
深度学习笔记(八)Focal Loss & QFocal Loss
论文:Focal Loss for Dense Object Detection
Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection
论文链接:https://arxiv.org/abs/1708.02002
http://arxiv.org/abs/2006.04388
一. 提出背景
object detection的算法主要可以分为两大类:two-stage detector和one-stage detector。前者是指类似Faster RCNN,RFCN这样需要region proposal的检测算法,这类算法可以达到很高的准确率,但是速度较慢。虽然可以通过减少proposal的数量或降低输入图像的分辨率等方式达到提速,但是速度并没有质的提升。后者是指类似YOLO,SSD这样不需要region proposal,直接回归的检测算法,这类算法速度很快,但是准确率不如前者。作者提出focal loss的出发点也是希望one-stage detector可以达到two-stage detector的准确率,同时不影响原有的速度。
作者认为one-stage detector的准确率不如two-stage detector的原因是:样本的类别不均衡导致的。我们知道在object detection领域,一张图像可能生成成千上万的candidate locations,但是其中只有很少一部分是包含object的,这就带来了类别不均衡。那么类别不均衡会带来什么后果呢?引用原文讲的两个后果:(1) training is inefficient as most locations are easy negatives that contribute no useful learning signal; (2) en masse, the easy negatives can overwhelm training and lead to degenerate models. 什么意思呢?负样本数量太大,占总的loss的大部分,而且多是容易分类的,因此使得模型的优化方向并不是我们所希望的那样。其实先前也有一些算法来处理类别不均衡的问题,比如OHEM(online hard example mining),OHEM的主要思想可以用原文的一句话概括:In OHEM each example is scored by its loss, non-maximum suppression (nms) is then applied, and a minibatch is constructed with the highest-loss examples。OHEM算法虽然增加了错分类样本的权重,但是OHEM算法忽略了容易分类的样本。
因此针对类别不均衡问题,作者提出一种新的损失函数:focal loss,这个损失函数是在标准交叉熵损失基础上修改得到的。这个函数可以通过减少易分类样本的权重,使得模型在训练时更专注于难分类的样本。为了证明focal loss的有效性,作者设计了一个dense detector:RetinaNet,并且在训练时采用focal loss训练。实验证明RetinaNet不仅可以达到one-stage detector的速度,也能有two-stage detector的准确率。
二. focal loss
1.Cross Entropy
对于二分类来说:标准的交叉熵损失:
$CrossEntropy= -\frac{1}{n} \sum_{i=1}^{n} [y_i log(p_i) + (1-y_i) log(1 - log(p_i))]$
或
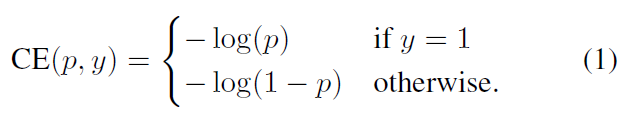
