
第一次个人编程作业
| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业在哪里 | 作业链接 |
| 这个作业的目标 | 系统化流程地完成软件开发,使用性能测试工具和单元测试以优化程序 |
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| · Planning | · 计划 | 30 | 40 |
| · Estimate | · 估计这个任务需要多少时间 | 350 | 460 |
| · Development | · 开发 | 200 | 175 |
| · Analysis | · 需求分析 (包括学习新技术) | 20 | 45 |
| · Design Spec | · 生成设计文档 | 10 | 15 |
| · Design Review | · 设计复审 | 5 | 5 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 3 | 3 |
| · Design | · 具体设计 | 20 | 20 |
| · Coding | · 具体编码 | 60 | 75 |
| · Code Review | · 代码复审 | 15 | 20 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 20 | 27 |
| · Reporting | · 报告 | 120 | 125 |
| · Test Repor | · 测试报告 | 30 | 50 |
| · Size Measurement | · 计算工作量 | 35 | 25 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 30 |
| · 合计 | 588 | 600 |
计算模块接口的设计与实现过程:
- 首先确定用LCS(最长公共子序列)的计算作为计算文本相似度的方法,将总的计算过程分为“读取文件”、“计算相似度”、“写入文件”。
- 调用 调用 FileUtils.readFile 读取原文和抄袭版文件内容。
- 调用 FileUtils.readFile 读取原文和抄袭版文件内容。
- 调用 TextComparator.calculateSimilarity 计算相似度。
- 调用 FileUtils.writeFile 将结果写入输出文件。
6.TextComparator.calculateSimilarity:
- 调用 longestCommonSubsequence 计算最长公共子序列长度。
- 根据 LCS 长度和文本长度计算相似度。
- FileUtils.readFile 和 FileUtils.writeFile:
- 直接操作文件系统,读取和写入文件内容。
性能分析
性能分析图:
![]()
改进措施:
- 问题:Files.readAllBytes 一次性读取整个文件,可能导致内存占用过高。
改进:使用 BufferedReader 逐行读取文件,减少内存占用。 - 如果多次计算相同文件的相似度,重复计算会导致性能浪费。
改进:使用缓存(如 HashMap)存储已计算的结果,避免重复计算。
单元测试:
测试覆盖率:
文件读取、写入测试:
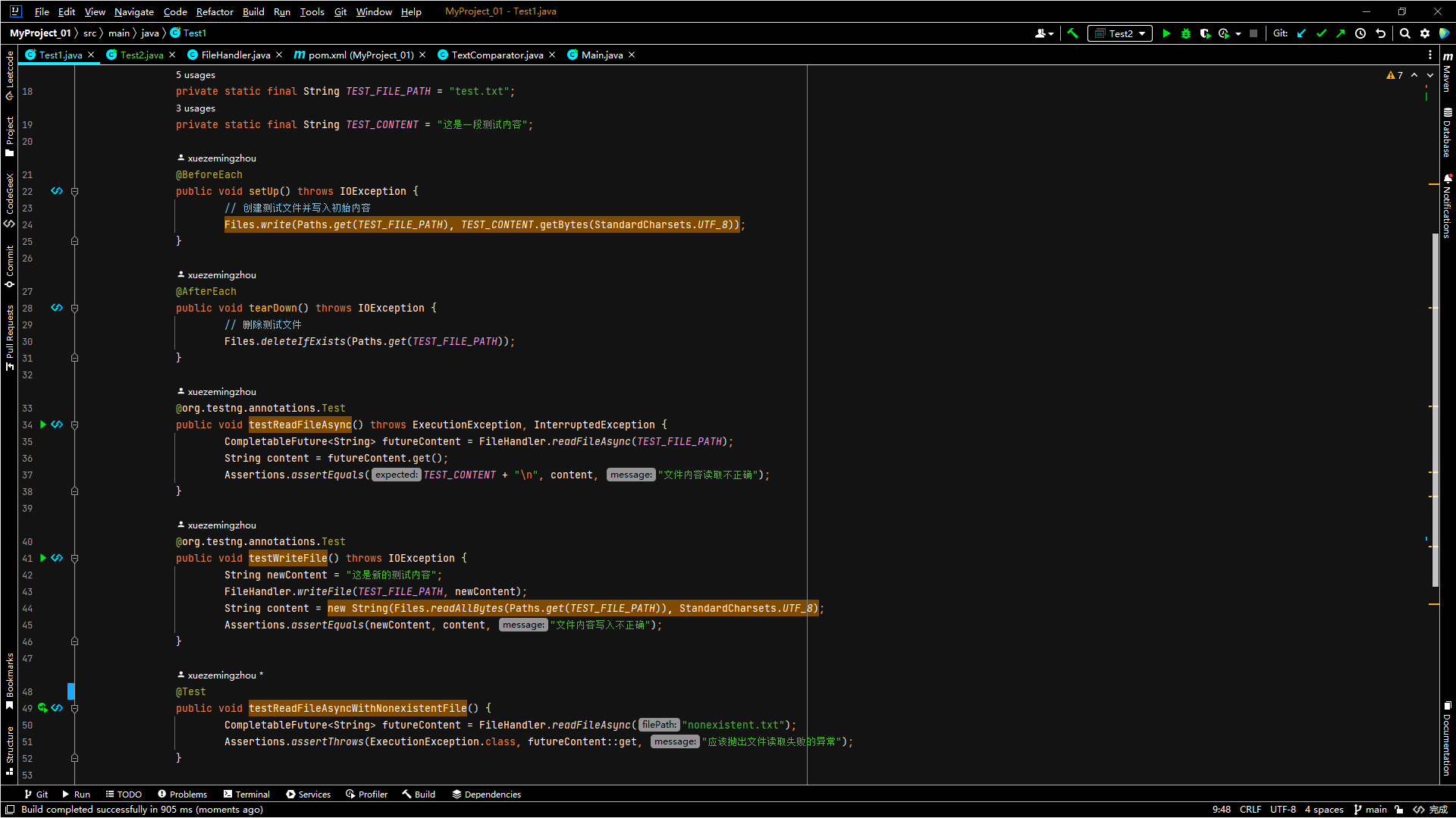
这里并且包括读写异常处理
计算文本相似度测试
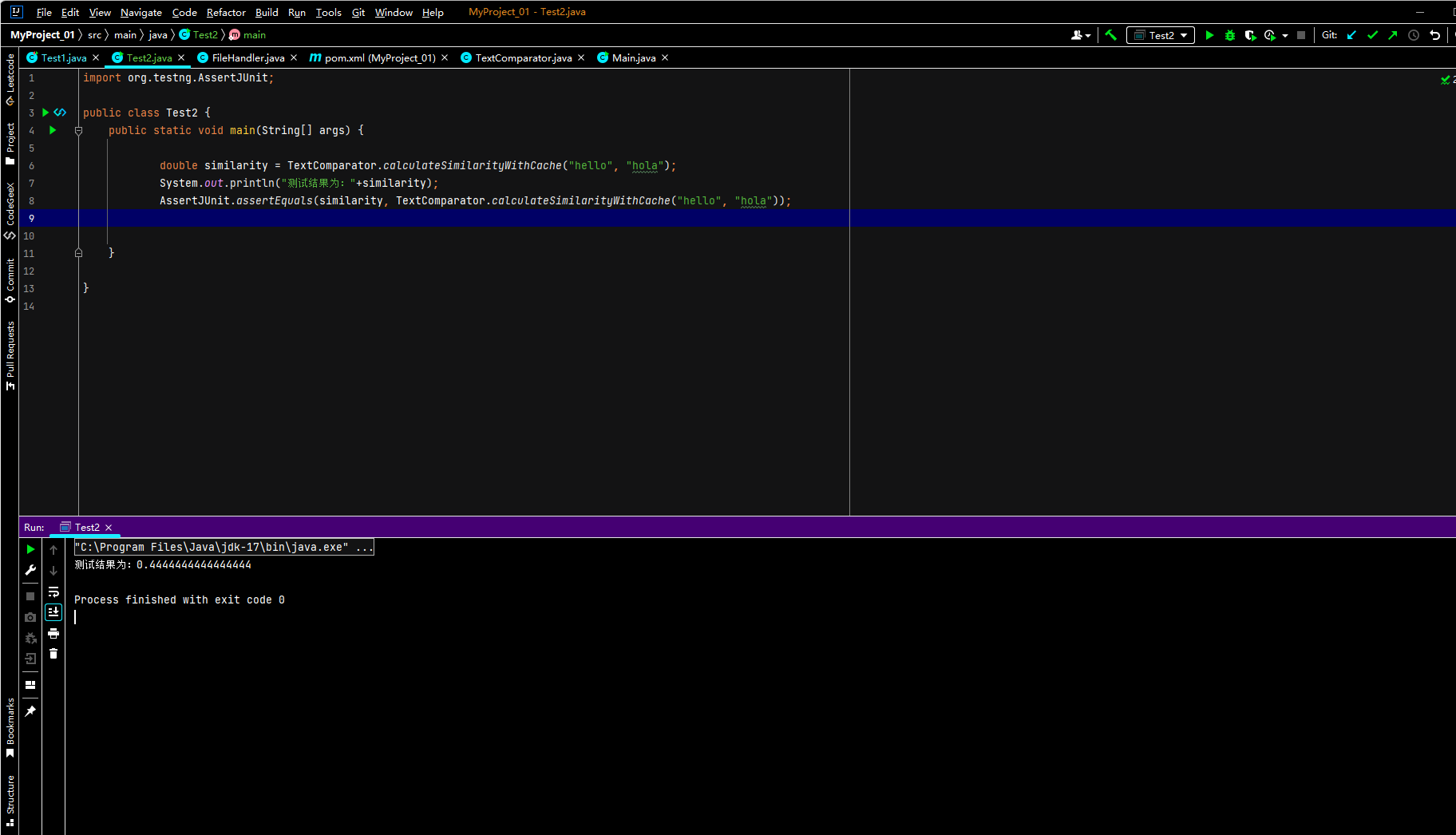
总测试:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号