
正则和xpath在网页中匹配字段的效率比较
1. 测试页面是 https://www.hao123.com/,这个是百度的导航
2. 为了避免网络请求带来的差异,我们把网页下载下来,命名为html,不粘贴其代码。
3.测试办法:
我们在页面中找到 百度新闻 关键字的链接,为了能更好的对比,使程序运行10000次,比较时间差异:
1.正则编码及其时间
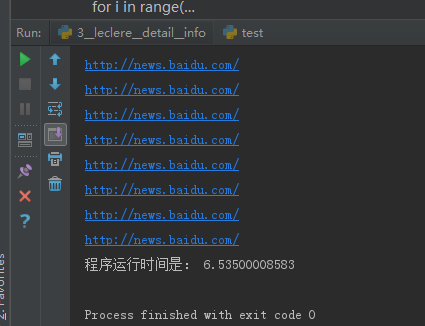
1 2 3 4 5 6 7 | start_time = time.time()for i in range(0,10000): baidu_news = re.findall('腾讯新闻</a></span><span><a class="sitelink mainlink singglelink" cls="xw,n" alog-custom="ind:xw,sal:0,atd:" href="(.*?)">百度新闻</a>',html)[0] print baidu_newsend_time = time.time()print "程序运行时间是:",end_time - start_time |
运行时间:6.5 秒钟
2.xpath 编码及其时间

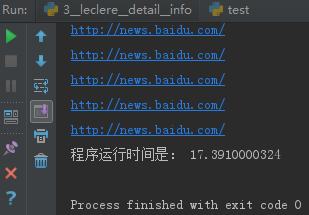
start_time = time.time() selector = etree.HTML(html) for i in range(0,10000): content=selector.xpath('//*[@id="coolsite-top"]/div[4]/span[3]/a/@href')[0] print content end_time = time.time() print "程序运行时间是:",end_time - start_time
运行时间:17.39 秒钟
总结:其中 selector = etree.HTML(html) 将源码转化为能被XPath匹配的格式,这个过程失比较耗时的。
结论:正则效率优于xpath
如有异议,请联系作者,谢谢
如果觉得对您有帮助,麻烦您点一下推荐,谢谢!
好记忆不如烂笔头
好记忆不如烂笔头


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术