1234321c").group(1)
'a'
>>> re.search(r"(a)(\d+)(c)","a1234321c").group(2)
'1234321'
>>> re.search(r"(a)(\d+)(c)","a1234321c").group(3)
'c'
>>> re.search(r"(a)(\d+)(c)","a1234321c").group(4)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: no such group
re.I 忽略大小写
>>> re.search(r"a","3AAA21c",re.I).group()
'A'
. 匹配除了回车之外的字符(\n)
>>> re.match(r".","\nsss").group()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
>>> re.match(r".","sss").group()
's'
>>> re.match(r"\.",".sss").group()
'.'
>>>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号