
Kafka学习笔记
最近在看“kafk权威指南”,记录一下。
1. kafka是一个队列,开源的发布订阅系统,可以支持在线、离线任务。
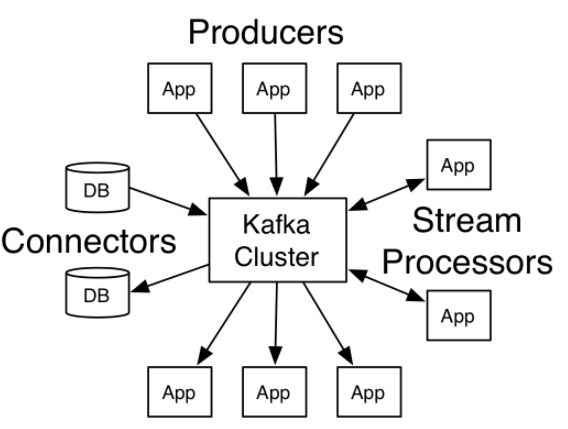
2. kafka作为队列系统,下游从kafka拉取数据并将处理成功信息反馈到kafka,可以实现下游至少处理一次,保证不丢数据。
可以结合其他启动(如去重等)实现消费一次且仅一次。
消费者客户端可以在本地记录当前的offeset,kafka支持从特定partition的offset读取数据。
3. kafka中同一个topic主题,代表一种数据或者同一类数据生成者生成的数据。
同一个topic可以支持多个partition,支持自定义partition规则,实现同一个上游数据hash到同一个partition。
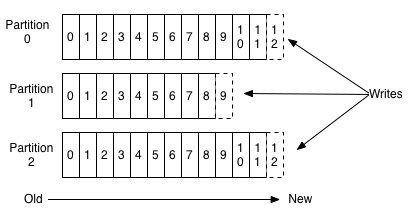
4. kafka同一个消费者群组对应的一个topic的partition个数平均分配。
同一个topic的一个patition只能被一个消费者消费,同一个消费者可以消费topic的多个partition。
如果消费者群组中消费者数量大于topic中partition数量,则部分消费者没有partition可以进行消费。
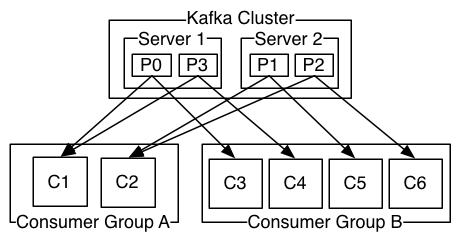
5. kafka中当有新的broker/消费者加入时,都会触发再均衡,观察者模式。
生产者再均衡,生产者发数据到那些broker。
消费者再均衡,消费者处理那些partition。
6. kafka客户端要自己负责把生产者请求和获取请求发送到正确的broker上。
kafka中任意一个broker都提供元信息请求, 包括主题的分区、每个分区有那些副本、以及那个副本是首领等信息。
7. kafka生成者数据提交ACK问题。
acks=0,不需要确认。
acks=1,只需要集群的首领节点写入成功,就可以回复生成者确认信息。
acks=all,只有当所有参与复制的节点全部收到消息,生产者才会收到确认信。
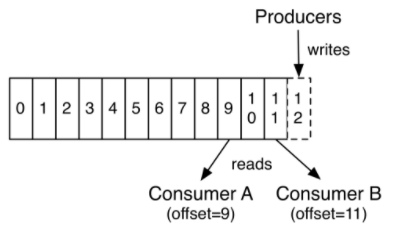
8. kafka消费者数据提交offset问题。
每个partition都有offset,并且同一个partition可以有多个消费者,他们的offest互不影响。
9. kafka数据复制
每个partition都需要有多个副本,副本数可以配置。越多系统越稳定,但是副本一致也越困难。通常3副本就可以。
分区首领是同步副本,负责数据的生成者数据的写入,负责消费者消费。其他同步副本是追随者,负责实时同步首领副本消息。
一个不同步的副本,通过与zk重新连接并从首领哪里获取最新信息,重新成为同步负责。
只有同步副本,才可以在之前首领副本挂掉后成为新副本首领。
参考:
http://kafka.apache.org/


