

lambda之美
大前提:jdk8 允许lambda表达式 最好在maven中加入
<properties>
<java.version>1.8</java.version>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
只总结真香案例!!!
案例一:
从"1" "2" "bilibili" "of" "codesheep" "5" "codesheep" "5" "at" "BILIBILI" "codesheep" "23" "CHEERS" "6"中
找出所有 长度>=5的字符串,并且忽略大小写、去除重复字符串,然后按字母排序,最后用“ * ”连接成一个字符串输出
List<String> list = new ArrayList<>();
list.add("1");
···
list,add("6");
String str = list.stream()//list转为stream流
.filter(i -> !isNum(i))//过滤出不是数字的 也就是 得到字符 isNum是自己封装的方法
.filter(i -> i.length()>5)//过滤出长度大于5的
.map(i -> i.toLowerCase())//转为小写
.distinct()//去重
.sorted(Comparator.naturalOrder())//字符串排序
.collect(Collectors.joining("*"));//字符串连接
System.out.println(str);
案例二:
public class Lambda2 {
public static void main(String[] args) {
/**
* 函数接口:Predict
* 抽象方法:test(T t)
* 参数:T
* 返回值类型:Boolean
* 功能:判断真假
* 示例:判断学生身高
* 结果:韩非的身高高于185吗?: false
*/
Predicate<Integer> predicate = x -> x > 185;
Student student = new Student("韩非", 23, 175);
System.out.println("韩非的身高高于185吗?: " + predicate.test(student.getLength()));
/**
* 函数接口:Consumer
* 抽象方法:accept(T t)
* 参数:T
* 返回值类型:void
* 功能:消费消息
* 示例:输出值
* 结果:列东方位 青龙
*/
Consumer<String> consumer = System.out::println;
consumer.accept("列东方位 青龙");
/**
* 函数接口:Function
* 抽象方法:R apply(T t)
* 参数:T
* 返回值类型:R
* 功能:将T映射为R(转换功能)
* 示例:输出student名字
* 结果:韩非
*
* 备注:Student::getName这种lambda表达式写法被称为 方法引用 格式为 ClassName::MethodName
*/
Function<Student, String> function = Student::getName;
String name = function.apply(student);
System.out.println(name);
/**
* 函数接口:Supplier
* 抽象方法:T get()
* 参数:void
* 返回值类型:T
* 功能:生产消息
* 示例:工厂方法
* 结果:10
*/
Supplier<Integer> supplier = () -> Integer.valueOf(BigDecimal.TEN.toString());
System.out.println(supplier.get());
/**
* 函数接口:UnaryOperator
* 抽象方法:T apply(T t)
* 参数:T
* 返回值类型:T
* 功能:一元操作
* 示例:逻辑非(!)
* 结果:false
*/
UnaryOperator<Boolean> unaryOperator = uglily -> !uglily;
Boolean apply2 = unaryOperator.apply(true);
System.out.println(apply2);
//使用BinaryOperator函数式接口 抽象方法T apply(T t, U u) 功能:二元操作 参数T,U 返回值类型T 求两个数乘积
/**
* 函数接口:BinaryOperator
* 抽象方法:T apply(T t, U u)
* 参数:T,U
* 返回值类型:T
* 功能:二元操作
* 示例:求两个数乘积
* 结果: 6
*/
BinaryOperator<Integer> operator = (x, y) -> x * y;
Integer integer = operator.apply(2, 3);
System.out.println(integer);
/**
* 演示函数式接口
* 结果:我是一个演示的函数式接口
*/
test(() -> "我是一个演示的函数式接口");
}
/**
* 演示自定义函数式接口使用
*
* @param worker
*/
public static void test(Worker worker) {
String work = worker.work();
System.out.println(work);
}
public interface Worker {
String work();
}
}
案例三:
/**
* 惰性求值:只描述Stream,操作的结果也是Stream,这样的操作称为惰性求值。惰性求值可以像建造者模式一样链式使用,最后再使用及早求值得到最终结果。
* 及早求值:得到最终的结果而不是Stream,这样的操作称为及早求值。
*
* 常用的流:collect(Collectors.toList())
* 功能:将流转为list
* 结果:[Student(name=路飞, age=22, length=175, specialisies=null), Student(name=红发, age=40, length=180, specialisies=null)]
*/
List<Student> studentList = Stream.of(
new Student("路飞", 22, 175),
new Student("红发", 40, 180)