这里$y$是GT=1/0,$p$是预测输出为1的概率。
我们知道,当$y=1$时:

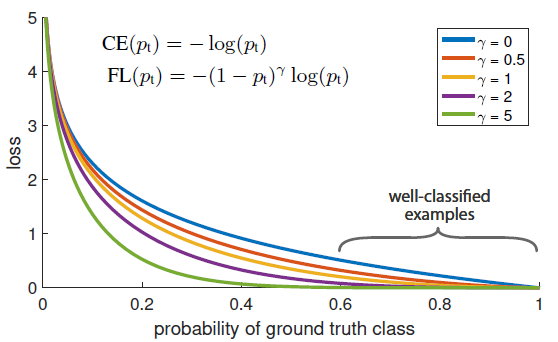
这时候,$L$与预测输出的关系如下左图所示:很显然:对于正样本的预测,预测输出越接近真实样本标签$y=1$, 损失函数$L$越小;预测输出越接近0,$L$越大。
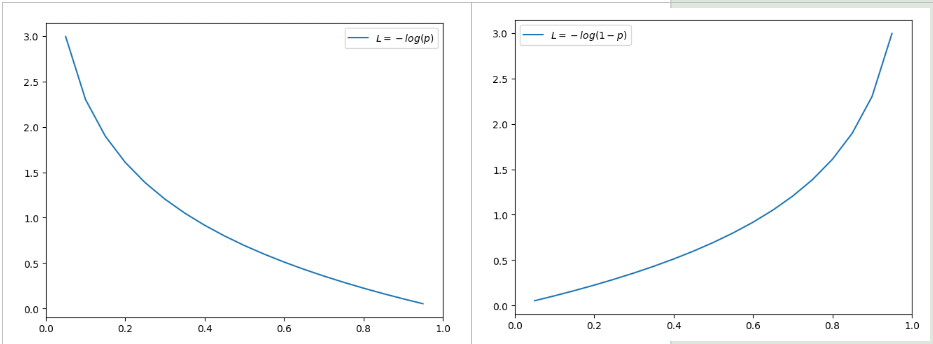
而当$y=0$时:
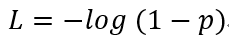
这时候,$L$与预测输出的关系如上右图:同样,预测输出越接近真实样本标签0($p$值越小),损失函数$L$越小;预测输出越接近1,$L$越大。函数的变化趋势也完全符合实际需要的情况。
无论真实样本标签 $y$ 是 0 还是 1,$L$ 都表征了预测输出与 $y$ 的差距。从图形中我们可以发现:预测输出与 $y$ 差得越多,$L$ 的值越大,也就是说对当前模型的 “ 惩罚 ” 越大,而且是非线性增大,是一种类似指数增长的级别。这是由 log 函数本身的特性所决定的。这样的好处是模型会倾向于让预测输出更接近真实样本标签$ y$。
为了方便,用pt代替p,如下公式2:
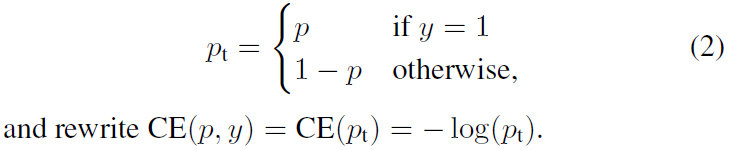
接下来介绍一个最基本的对交叉熵的改进,也将作为本文实验的baseline。
2.Balanced Cross Entropy
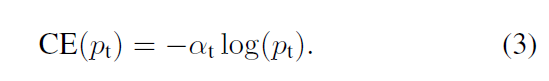
什么意思呢?增加了一个系数at,跟pt的定义类似,当label=1的时候,at=a;当label=-1的时候,at=1-a,a的范围也是0到1。因此可以通过设定a的值(一般而言假如1这个类的样本数比-1这个类的样本数多很多,那么a会取0到0.5来增加-1这个类的样本的权重)来控制正负样本对总的loss的共享权重。这里当a=0.5时就和标准交叉熵一样了(系数是个常数)。
显然前面的公式3虽然可以控制正负样本的权重,但是没法控制容易分类和难分类样本的权重。
3.Focal Loss

这里的$\gamma$ 称作focusing parameter,$\gamma>=0$。
$(1- p_t)^\gamma$ 称为调制系数(modulating factor)
这里介绍下focal loss的两个重要性质:1、当一个样本被分错的时候,pt是很小的(请结合公式2,比如当y=1时,p<0.5才是错分类,此时pt就比较小,反之当y=-1时,p>0.5是错分了),因此调制系数就趋于1,也就是说相比原来的loss是没有什么大的改变的。当pt趋于1的时候(此时分类正确而且是易分类样本),调制系数趋于0,也就是对于总的loss的贡献很小。2、当 $γ=0$ 的时候,focal loss就是传统的交叉熵损失,当 $γ$ 增加的时候,调制系数也会增加。
focal loss的两个性质算是核心,其实就是用一个合适的函数去度量难分类和易分类样本对总的损失的贡献。
作者在实验中采用的是公式5的focal loss(结合了公式3和公式4,这样既能调整正负样本的权重,又能控制难易分类样本的权重):
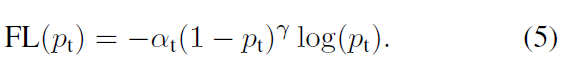
PS: 实际我在使用中,选择的是以下方式
FL(p_t) =(1 - p_t) ^ 1.0 * log(p_t) if p_t 来自正样本 FL(p_t) =(1 - p_t) ^ gamma * log(p_t) if p_t 来自负样本
即给易分的负样本更大的惩罚。
三. 实验
在实验中a的选择范围也很广,一般而言当γ增加的时候,a需要减小一点(实验中γ=2,a=0.25的效果最好)
实验结果:
