
Python 爬虫实例(13) 下载 m3u8 格式视频
Python requests 下载 m3u8 格式 视频
最近爬取一个视频网站,遇到 m3u8 格式的视频需要下载。
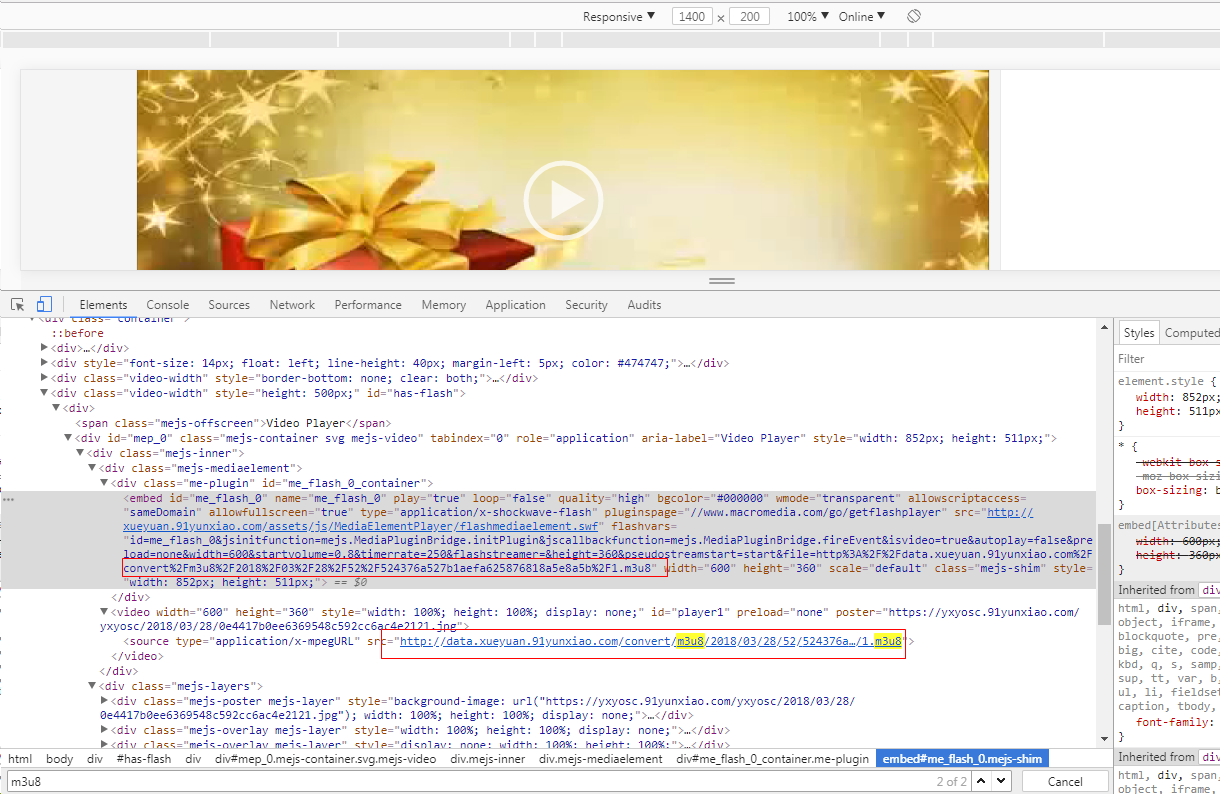
抓包分析,视频文件是多个 ts 文件,什么是 ts文件,请去百度吧:
附图:抓包分析过程
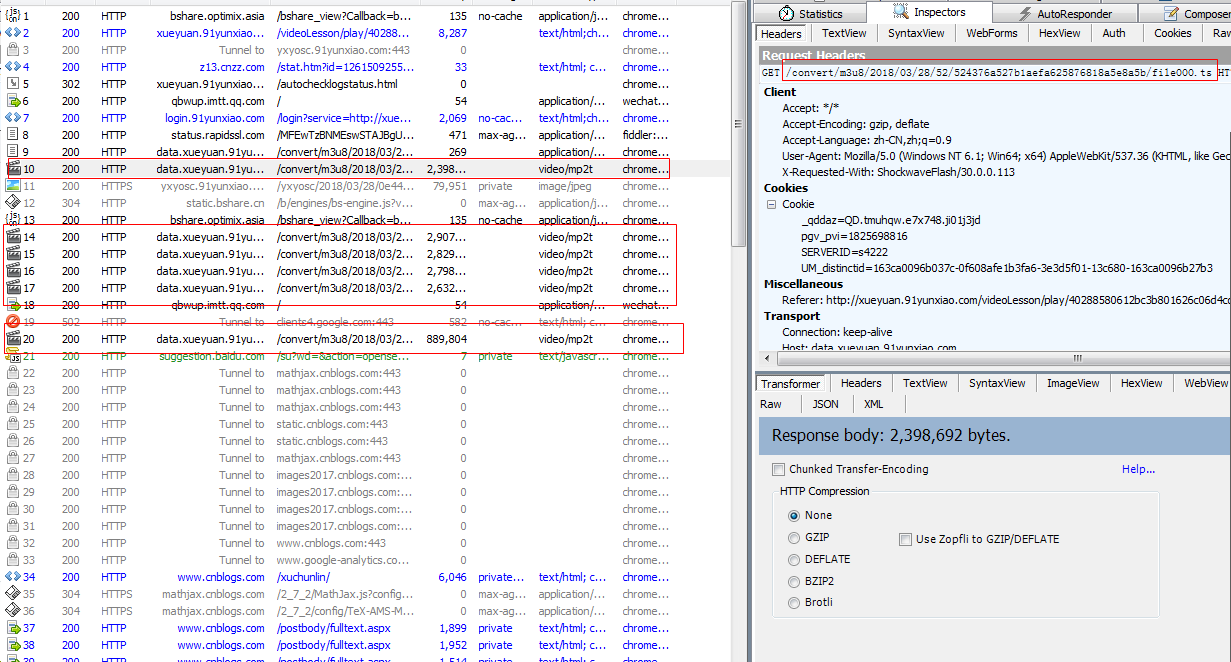
直接把 ts文件请求下来,然后合并 ts文件,如果想把 ts文件转换 MP4 格式,请自行百度吧。
完整下载代码:

#coding=utf-8 import requests import re import time from bs4 import BeautifulSoup import os session = requests.session() def spider(): url = 'http://xueyuan.91yunxiao.com/videoLesson/play/4028e4115fc893fb015fecfc56240b66.html' headers = { "Host":"xueyuan.91yunxiao.com", "Connection":"keep-alive", "Upgrade-Insecure-Requests":"1", "User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36", "Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8", "Referer":"http://xueyuan.91yunxiao.com/videoLesson/detail/4028e4115fc893fb015fecfafe200b63.html", "Accept-Encoding":"gzip, deflate", "Accept-Language":"zh-CN,zh;q=0.9", "Cookie":"UM_distinctid=163cae8de9816e-0d08a36800162a-454c092b-ff000-163cae8de99141; _qddaz=QD.n4xqjl.egbt1i.ji0ex7zv; pgv_pvi=6411171840; SERVERID=s50; JSESSIONID=5D1C6375394E84E931FBD1C774876563; CNZZDATA1261509255=2100416221-1528114457-%7C1528207774", } try: result = session.get(url=url,headers=headers).content except: result = session.get(url=url,headers=headers).content result_replace = str(result).replace('\n','') print result_replace item_url = re.findall('<source type="application/x-mpegURL" src="(.