).collect(Collectors.toList());
System.out.println(studentList);
案例四:
/**
* 常用的流:filter
* 功能:顾名思义,起过滤筛选的作用。内部就是Predicate接口。惰性求值。
* 示例:筛选出身高小于180的同学
* 结果:[Student(name=路飞, age=22, length=175, specialisies=null)]
*/
List<Student> students = new ArrayList<>(3);
students.add(new Student("路飞", 22, 175));
students.add(new Student("红发", 40, 180));
students.add(new Student("白胡子", 50, 185));
List<Student> list = students.stream()
.filter(stu -> stu.getLength() < 180)
.collect(Collectors.toList());
System.out.println(list);
案例五:
/**
* 常用的流:map
* 功能:转换功能,内部就是Function接口。惰性求值
* 示例:获取所有同学的名字
* 结果:[路飞, 红发, 白胡子]
*/
List<Student> students = new ArrayList<>(3);
students.add(new Student("路飞", 22, 175));
students.add(new Student("红发", 40, 180));
students.add(new Student("白胡子", 50, 185));
List<String> names = students.stream().map(student -> student.getName())
.collect(Collectors.toList());
System.out.println(names);
案例六:
/**
* 常用的流:flatMap
* 功能:将多个Stream合并为一个Stream。惰性求值
* 示例:调用Stream.of的静态方法将两个list转换为Stream,再通过flatMap将两个流合并为一个
* 结果:[
* Student(name=路飞, age=22, length=175, specialisies=null),
* Student(name=红发, age=40, length=180, specialisies=null),
* Student(name=白胡子, age=50, length=185, specialisies=null),
* Student(name=艾斯, age=25, length=183, specialisies=null),
* Student(name=雷利, age=48, length=176, specialisies=null)
* ]
*/
List<Student> students = new ArrayList<>(3);
students.add(new Student("路飞", 22, 175));
students.add(new Student("红发", 40, 180));
students.add(new Student("白胡子", 50, 185));
List<Student> studentList = Stream.of(students,
Arrays.asList(new Student("艾斯", 25, 183),
new Student("雷利", 48, 176)))
.flatMap(students1 -> students1.stream()).collect(Collectors.toList());
System.out.println(studentList);
案例七:
/**
* 常用的流:max min
* 功能:我们经常会在集合中求最大或最小值,使用流就很方便。及早求值。
* 示例:得到年龄最大和最小的同学
* 结果:Student(name=白胡子, age=50, length=185, specialisies=null)
* Student(name=路飞, age=22, length=175, specialisies=null)
*
* 补充:max、min接收一个Comparator(例子中使用java8自带的静态函数,只需要传进需要比较值即可。)
* 并且返回一个Optional对象,该对象是java8新增的类,专门为了防止null引发的空指针异常。可以使用max.isPresent()判断是否有值;
* 可以使用max.orElse(new Student()),当值为null时就使用给定值;也可以使用max.orElseGet(() -> new Student());
* 这需要传入一个Supplier的lambda表达式。
*/
List<Student> students = new ArrayList<>(3);
students.add(new Student("路飞", 22, 175));
students.add(new Student("红发", 40, 180));
students.add(new Student("白胡子", 50, 185));
Optional<Student> max = students.stream()
.max(Comparator.comparing(stu -> stu.getAge()));
Optional<Student> min = students.stream()
.min(Comparator.comparing(stu -> stu.getAge()));
//判断是否有值
if (max.isPresent()) {
System.out.println(max.get());
}
if (min.isPresent()) {
System.out.println(min.get());
}
案例八:
/**
* 常用的流:count
* 功能:统计功能,一般都是结合filter使用,因为先筛选出我们需要的再统计即可。及早求值
* 示例:统计年龄小于45的人数
* 结果:年龄小于45岁的人数是:2
*/
public static void main(String[] args) {
List<Student> students = new ArrayList<>(3);
students.add(new Student("路飞", 22, 175));