Table1是关于RetinaNet和Focal Loss的一些实验结果。(a)是在交叉熵的基础上加上参数a,a=0.5就表示传统的交叉熵,可以看出当a=0.75的时候效果最好,AP值提升了0.9。(b)是对比不同的参数γ和a的实验结果,可以看出随着γ的增加,AP提升比较明显。(d)通过和OHEM的对比可以看出最好的Focal Loss比最好的OHEM提高了3.2AP。这里OHEM1:3表示在通过OHEM得到的minibatch上强制positive和negative样本的比例为1:3,通过对比可以看出这种强制的操作并没有提升AP。(e)加入了运算时间的对比,可以和前面的Figure2结合起来看,速度方面也有优势!注意这里RetinaNet-101-800的AP是37.8,当把训练时间扩大1.5倍同时采用scale jitter,AP可以提高到39.1,这就是全文和table2中的最高的39.1AP的由来。

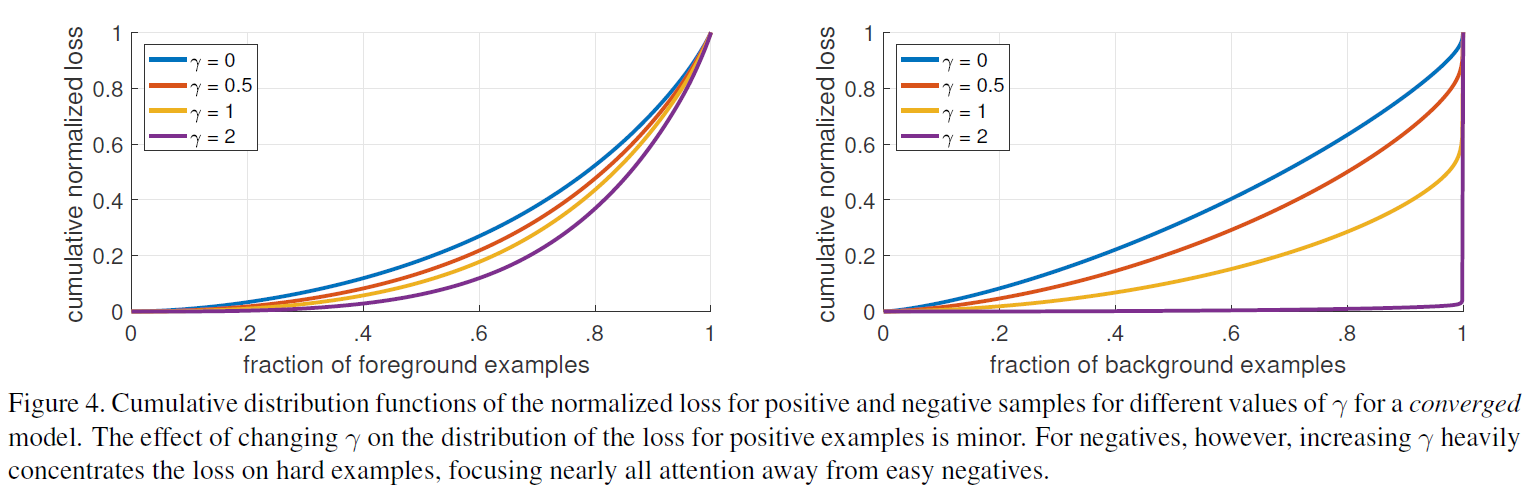
Figure4是对比forground和background样本在不同γ情况下的累积误差。纵坐标是归一化后的损失,横坐标是总的foreground或background样本数的百分比。可以看出γ的变化对正(forground)样本的累积误差的影响并不大,但是对于负(background)样本的累积误差的影响还是很大的(γ=2时,将近99%的background样本的损失都非常小)。
三. 总结
原文的这段话概括得很好:In this work, we identify class imbalance as the primary obstacle preventing one-stage object detectors from surpassing top-performing, two-stage methods, such as Faster R-CNN variants. To address this, we propose the focal loss which applies a modulating term to the cross entropy loss in order to focus learning on hard examples and down-weight the numerous easy negatives.
四. QFocal Loss
从上面的公式中我们可以看出,Focal Loss 只支持 0/1 这样的离散类别 label。但对于 smooth 的 label(0~1)是无能为力的,因此就引申出了 Quality Focal Loss (QFL):
$QFL(\sigma) = - \alpha_t * |y - \sigma|^{\beta} * [(1 - y) log(1 - \sigma) + y log(\sigma)] $
其中,$y$ 是 smooth 后的 label(0~1), $\sigma$ 是预测结果。拆分一下:
$\alpha_t = y * \alpha + (1 - y ) * (1 - \alpha) \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ // 平衡正负样本 $
$|y - \sigma|^{\beta} \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ // 平衡难易样本 $
$CE(y, \sigma) = - [(1 - y) log(1 - \sigma) + y log(\sigma)] \ // Cross\ Entropy\ Loss $

 浙公网安备 33010602011771号
浙公网安备 33010602011771号