*?)" />',result_replace)[0].replace('1.m3u8','') print item_url # for page in range(1,11): headers2 = { "Host":"data.xueyuan.91yunxiao.com", "Connection":"keep-alive", "User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36", "X-Requested-With":"ShockwaveFlash/29.0.0.171", "Accept":"*/*", "Referer":"http://xueyuan.91yunxiao.com/videoLesson/play/4028e4115fc893fb015fecf8e4d60b61.html", "Accept-Encoding":"gzip, deflate", "Accept-Language":"zh-CN,zh;q=0.9", "Cookie":"UM_distinctid=163cae8de9816e-0d08a36800162a-454c092b-ff000-163cae8de99141; _qddaz=QD.n4xqjl.egbt1i.ji0ex7zv;
pgv_pvi=6411171840; SERVERID=s4222", } for page in range(0,16): if page < 10: page_str = "0" + str(page) else: page_str = str(page) "http://data.xueyuan.91yunxiao.com/convert/m3u8/2017/11/24/ed/ededf4dc7471a05550cc521196d28ebc/file006.ts" item_url1 = item_url + "file0" + str(page_str) + ".ts" print item_url1 dir_path = "E:/1" file_name = page_str + ".ts" response = session.get(url=item_url1,headers=headers2) if response.status_code == 200: if not os.path.exists(dir_path): os.makedirs(dir_path) total_path = dir_path + '/' + file_name if len(response.content) == int(response.headers['Content-Length']): # print total_path with open(total_path, 'wb') as f: for chunk in response.iter_content(1024): f.write(chunk) f.close() spider()
如果觉得对您有帮助,麻烦您点一下推荐,谢谢!
好记忆不如烂笔头
好记忆不如烂笔头


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术