students.add(new Student("红发", 40, 180));
students.add(new Student("白胡子", 50, 185));
long count = students.stream().filter(s1 -> s1.getAge() < 45).count();
System.out.println("年龄小于45岁的人数是:" + count);
}
案例九:
/**
* 常用的流:reduce
* 功能:reduce 操作可以实现从一组值中生成一个值。前面案例用到的 count 、 min 和 max 方法,因为常用而被纳入标准库中。事实上,这些方法都是 reduce 操作。及早求值。
* 示例:reduce接收了一个初始值为0的累加器,依次取出值与累加器相加,最后累加器的值就是最终的结果
* 结果:10
*/
public static void main(String[] args) {
Integer reduce = Stream.of(1, 2, 3, 4).reduce(0, (acc, x) -> acc+ x);
System.out.println(reduce);
}
案例十:
/**
* 收集器,一种通用的、从流生成复杂值的结构。只要将它传给 collect 方法,所有
* 的流就都可以使用它了。标准类库已经提供了一些有用的收集器,以下示例代码中的收集器都是从 java.util.stream.Collectors 类中静态导入的。
*
*
* 结果:人数最多的班级是:一班 一班平均年龄是:37.666666666666664
*/
public static void main(String[] args) {
List<Student> students1 = new ArrayList<>(3);
students1.add(new Student("路飞", 23, 175));
students1.add(new Student("红发", 40, 180));
students1.add(new Student("白胡子", 50, 185));
OutstandingClass ostClass1 = new OutstandingClass("一班", students1);
//复制students1,并移除一个学生
List<Student> students2 = new ArrayList<>(students1);
students2.remove(1);
OutstandingClass ostClass2 = new OutstandingClass("二班", students2);
//将ostClass1、ostClass2转换为Stream
Stream<OutstandingClass> classStream = Stream.of(ostClass1, ostClass2);
OutstandingClass outstandingClass = biggestGroup(classStream);
System.out.println("人数最多的班级是:" + outstandingClass.getName());
System.out.println("一班平均年龄是:" + averageNumberOfStudent(students1));
}
/**
* 获取人数最多的班级
* 无论选择哪种返回值语句都可以
* 区别是 Optional中对null做了许多封装,可以进行空值的校验
* orElseGet方法 如果创建的Optional中有值存在,则返回此值,否则返回一个由Supplier接口生成的值
*/
private static OutstandingClass biggestGroup(Stream<OutstandingClass> outstandingClasses) {
// return outstandingClasses.max(Comparator.comparing(stu -> stu.getStudents().size())).get();
return Optional.of(outstandingClasses.max(Comparator.comparing(stu -> stu.getStudents().size())).get()).orElseGet(OutstandingClass:: new );
}
/**
* 计算平均年龄
*/
private static double averageNumberOfStudent(List<Student> students) {
return students.stream().collect(Collectors.averagingInt(Student::getAge));
}
案例十一:
/**
* 常用的流:Predicate
* 功能:将流分解成两个集合,接收一个Predicate函数式接口。
* 示例:按照会sing的和不会sing对学生进行分拆
* 结果:{
* false=[Student(name=红发, age=40, length=180, specialisies=swimming), Student(name=白胡子, age=50, length=185, specialisies=dance)],
* true=[Student(name=路飞, age=23, length=175, specialisies=sing)]
* }
* 和Collectors.groupingBy() 分组类似
*/
List<Student> students = new ArrayList<>(3);
Student stu1 = new Student("路飞", 23, 175);
stu1.setSpecialisies("sing");
students.add(stu1);
Student stu2 = new Student("红发", 40, 180);
stu2.setSpecialisies("swimming");
students.add(stu2);
Student stu3 = new Student("白胡子", 50, 185);
stu3.setSpecialisies("dance");
students.add(stu3);
Map<Boolean, List<Student>> listMap = students.stream().collect(
Collectors.partitioningBy(stu ->
stu.getSpecialisies().
