
深度学习笔记(二十一)Anchor Free
1. Anchor Free
Anchor 的缺点:
- 正负样本不均衡:我们通常在特征图所有点上均匀采样 Anchor,而在大部分地方都是没有物体的背景区域,导致简单负样本数量众多,这部分样本对于我们的检测器没有任何作用。
-
超参难调:Anchor 需要数量、大小、宽高等多个超参数,这些超参数对检测的召回率和速度等指标影响极大。此外,人的先验知识也很难应付数据的长尾问题,这显然不是我们乐意见到的。
-
匹配耗时严重(训练阶段):为了确定每个 Anchor 是正样本还是负样本,通常要将每个 Anchor 与所有的标签进行 IoU 的计算,这会占据大量的内存资源与计算时间。
这里将大致过一遍几种主流的 Anchor Free 方法:
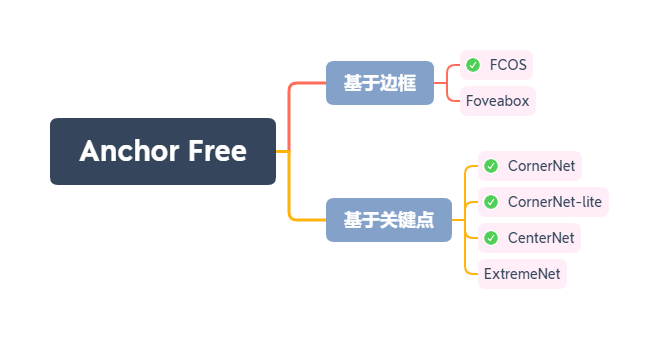
Figure 1
- 直接预测边框:根据网络特征直接预测物体出现的边框,即上、下、左、右4个值。典型算法如 YOLOV1、利用分割思想解决检测的 FCOS(Fully Convolutional One-Stage),以及改善了边框回归方式的 Foveabox 算法。
- 关键点的思想:使用边框的角点或者中心点进行物体检测,这类算法通常是受人体姿态的关键点估计启发,典型有 CornerNet、ExtremeNet 及 CenterNet 等。
从目前的论文来看,Anchor-Free 的算法已经达到与基于 Anchor 的检测器基本上旗鼓相当的程度了
2. CornerNet
code: CornerNet-Lite
paper: CornerNet: Detecting Objects as Paired Keypoints

Figure 2
CenterNet 的思想是,首先使用卷积网络检测整个图像中的关键点的热度图(每一类两个热度图,对应左上角和右下角,比如有10类,就是20个热度图。其中对于同一类的多个检测框角点都反映在同一张热度图里,比如一张图中有三只狗,那么对应狗这一类的左上角点热度图应该有三个位置反应强烈),然后对属于同一个目标的关键点进行 group(同属一个目标的两个角点应该有相似的特征 embedding vector),形成检测框。这个Embedding 的方法是借鉴了一个 NIPS17 中一个多人姿态估计的工作。考虑到下采样取整带来的精度损失,还要预测 Offsets 来 refine 角点的位置。检测的基本流程如 Fig. 2 所示:
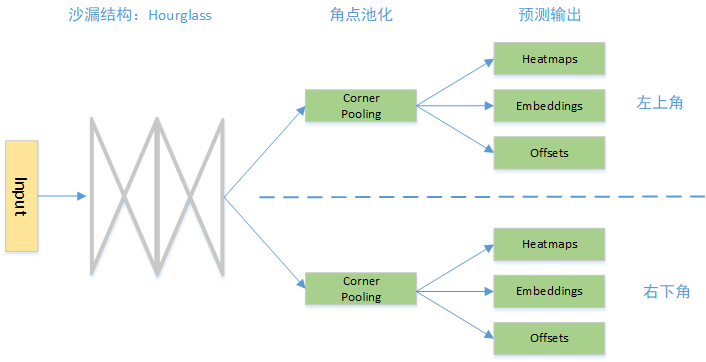
Figure 3
2.1 Network
CornerNet 的主要结构主要由以下 3 部分组成:
- 沙漏结构 Hourglass:特征提取的 Backbone,能够为后续的网络预测提供很好的角点特征图。
- 角点池化:作为一个特征的池化方式,角点池化可以将物体的信息整合到左上角点或者右下角点。
- 预测输出:传统的物体检测会预测边框的类别与位置偏移,而 CornerNet 则与之完全不同,其预测了角点出现的位置 Heatmaps、角点的配对 Embeddings 及角点位置的偏移 Offsets。
