
crawlab 实现批量添加爬虫的功能
1. 前言
crawlab 是基于Golang的分布式爬虫管理平台,但是没有实现批量添加爬虫的功能。
作为党国的优秀青年,怎么可以容忍这件事情呢,那就实现一个脚本去批量添加爬虫吧。
2. 主要解决的问题是
需要抓取的网站有几百个,爬虫代码编写完毕,但是需要手动的去添加爬虫代码,一个一个的去添加,累死人了,
因此想办法去编写一个脚本去实现爬虫的功能。
3. 难点
文件上传使用的是 multipart/form-data; boundary=----WebKitFormBoundaryxHvDD0BUGzUw2qhS
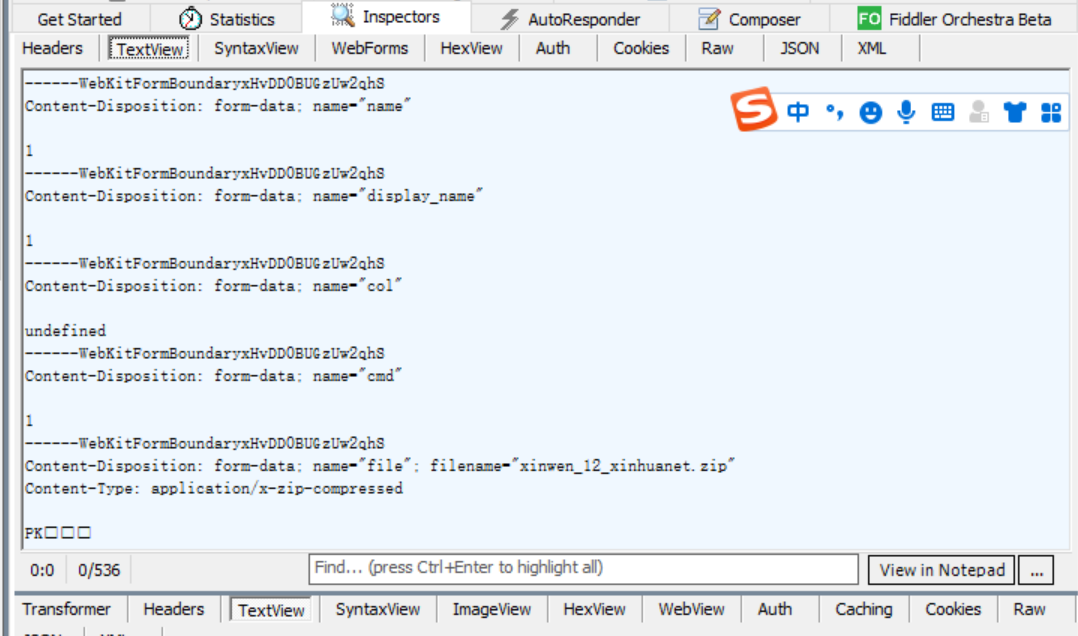
瞬间懵逼了,multipart/form-data; 是什么玩意呢?boundary=----WebKitFormBoundaryxHvDD0BUGzUw2qhS 又是干啥的啊?然后就去疯狂的搜索资料

根据http/1.1 rfc 2616的协议规定,我们的请求方式只有OPTIONS、GET、HEAD、POST、PUT、DELETE、TRACE等, 那为为何我们还会有multipart/form-data请求之说呢?这就要从头来说了。 http协议规定以ASCII码传输,建立在tcp,ip协议智商的引用规范,规范内容把http请求分成3个部分,状态行,请求头,请求体。 所有的方法,实现都是围绕如何使用和组织这三部分来完成了,万变不离其宗,http的知识大家可以问度娘。 既然上面请求方式里面没有multipart/form-data那这个请求又是怎么回事呢, 其实是一回事,multipart/form-data也是在post基础上演变而来的,具体如下: 1.multipart/form-data的基础方式是post,也就是说通过post组合方式来实现的。 2.multipart/form-data于post方法的不同之处在于请求头和请求体。 3.multipart/form-data的请求头必须包含一个特殊的头信息:Content-Type, 其值也必须为multipart/form-data,同时还需要规定一个内容分割用于分割请求提中多个post的内容, 如文件内容和文本内容是需要分隔开来的,不然接收方就无法解析和还原这个文件了, 具体的头信息如下: Content-Type: multipart/form-data; boundary=${bound}
下一步直接上代码吧:
代码仅仅是演示作用,如果有需要请评论后获得指导
xxxxxxxxxxxxxxxxxxxxxxx 请根据自己的代码去修改
file_name = "xxxxxxxxxxxxxxxxxxxxxxx" f = zipfile.ZipFile( file_name + '.zip', 'w', zipfile.ZIP_DEFLATED) for i in ["contest.py", file_name + ".py"]: file = i.split('/')[-1] f.write(i, file) f.close() url = 'xxxxxxxxxxxxxxxxxxxxxxx' params = { 'name': file_name, 'display_name': file_name, 'col': "undefined", 'cmd': "", } print(json.dumps(params)) with