

python 做爬虫真的很慢吗?(协程并发测试 )
总有人说python做爬虫速度慢,能开并发数少,至于为什么慢就是说不上来,今天就是测试一下python语言的速度和并发数量。
在网络爬虫中,影响速度的有数据下载,数据解析,数据存储,最主要的影响是数据下载和数据存储,数据下载影响是网络IO,数据存储是磁盘IO,本次模拟数据下载是1s,然后数据存储直接是把数据存储到redis中,redis是内网的redis库。下面一次并发10w,100w,100w个任务的耗时情况。
服务器是使用的个人笔记本,配置如下

测试代码如下:

#-*-coding:utf-8-*- import time from gevent import monkey monkey.patch_all() import gevent import redis RedisDatabases = { "host": "10.10.25.207", "port": "6379", } r = redis.Redis(host=RedisDatabases['host'],port=RedisDatabases['port'], db=0) def spider(item): time.sleep(1) r.sadd('test',item) if __name__ == "__main__": start_time = time.time() result_List = [page for page in range(10000)] print ("本次接口获得的IP个数是:", len(result_List)) from gevent import pool pool = pool.Pool(128) jobs = [] for item in result_List: proxie = item jobs.append(pool.spawn(spider, item)) gevent.joinall(jobs, timeout=3600) print("程序验证耗时:", time.time() - start_time)
测试一:
1w个任务,并发数128 耗时
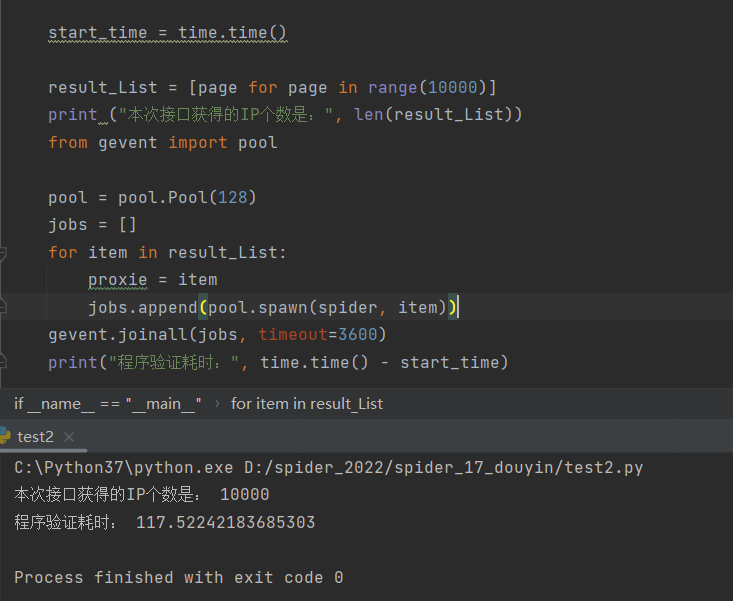
测试二:
10w个任务,并发数128 耗时
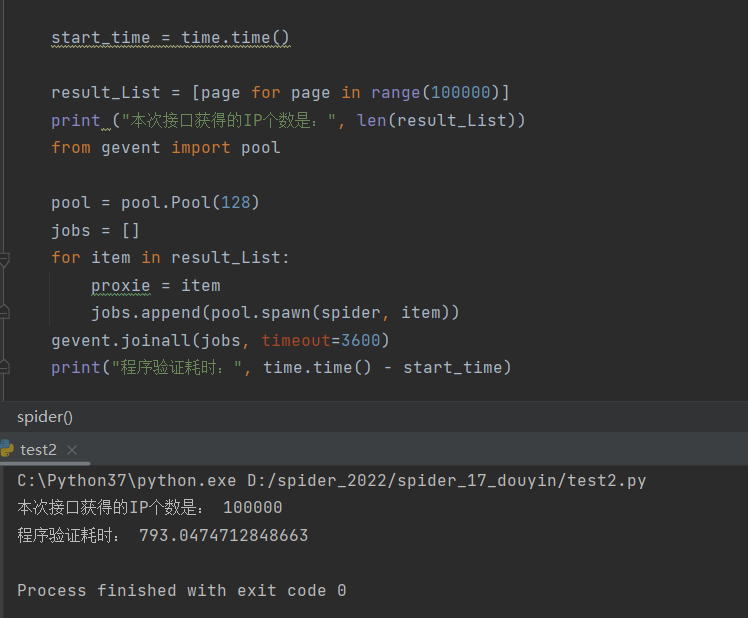
测试三:
100w个任务,并发数128 耗时
测试四:
100w个任务,并发数256 耗时
测试五:
100w个任务,并发数512耗时
测试六:
100w个任务,并发数1024耗时

