解决 scrapy 爬虫出现Forbidden by robots.txt
我们在爬取网站的时候,scrapy 默认的是遵循 robots.txt 协议,怎么破解这个文件
操作很简单,找到setting 文件

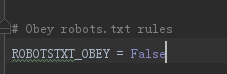
直接改成
如果觉得对您有帮助,麻烦您点一下推荐,谢谢!
好记忆不如烂笔头
好记忆不如烂笔头

我们在爬取网站的时候,scrapy 默认的是遵循 robots.txt 协议,怎么破解这个文件
操作很简单,找到setting 文件
直接改成


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术