open('xxxxxxxxxxxxxxxxxxxxxxx.zip', 'rb') as f_: m = MultipartEncoder( fields={ "params":json.dumps(params), 'file': (file_name + '.zip', f_,'application/x-zip-compressed'), }, ) headers = { 'Content-Type': m.content_type, "Authorization": "xxxxxxxxxxxxxxxxxxxxxxx", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36", "Accept": "*/*", "Origin": "xxxxxxxxxxxxxxxxxx", "Referer": "xxxxxxxxxxxxxxxxxxxxxxxx", "Accept-Encoding": "gzip, deflate, br", "Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8", "Cookie": "xxxxxxxxxxxxxxxxxxxxxxx" } response = requests.post(url,data=m,verify=False,headers=headers) content = json.loads(response.content)
上面的代码仅仅实现的文件的上传功能,但是没有 项目 和执行命令,在爬虫详情页有一个保存的功能,同样可以用爬虫技术实现这个修改保存的功能
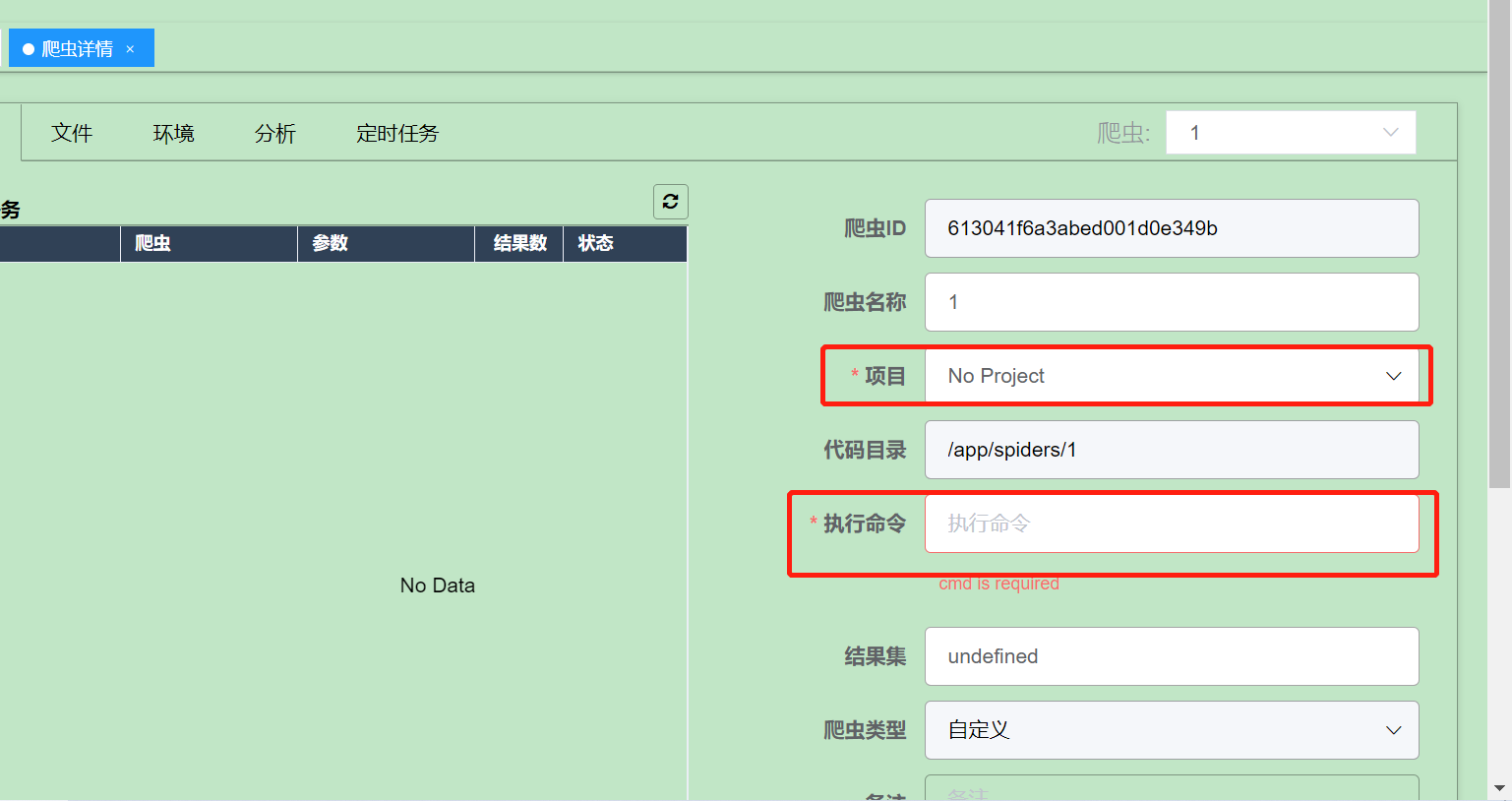
代码如下:
content = json.loads(response.content) _id = content['data']['_id'] file_id = content['data']['file_id'] print(content) false = False data = { "_id": _id, "name": file_name, "display_name": file_name, "type": "customized", "file_id":file_id , "col": "", "site": "", "envs": [], "remark": "", "src": "/app/spiders/" + file_name, "project_id": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx", "is_public": false, "cmd": "python3 " + file_name + ".py", "is_scrapy": false, "spider_names": [], "template": "", "is_git": false, "git_url": "", "git_branch": "", "git_has_credential": false, "git_username": "", "git_password": "", "git_auto_sync": false, "git_sync_frequency": "", "git_sync_error": "", "is_long_task": false, "is_dedup": false, "dedup_field": "", "dedup_method": "", "is_web_hook": false, "web_hook_url": "", "last_run_ts": "0001-01-01T00:00:00Z", "last_status": "", "config": { "name": "", "display_name": "", "col": "", "remark": "", "Type": "", "engine": "", "start_url": "", "start_stage": "", "stages": [], "settings": {}, "cmd": "" }, "latest_tasks": [], "username": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx", "project_name": "", "user_id": "61246ad5a3abed001dfccd82", "create_ts": "2021-09-02T02:22:40.9Z", "update_ts": "2021-09-02T02:22:40.905Z" } url = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" headers1 = { "Host":"crawler.uibe.info", "Connection":"keep-alive", "Content-Length":"1045", "Accept":"application/json, text/plain, */*", "Authorization":"xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx", "sec-ch-ua-mobile":"?0", "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36", "Content-Type":"application/json;charset=UTF-8", "Origin":"xxxxxxxxxxxxxxxxxxxxxxxxx", "Sec-Fetch-Site":"same-origin", "Sec-Fetch-Mode":"cors", "Sec-Fetch-Dest":"empty", "Referer":"xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx", "Accept-Encoding":"gzip, deflate, br", "Accept-Language":"zh-CN,zh;q=0.9,en;q=0.8", "Cookie":"xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx", } res = requests.post(url=url,data=json.dumps(data),headers=headers1).text print(res)
如果觉得对您有帮助,麻烦您点一下推荐,谢谢!
好记忆不如烂笔头
好记忆不如烂笔头


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术