contains(SpecialityEnum.SING.name)));
System.out.println(listMap);
//使用Collectors.groupingBy()也可完成同样的功能
Map<Boolean, List<Student>> li = students.stream().collect(Collectors.groupingBy(student -> student.getSpecialisies().contains(SpecialityEnum.SING.name)));
System.out.println(li);
案例十二:
/**
* 常用的流:数据分组groupingBy 分组条件通常会被作为Map的key
* 功能:数据分组是一种更自然的分割数据操作,与将数据分成 ture 和 false 两部分不同,可以使用任意值对数据分组。Collectors.groupingBy接收一个Function做转换。
* 示例:按照会特长对学生进行分组
* 结果:{
* swimming=[Student(name=红发, age=40, length=180, specialisies=swimming)],
* sing=[Student(name=路飞, age=23, length=175, specialisies=sing)],
* dance=[Student(name=白胡子, age=50, length=185, specialisies=dance)]
* }
* 分组条件可以拼接多个 但是要和声明的类型(Map的key)一致
* 示例:声明类型是String
* 分组条件:特长***名字 stu.getSpecialisies()+"***"+stu.getName()
* 结果:{
* dance***白胡子=[Student(name=白胡子, age=50, length=185, specialisies=dance)],
* sing***路飞=[Student(name=路飞, age=23, length=175, specialisies=sing)],
* swimming***红发=[Student(name=红发, age=40, length=180, specialisies=swimming)]
* }
*/
List<Student> students = new ArrayList<>(3);
Student stu1 = new Student("路飞", 23, 175);
stu1.setSpecialisies("sing");
students.add(stu1);
Student stu2 = new Student("红发", 40, 180);
stu2.setSpecialisies("swimming");
students.add(stu2);
Student stu3 = new Student("白胡子", 50, 185);
stu3.setSpecialisies("dance");
students.add(stu3);
Map<String, List<Student>> listMap =
students.stream().collect(
Collectors.groupingBy(stu -> stu.getSpecialisies()));
System.out.println(listMap);
Map<String, List<Student>> lis =
students.stream().collect(
Collectors.groupingBy(stu -> stu.getSpecialisies()+"***"+stu.getName()));
System.out.println(lis);
如果要统计 各有多少
Map<String, Long> lisSize = students.stream().collect(
Collectors.groupingBy(Student::getSpecialisies, Collectors.counting())
);
如果要按照List某个属性的顺序保持不变则可使用
Map<String, List<Student>> lisSize = students.stream().collect(
Collectors.groupingBy(Student::getSpecialisies, LinkedHashMap::new, Collectors.toList())
);
案例十三:
/**
* 常用的流:拼接joining 有三个参数,第一个是分隔符,第二个是前缀符,第三个是后缀符。也可以不传入参数Collectors.joining(),这样就是直接拼接。
* 功能:类似stringbuilder这样循环append("a") append("b") append("c")拼接
* 示例:将所有学生的名字拼接起来
* 结果:[路飞,红发,白胡子]
*/
List<Student> students = new ArrayList<>(3);
students.add(new Student("路飞", 22, 175));
students.add(new Student("红发", 40, 180));
students.add(new Student("白胡子", 50, 185));
String names = students.stream()
.map(Student::getName).collect(Collectors.joining(",","[","]"));
System.out.println(names);
案例十四:
/**
* 接口:Consumer 顾名思义,它是“消费者的含义”,接受参数而不返回值
* 示例:打印消息
* 结果:hello world
* hello java
* hhhhh
* hhhhh
* hhhhh
*/
Consumer c = System.out::println;
c.accept("hello world");//打印hello world