如下图所示,网络的基础结构单元是 nxnCBR、nxnCB、3x3Res(stride=2/stride=1, skip=3x3CB/1x1CB/直接相连)。网络首先经过 Pre Module,下采样两次。然后进入两个连续的 HG Module,训练时两个 HG Module 都预测输出(虚线框部分)参与 Loss 计算,测试时只第二个人 HG Module 预测输出(这和 GoogleNet 类似)。虚线框中包含两种模块:Corner Pool 和 预测模块。两个 Corner Pool 分别提取左上角点和右下角点的信息。
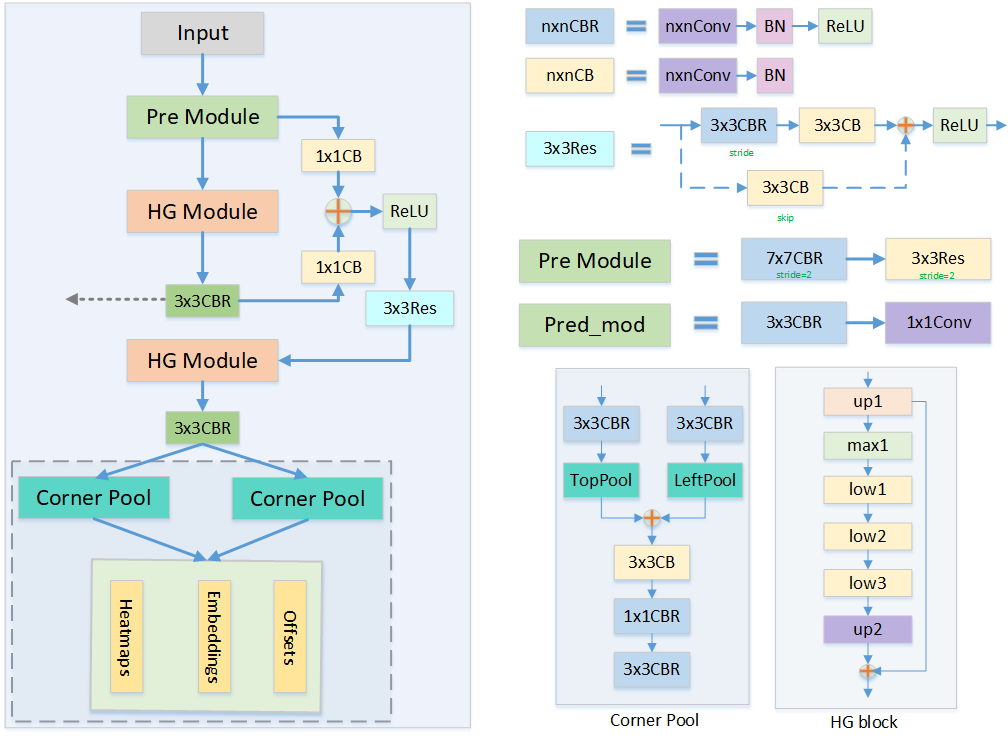
Figure 4
core/models/CornerNet.py
core/models/py_utils/modules.py
2.1.1 沙漏结构:Hourglass
Figure 5
为了提取图像中的关键点,CornerNet 使用了沙漏结构 Hourglass 作为网络特征提取的基础模块,其结构如上图所示。顾名思义,Hourglass 的整体形状类似于沙漏,两边大,中间小。Hourglass 结构是从
人体姿态估计领域中借鉴而来,通过多个 Hourglass 模块的串联,可以十分有效地提取人体姿态的关键点。
上图中,左半部分表示传统的卷积与池化过程,语义信息在增加,分辨率在减小。右半部分表示上采样与融合过程,深层的特征通过上采样操作与浅层的特征进行融合,在增大分辨率的同时,保留了原始的细节信息。
代码实现采用嵌套结构,比较难懂,这里绘制了一张示意图,方便对比代码理解:
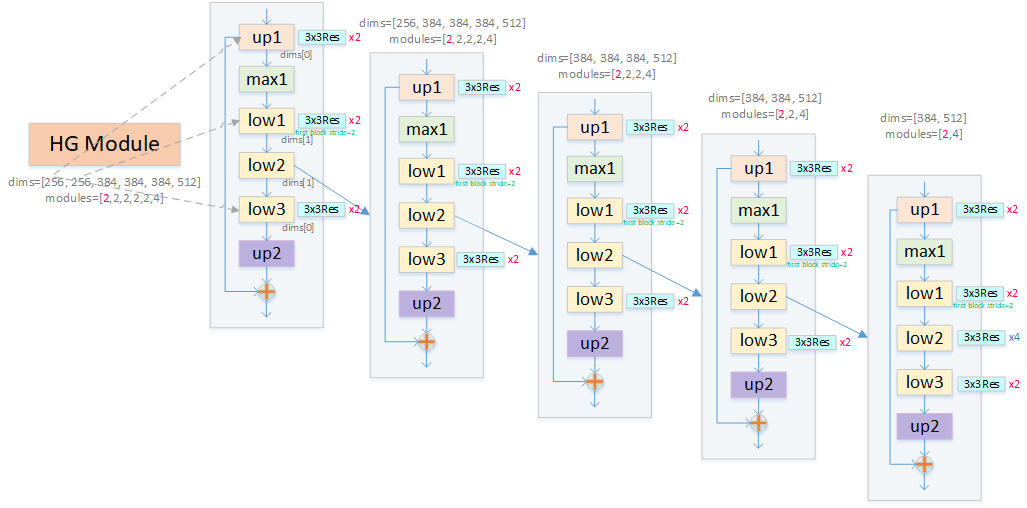
Figure 6
这里一个 HG Module 可以理解为 5 个嵌套的 HG Block 构成,超参数 dims 控制每个子模块输出 channel 数,modules 则控制每个子模块重复次数(图上 max1 子模块为空)。up2 子模块采用 nearest 插值缩放的方式上采样。
2.1.2 角点池化:Corner Pooling
在传统卷积网络中,通常使用池化层来进行特征融合,扩大感受野,也可以起到缩小特征图尺寸的作用。以3×3的最大池化层为例,通常是以当前位置的点为中心点,融合周围共9个点的信息,取最大值输出。
然而,CornerNet 的思想是利用左上与右下两个关键点进行物体检测,对于一个物体的左上点,其右下区域包含了物体的特征信息,同样对于物体的右下点,其左上区域包含了物体的特征信息,这时角点的周围只有四分之一的区域包含了物体信息,其他区域都是背景,因此传统的池化方法就显然不适用了。
为了达到想要的池化效果,CornerNet 提出了 Corner Pooling 的方法,左上点的池化区域是其右侧与下方的特征点,右下点的池化区域是其左侧与上方的特征点,如下图所示为左上点的 Corner Pooling 过程。
在图中,假设当前点的坐标为 (x,y),特征图宽为 W,高为 H,则 Corner Pooling 的计算过程如下:
- 计算该点到其下方所有点的最大值,即 (x,y) 到 (x,H) 所有点的最大值。
- 计算该点到其最右侧所有点的最大值,即 (x,y) 到 (W,y) 所有点的最大值。
