
架构系统的雪崩理解
1.背景
最近遇到了线上服务的雪崩,查查资料,整理整理。
离线架构更多的是考虑数据写入时的,
- 成功率,建库成功率有几个9
- 吞吐量,上亿数据多久可以完成建库。
- 数据一致性,机房间、同机房副本间。
- 延时,单条数据的写入时间分位值。离线对延时要求可能不严格。
在线架构更多的是考虑数据读取时的,
- 成功率,后端存储稳定性,是否有热点数据。
- qps,系统能支持的并发请求量
- 一致性,排序、策略等是否一致。
- 对时间的延时要求很高。通常一个请求需要再规定时间内返回。
2.什么是雪崩
指分布式系统中经常会出现某个基础服务不可用造成整个系统不可用的情况, 这种现象被称为服务雪崩效应。
离线雪崩时,新数据无法更新,导致队列堵塞。
在线雪崩时,在线无法提供正常的检索服务,从外部看整个系统不可用。
因此,通常雪崩都是说的在线架构。
3. 如何形成的在线雪崩
离线雪崩时,新数据无法更新,导致队列堵塞。
在线雪崩时,在线无法提供正常的检索服务,从外部看整个系统不可用。
因此,通常雪崩都是说的在线架构。
在线请求需要在规定时间内返回结果,通常上游对下游的超时时间会设置稍大一些考虑到下游模块可能需要重试。
下面的图,大致演示了在线架构雪崩,如果底层模块出问题,大量请求为返回,可能导致多个模块对下游的重试,导致最终下游模块由于请求量过大系统不可用。
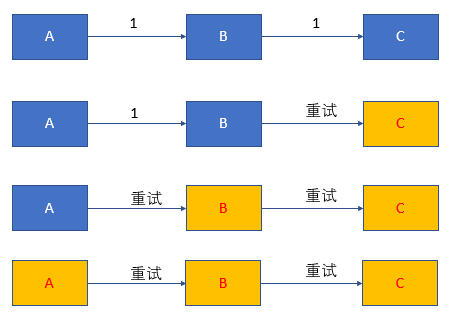
导致雪崩的情况可能有:
- 容量不足。(请求量正常增加)
- 冗余不足。(无法应对高峰、切流量)
- 热点数据访问,导致后端存储无法及时返回。
- 代码bug。死循环等。
4. 如何避免
大部分都是套路,除了因为代码bug。
大致套路,
- 增加缓存。根据业务需要增加。有些服务必须实时数据就不可加。
- 增加容量。系统需要有一定冗余度。
- 定时压测。了解当前系统可接受的最大请求压力。
- 增加有效的监控报警。
- 增加降级策略。临近雪崩时,模块自动丢失部分请求;重试次数减少。
参考:
(1) https://segmentfault.com/a/1190000005988895
(2) https://blog.csdn.net/starryninglong/article/details/65628337


