
实验报告:实验五
实验内容:
1.将老师给的程序框架编译、连接后利用反汇编u查看代码长度,利用g命令将程序运行至在mov ax,4c00h结束语句前。
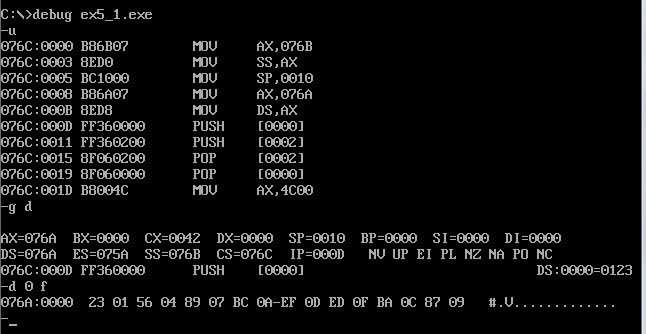
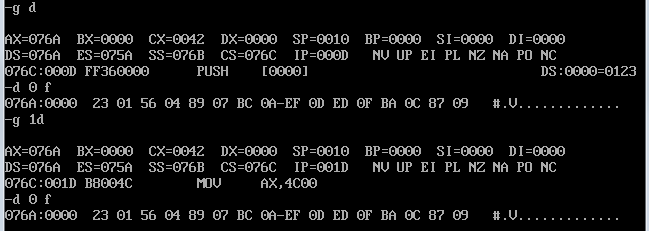
(1)发现data中的数据被改为代码中指定的数据。
(2)程序返回前,cs=076C、ss=076B、ds=076A。
(3)程序运行后,设code段地址为X,则data段地址为X-2,stack段的段地址为X-1。
2.将ex5-2编译连接用debug调试后
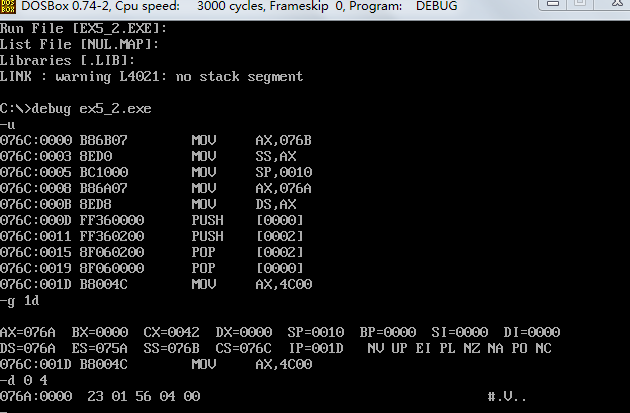
(1)发现data中的数据为改为了指定的数据。
(2)程序返回前,cs=076C,ss=076B,ds=076A。
(3)设程序加载后,code段的段地址为X,则data段的段地址为X-2,stack的段地址为X-1。
(4)若段中数据占N个字节,程序加载后,该段实际占有的空间为。。
这题其实一开始我还挺没头绪的,因为我只看出了三个段地址间的差为1,且存入16,4个字节后的段地址并没有改变,但是我经过上网的查阅发现:因为每个段都是以16字节来对齐的,但是最大不能超过64KB 。这也就是说,如果你的段数据在16字节内,一样会被当做一个字节段来算,就是16字节。 要是大于16字节呢,那么如果多出就算是1个字节,因为已经超过一个16字节,多出来的1个字节 也得有一个字节段的容量来存储它,所以这时得占两个字节段,就是32字节,以此类推。
所以答案为((N+15)/16)*16(该式意思是满十六后多出的部分都按16计算)
3.编译连接运行后

(1)data中的数据与设定的数据一致。
(2)cs=076A,ss=076E,ds=076D。
(3)设code段的段地址为X,则data段的段地址为X+3,stack段地址为X+4。
这里有一个疑问,代码段的长度如图为32个字节,在我看来,应该只要+2就够了啊,可能是系统多预留了16字节的空间吗?
4.