- 将两个最大值相加,作为 Corner Pooling 的输出。
工程实现时,可以分别从下到上、从右到左计算最大值,这样效率会更高。

Figure 7
Figure 3 右下角示例了提取左上角点的 Corner Pool Module 结构。
2.1.3 预测输出:Output Prediction
最后一个重要部分就是 CornerNet 的预测输出,以及损失的计算方式。
如图开始那张图所示,左上角与右下角两个 Corner Pooling 层之后,分别接了 3 个预测量,这 3 个预测量的意义分别如下:
- Heatmaps:角点热图,预测特征图中可能出现的角点,大小为 C×W×H,C 代表类别数,以左上角点的分支为例,坐标为 (c,x,y) 的预测点代表了在特征图上坐标为 (x,y) 的点是第 c 个类别物体的左上角点的分数。
- Embeddings:Heatmaps 中的预测角点都是独立的,而一个物体需要一对角点,因此 Embeddings 分支负责将左上角点的分支与右下角点的分支进行匹配,找到属于同一个物体的角点,完成检测任务,其大小为 1×W×H。
- Offsets:Offsets 代表在取整计算时丢失的精度(由于使用了降采样,可能造成关键点的降采样等效点位置离散化误差,也就是位置精度损失),目的是进一步提升检测的精度。这种取整的精度丢失对于小物体检测影响很大,因此 CornerNet 引入了偏差的预测来修正检测框的位置,其大小为2×W×H。
2.2 Preprocess
对于角点的检测,CornerNet 对左上角和右下角分别准备了一个热度图,热度图通道数等同于类别数,尺度是输入尺度的四分之一。后续介绍以一个热度图为例,另一个是同样的操作。对于每个标注的 GT 角点,只对应到热度图的一个坐标位置,其余坐标位置应该作为负样本。然而在训练时,CornerNet 并不对所有负样本位置做同样的惩罚,而是以正样本为中心,使用一个高斯函数把正样本的分值分散给周围的位置,也就是越接近正样本,其作为负样本的惩罚越小。这是因为就算没有准确的预测到 GT 左上角和右下角,而是在其周围分别预测到两个角点,也是可以组成一个相对不错的检测框的(由于一些标注误差,没准还是更优的检测框)。参考 Fig. 8 具体示例,如果两个点的辐射区域重合了,在每个位置取数值大的那个类。

Figure 8
core/sample/cornernet.py
2.2 LOSS
CornerNet 在损失计算时借鉴了 Focal Loss 的思想,对于不同的负样本给予了不同的权重,总体的损失公式如式(10-1)所示。
\begin{equation}
\label{loss}
L = L_{det} + \alpha L_{pull} + \beta L_{push} + \gamma L_{off}
\end{equation}
- $L_{det}$: 角点检测的损失,借鉴了 Focal Loss 权重惩罚的思想。CornerNet 为了减小负样本的数量,将以标签角点为中心,半径为 r 区域内的点都视为正样本,因为这些点组成的边框与标签会有很大的 IoU,仍有可能是我们想要的正样本。