c.accept("hello java");//打印hello java
c.andThen(c).andThen(c).accept("hhhhh");//连续打印三次hhhhh 而不是hello java hello java hhhhh
案例十五:
/**
* 接口:Function 代表的含义是“函数”,其实和上面的 Consumer有点像,不过 Function既有输入,也有输出,使用更加灵活
* 示例:对一个整数先乘以 2,再计算平方值
* 结果:36 5184
* 过程:先走apply传递参数3 然后执行f1=3*2得到6 然后执行f2=6*6得到36
* 先走apply传递参数3 然后执行f1=3*2得到6 然后执行f2=6*6得到36 然后执行f1=36*2得到72 然后执行f2=72*72得到5184
* andThen的参数就是 Function类型的after 即接下里执行的函数
*/
Function<Integer,Integer> f1 = i -> i*2;
Function<Integer,Integer> f2 = i -> i*i;
Consumer c = System.out::println;
c.accept(f1.andThen(f2).apply(3));
c.accept(f1.andThen(f2).andThen(f1).andThen(f2).apply(3));
案例十六:空值校验
/**
* 接口:Optional 本质是个容器,你可以将你的变量交由它进行封装,这样我们就不用显式对原变量进行 null值检测,防止出现各种空指针异常
* 示例:获取学生科目的成绩
*/
public static Integer getScore(Student stu){
return Optional.ofNullable(stu).map(Student::getSubject).map(Subject::getScore).orElse(null);
}
//常规做法 判断学生是否为空,不为空得到学科,判断学科是否为空,不为空取值 如果有很多层包着 简直是俄罗斯套娃 惨不忍睹
public static Integer getScore(Student stu){
if(stu != null){
Subject sub = stu.getSubject();
if (sub != null){
return sub.getScore();
}
}
return null;
}
Optional<Student> os = studentMapper.findStudentById("123");
if(os.isPresent()){
Student student = os.get();
}else{
system.out.print("暂未找到用户信息");
}
升序降序
public static void main(String[] args) throws IOException {
//测试数据,请不要纠结数据的严谨性
List<Student> studentList = new ArrayList<>();
studentList.add(new Student("张三","2",22,"2022-12-02 2:11:00"));
studentList.add(new Student("李四","1",23,"2022-12-03 16:11:00"));
studentList.add(new Student("王五","4",24,"2022-12-01 21:11:00"));
studentList.add(new Student("赵六","3",25,"2022-12-02 22:11:00"));
//根据日期进行升序排序
//乱序
System.out.println("乱序"+studentList);
//根据日期进行升序排序
List<Student> studentsSortAsce = studentList.stream().sorted(Comparator.comparing(Student::getCreateTime)).collect(Collectors.toList());
//根据日期进行降序排序
List<Student> studentsSortDesc = studentList.stream().sorted(Comparator.comparing(Student::getCreateTime).reversed()).collect(Collectors.toList());
//升序后输出
System.out.println("升序"+studentsSortAsce);
//降序后输出
System.out.println("降序"+studentsSortDesc);
}
List转Map
public static void main( String[] args )
{
List<Student> list = new ArrayList<>(2);
list.add(new Student("aa", "27"));
list.add(new Student("bb", "26"));
//m和m1是等效的
Map<String, Student> m = list.stream().collect(Collectors.toMap(o -> o.getName(), Function.identity()));
Map<String, Student> m1 = list.stream().collect(Collectors.toMap(Student::getName, Function.identity()));
//多个参数拼接
//多个参数拼接 m2和m3等价
Map<String, Student> m2 = list.stream().collect(Collectors.toMap(o -> o.getAge() + "**" +o.getName(), Function.identity()));