测试七:
100w个任务,并发数2048耗时
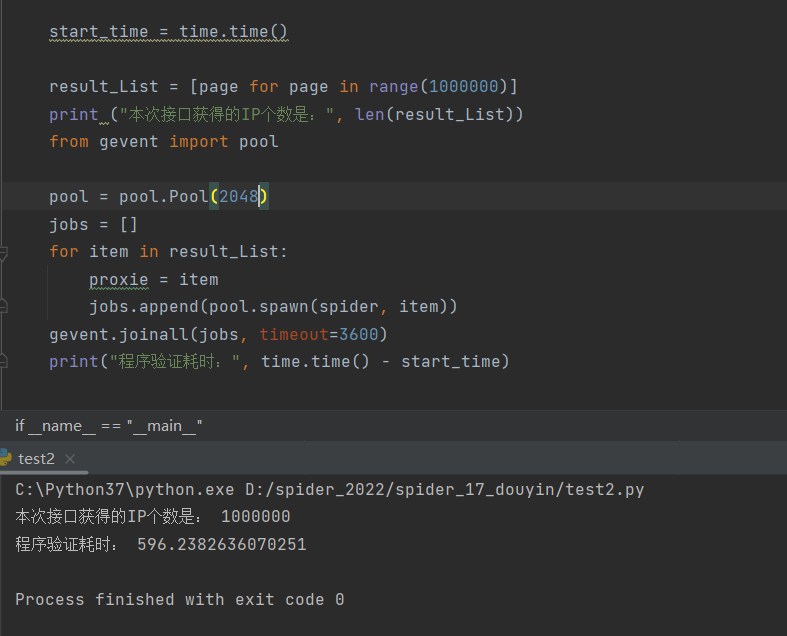
测试八:
100w个任务,并发数4096耗时
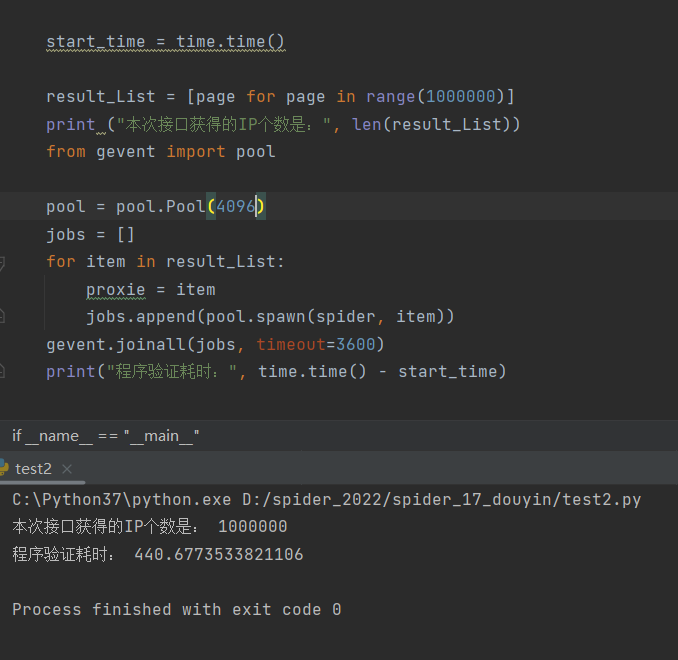
测试九:
100w个任务,并发数8192耗时
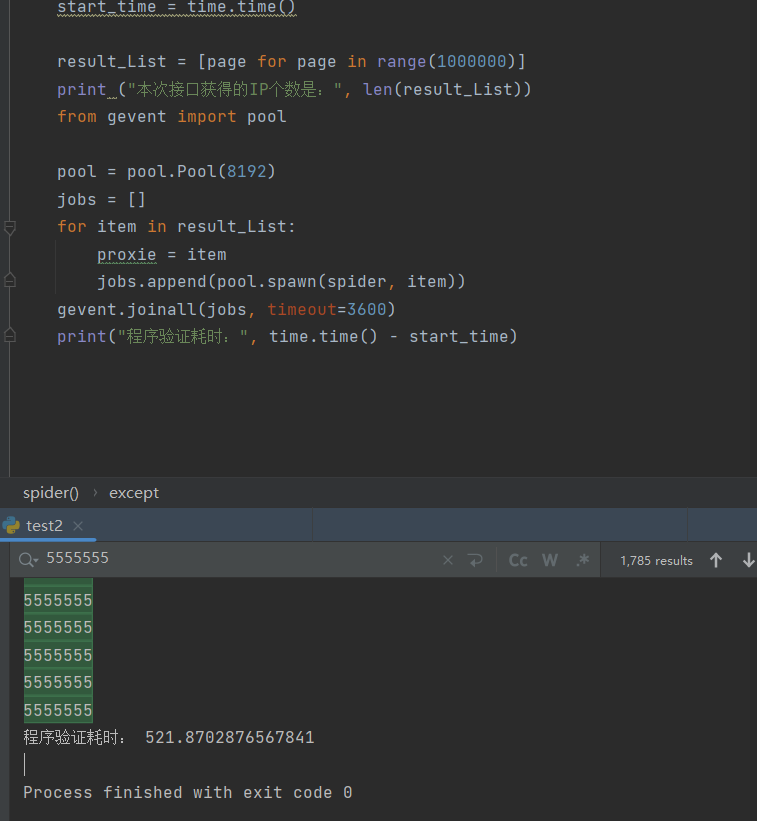
并发数 8192 耗时521s,并且redis连接错误1785个,有时候不是并发数开的越大速度就越快
统计图:

总结:

影响爬虫因素的方式是多种多样的,比如数据下载,数据存储,数据解析,数据库连接,cpu,内存,路由器,带宽等因素,但是绝对不是因为python是解释型语言,它的速度就应该理所当然的比其他的开发语言慢,强制说python做爬虫就比go做爬虫慢或者能开的并发数量少,这肯定是片面的认知。用python做爬虫主要是优点是开发速度快,代码维护方便,如果一味的追求效率,可以用c或者c++,开发半个月,维护要两天,等爬到数据的时候,黄花菜都凉了。
如果觉得对您有帮助,麻烦您点一下推荐,谢谢!
好记忆不如烂笔头
好记忆不如烂笔头


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架
2018-08-01 爬虫 大规模数据 采集心得和示例