- $L_{pull}$: Embeddings 中,对于属于同一物体的两个角点的惩罚。具体实现时,提取 Embeddings 中属于同一个物体的两个角点,然后求其均值,并希望两个角点的值与均值的差尽可能地小。
- $L_{push}$: Embeddings中,对不属于同一物体的两个角点的惩罚。具体实现时,利用$L_{push}$中配对的角点的平均值,期望没有配对的角点与该平均值的差值尽可能地大(loss 设计中以保证距离大于1),可以有效分离开无效的角点。
- $L_{off}$: 位置偏差的回归损失,与 SSD 相似的是,CornerNet使用了 smoothL1 损失函数来优化这部分位置偏差。
core/models/py_utils/losses.py
2.3 Postprocess
这里用最大池化取代了 NMS 操作:
- tl_heat 和 br_heat 经过 sigmoid 平滑处理
- heatmaps 做了一个类 NMS 操作,即用 3x3 的 maxpool(stride=1, pad=1) 寻找亮点,heatmaps 中只保留亮点位置处的值(其他置0)
- 分别选择 top100 个 heatmaps 亮点作为目标顶点候选点,这样的话存在 100x100 种组合
- 根据候选点位置解码左上角和右下角顶点位置
- 匹配两类顶点,类别不同的排除,Embedding 差距大于 ae_threshold(0.5, 训练时要保证大于1) 的排除,左上角和右下角位置不符合空间位置关系的排除
- 最后只保留 top1000 对顶点组合作为检测目标
CornerNet在推理时也不会resize输入图像,而是直接使用原始尺寸输入。并且会使用原始图像和翻转的图像同时预测,并融合预测结果来提高准确率。
core/models/py_utils/utils.py
3. CenterNet
code: CenterNet
paper: Objects as Points

Figure 9
CenterNet 算是 CornerNet 的拓展版,其核心思想是:
- 将 GT 通过高斯核将目标以 GT 中心点为中心辐射到整个图像平面(目标中心点处值为1,距离中心点位置越远值越小,多个目标中心点辐射有重叠的部分取数值较大的那个)形成热力图形式的 GT (算是一种 label smooth);
- 然后在输出 feature map 上分别预测 C个类别+2维的宽高尺寸+2维中心点偏移 三个 modality,每个 modality 在 feature map 的基础上分别经过一个 3x3 卷积 + ReLU + 1x1 卷积的组合来预测;
- 推理时,对于每一个类别的结果(一片热力图),首先在输出热度图上找到尖峰点,即热度值大于等于其8个相邻邻居的点。保持100个热度图取值最大的尖峰点,并用其取值直接表示置信度得分。对每个点的坐标,加上预测局部偏移量,以及以其为中心的尺寸扩展,得到矩形框四个角点。
- 作者接着又双叒叕提到了 CenterNet 后续不需要基于 IoU 的NMS或其他后处理。作者认为尖峰点的提取已经足以作为非极大抑制的替代品了,直接做一个非常高效的 3x3 最大池化就相当于 NMS 了 (也就是说如果两个尖峰点在热度图上距离两个像素以上就认为是两个物体了)。