Map<String, Student> m3 = list.stream().collect(Collectors.toMap(o -> o.getAge() + "**" +o.getName(), e -> e));
System.out.println(JSON.toJSONString(m));
//输出:{"bb":{"age":"26","name":"bb"},"aa":{"age":"27","name":"aa"}}
// 某个属性作为key 某个属性作为value
Map<String, String> m4 = list.stream().collect(Collectors.toMap(Student::getName, Student::getAge));
// 多个属性作为key 多个属性作为value
Map<String, String> m5 = list.stream().collect(Collectors.toMap(o -> o.getAge() + "**" +o.getName(), e -> e.getName()+"***"+e.getAge()));
}
1、Optional(T value),empty(),of(T value),ofNullable(T value)
这四个函数之间具有相关性,因此放在一组进行记忆。
先说明一下,Optional(T value),即构造函数,它是private权限的,不能由外部调用的。其余三个函数是public权限,供我们所调用。那么,Optional的本质,就是内部储存了一个真实的值,在构造的时候,就直接判断其值是否为空。好吧,这么说还是比较抽象。直接上Optional(T value)构造函数的源码,如下图所示
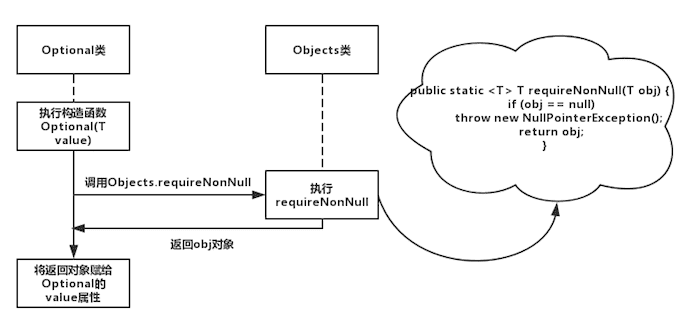
那么,of(T value)的源码如下
public static <T> Optional<T> of(T value) {
return new Optional<>(value);
}
也就是说of(T value)函数内部调用了构造函数。根据构造函数的源码我们可以得出两个结论:
-
通过
of(T value)函数所构造出的Optional对象,当Value值为空时,依然会报NullPointerException。 -
通过
of(T value)函数所构造出的Optional对象,当Value值不为空时,能正常构造Optional对象。
除此之外呢,Optional类内部还维护一个value为null的对象,大概就是长下面这样的
public final class Optional<T> {
//省略....
private static final Optional<?> EMPTY = new Optional<>();
private Optional() {
this.value = null;
}
//省略...
public static<T> Optional<T> empty() {
@SuppressWarnings("unchecked")
Optional<T> t = (Optional<T>) EMPTY;
return t;
}
}
那么,empty()的作用就是返回EMPTY对象。
好了铺垫了这么多,可以说ofNullable(T value)的作用了,上源码
public static <T> Optional<T> ofNullable(T value) {
return value == null ? empty() : of(value);
}
好吧,大家应该都看得懂什么意思了。相比较of(T value)的区别就是,当value值为null时,of(T value)会报NullPointerException异常;ofNullable(T value)不会throw Exception,ofNullable(T value)直接返回一个EMPTY对象。
那是不是意味着,我们在项目中只用ofNullable函数而不用of函数呢?
不是的,一个东西存在那么自然有存在的价值。当我们在运行过程中,不想隐藏NullPointerException。而是要立即报告,这种情况下就用Of函数。但是不得不承认,这样的场景真的很少。
2、orElse(T other),orElseGet(Supplier<? extends T> other)和orElseThrow(Supplier<? extends X> exceptionSupplier)
这三个函数放一组进行记忆,都是在构造函数传入的value值为null时,进行调用的。orElse和orElseGet的用法如下所示,相当于value值为null时,给予一个默认值:
@Test
public void test() {
User user = null;
user = Optional.ofNullable(user).orElse(createUser());
user = Optional.ofNullable(user).orElseGet(() -> createUser());
}
public User createUser(){
User user = new User();
user.setName("zhangsan");
return user;
}
这两个函数的区别:当user值不为null时,orElse函数依然会执行createUser()方法,而orElseGet函数并不会执行createUser()方法,大家可自行测试。
至于orElseThrow,就是value值为null时,直接抛一个异常出去,用法如下所示
User user = null;
Optional.ofNullable(user).orElseThrow(()->new Exception("用户不存在"));
3、map(Function<? super T, ? extends U> mapper)和flatMap(Function<? super T, Optional<U>> mapper)
这两个函数放在一组记忆,这两个函数做的是转换值的操作。
直接上源码
public final class Optional<T> {
//省略....