将三个代码中的start分别删去,再编译连接运行。
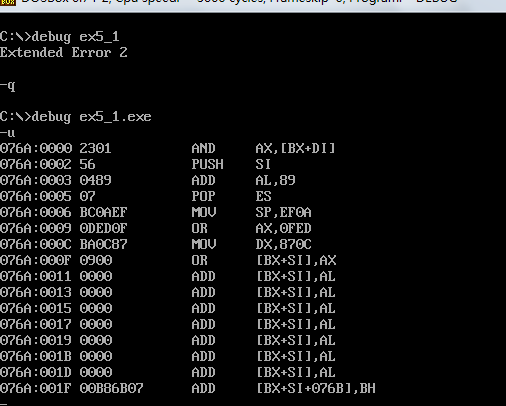
实验一无法运行
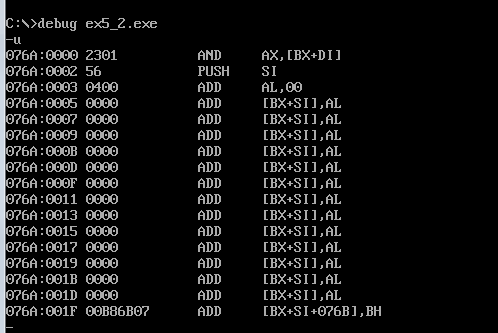
实验二也无法运行
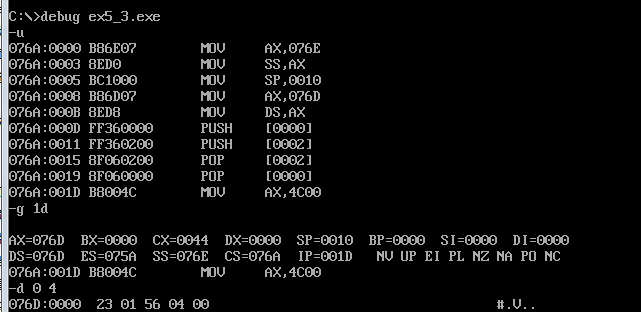
实验三反汇编的代码一致,且结果也一致。
因为将start去掉后,程序会从ip=0的位置开始执行,而三个程序中只有第三个程序代码段的位置是ip=0时的位置,所以第三个程序可以被执行。
5.
代码如下:
1 assume cs:code 2 a segment 3 db 1,2,3,4,5,6,7,8 4 a ends 5 6 b segment 7 db 1,2,3,4,5,6,7,8 8 b ends 9 10 c1 segment ; 在集成软件环境中,请将此处的段名称由c→改为c1或其它名称 11 db 8 dup(0) 12 c1 ends ; 改的时候要成对一起修改 13 code segment 14 start: 15 mov ax,a 16 mov ds,ax 17 mov cx,8 18 mov bx,0 19 20 s: mov ax,[bx] 21 add ax,[bx+10h] 22 mov [bx+20h],ax 23 add bx,2 24 loop s 25 26 mov ax,4c00h 27 int 21h 28 code ends 29 end start
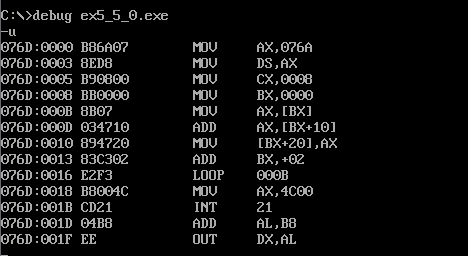
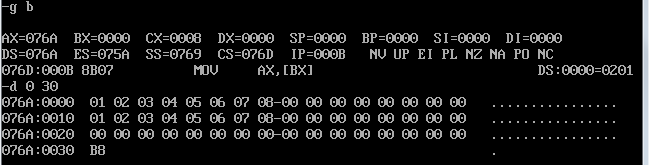
如上图,相加前逻辑段c的值为0.
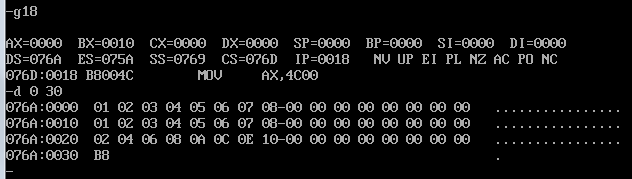
如图,实现数据相加后的逻辑段c的8个字节的值为前16个字节数据对应的和。
6.
assume cs:code a segment dw 1,2,3,4,5,6,7,8,9,0ah,0bh,0ch,0dh,0eh,0fh,0ffh a ends b segment dw 8 dup(0) b ends code segment start: mov ax,a mov ds,ax mov bx,0 mov cx,8 mov ax,b mov ss,ax mov sp,10h s: push [bx] add bx,2 loop s mov ax,4c00h int 21h code ends end start

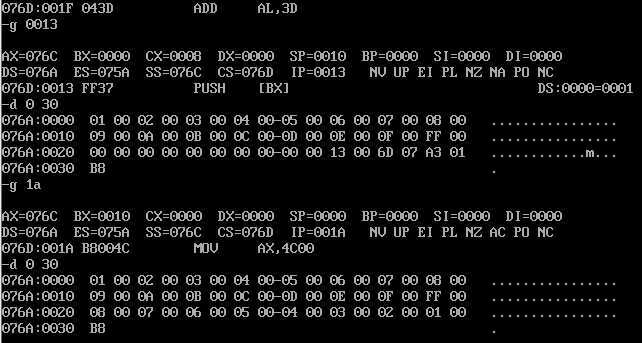
如上图,对比前后逻辑段c中的数据,发现存放正确。
实验感想:
对于分段代码的顺序即部分的操作要点有了更深的理解,逐渐开始可以自己编写或者补全部分简单的代码,实验过程中遇到了许多的疑问,但是通过上网查阅,对于数据的存储,栈的定义有了更深的理解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号