public<U> Optional<U> map(Function<? super T, ? extends U> mapper) {
Objects.requireNonNull(mapper);
if (!isPresent())
return empty();
else {
return Optional.ofNullable(mapper.apply(value));
}
}
//省略...
public<U> Optional<U> flatMap(Function<? super T, Optional<U>> mapper) {
Objects.requireNonNull(mapper);
if (!isPresent())
return empty();
else {
return Objects.requireNonNull(mapper.apply(value));
}
}
}
这两个函数,在函数体上没什么区别。唯一区别的就是入参,map函数所接受的入参类型为Function<? super T, ? extends U>,而flapMap的入参类型为Function<? super T, Optional<U>>。
在具体用法上,对于map而言:
如果User结构是下面这样的
public class User {
private String name;
public String getName() {
return name;
}
}
这时候取name的写法如下所示
String city = Optional.ofNullable(user).map(u-> u.getName()).get();
对于flatMap而言:
如果User结构是下面这样的
public class User {
private String name;
public Optional<String> getName() {
return Optional.ofNullable(name);
}
}
这时候取name的写法如下所示
String city = Optional.ofNullable(user).flatMap(u-> u.getName()).get();
4、isPresent()和ifPresent(Consumer<? super T> consumer)
这两个函数放在一起记忆,isPresent即判断value值是否为空,而ifPresent就是在value值不为空时,做一些操作。这两个函数的源码如下
public final class Optional<T> {
//省略....
public boolean isPresent() {
return value != null;
}
//省略...
public void ifPresent(Consumer<? super T> consumer) {
if (value != null)
consumer.accept(value);
}
}
需要额外说明的是,大家千万不要把
if (user != null){
// TODO: do something
}
给写成
User user = Optional.ofNullable(user);
if (Optional.isPresent()){
// TODO: do something
}
因为这样写,代码结构依然丑陋。博主会在后面给出正确写法
至于ifPresent(Consumer<? super T> consumer),用法也很简单,如下所示
Optional.ofNullable(user).ifPresent(u->{
// TODO: do something
});
5、filter(Predicate<? super T> predicate)
不多说,直接上源码
public final class Optional<T> {
//省略....
Objects.requireNonNull(predicate);
if (!isPresent())
return this;
else
return predicate.test(value) ? this : empty();
}
filter 方法接受一个 Predicate 来对 Optional 中包含的值进行过滤,如果包含的值满足条件,那么还是返回这个 Optional;否则返回 Optional.empty。
用法如下
Optional<User> user1 = Optional.ofNullable(user).filter(u -> u.getName().length()<6);
如上所示,如果user的name的长度是小于6的,则返回。如果是大于6的,则返回一个EMPTY对象。
实战使用
例一
在函数方法中
以前写法
public String getCity(User user) throws Exception{
if(user!=null){
if(user.getAddress()!=null){
Address address = user.getAddress();
if(address.getCity()!=null){
return address.getCity();
}
}
}
throw new Excpetion("取值错误");
}
JAVA8写法
public String getCity(User user) throws Exception{
return Optional.ofNullable(user)
.map(u-> u.getAddress())
.map(a->a.getCity())
.orElseThrow(()->new Exception("取指错误"));
}
例二
比如,在主程序中
以前写法
if(user!=null){
dosomething(user);
}
JAVA8写法
Optional.ofNullable(user)
.ifPresent(u->{
dosomething(u);
});
例三
以前写法
public User getUser(User user) throws Exception{
if(user!=null){
String name = user.getName();
if("zhangsan".equals(name)){
return user;
}
}else{
user = new User();
user.setName("zhangsan");
return user;
}
}
java8写法
public User getUser(User user) {
return Optional.ofNullable(user)
.filter(u->"zhangsan".equals(u.getName()))
.orElseGet(()-> {
User user1 = new User();
user1.setName("zhangsan");
return user1;
});
}
其他的例子,不一一列举了。不过采用这种链式编程,虽然代码优雅了。但是,逻辑性没那么明显,可读性有所降低,大家项目中看情况酌情使用。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)