3.1 Network
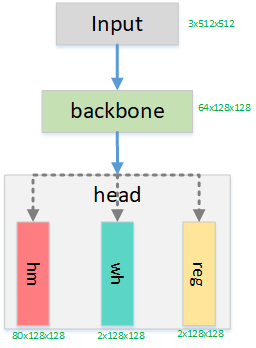
Figure 10
- 网络结构上,backbone 除了 Hourglass、ResNet 此类外作者还引入了 DLA 模块,即使用 deformable 卷积来跳跃连接低层和输出层。
- Head 部分接 3 组 3x3 卷积,分别预测分类热力图、目标框的宽高以及回归框偏移(由于下采样取整操作等会导致中心点偏移)三个量。
src/lib/models/model.py
3.2 Preprocess
为了形象描述,这里用自己的数据集(12 个类别)展示后续过程,训练输入尺度固定为 320x480
1. 图像先经过变换到训练尺度
2. 根据 GT 分布得到以下几个量:
- hm: 12x80x120 维度,输出尺度上,对应 12 个类别的 GT 热力图,每个人热力点中心(值为1)为目标在输出尺度上的中心点。以下图某一类别的 GT 分布为例,第二行描述的是最后一个目标:

- wh: 输出尺度上,目标的实际宽和高
- reg: 输出尺度上,因为下采样取整导致的精回归误差(回归目标=实际中心坐标 - 取整后中心点坐标)
src/lib/datasets/dataset_factory.py
src/lib/datasets/dataset/coco.py
src/lib/datasets/sample/ctdet.py
3.3 Loss
- 分类采用 FocalLoss, 回归均采用 RegL1Loss。使用 FocalLoss 时,hm 需要经过 sigmoid 函数平滑处理
- 这里的 FocalLoss 不同于原版,我们知道 FocalLoss 的定义形式是:
\begin{equation}
\label{FocalLoss}
FL(p_t) = -\alpha_t (1-p_t)^{\gamma} log(p_t)
\end{equation}
这里 $\gamma=2$, $\alpha_t = (1-p_t)^4$,以上面的点为例,负样本的 $\alpha$ 可视化权重为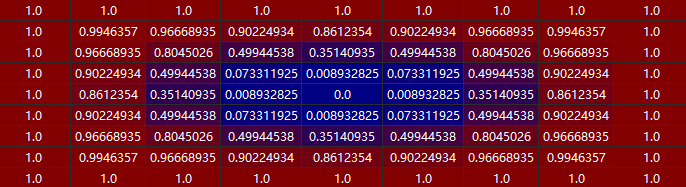
- 作者实验中,分类、高宽回归和中心点回归三个部分的 loss 比例分别是 1:0.1:1
src/lib/trains/base_trainer.py
src/lib/trains/ctdet.py
src/lib/models/losses.py
3.4 Postprocess
- hm 经过 sigmoid 平滑处理
- hm 做了一个类 NMS 操作,即用 3x3 的 maxpool(stride=1, pad=1) 寻找亮点,hm 中只保留亮点位置处的值(其他置0)
- 选择 top100 个 hm 亮点作为目标候选点
- 根据候选点位置解码出目标包围框
src/lib/detectors/ctdet.py
src/lib/models/decode.py
4. FCOS
code: FCOS
paper: FCOS: Fully Convolutional One-Stage Object Detection

Figure 11
4.1 网络结构
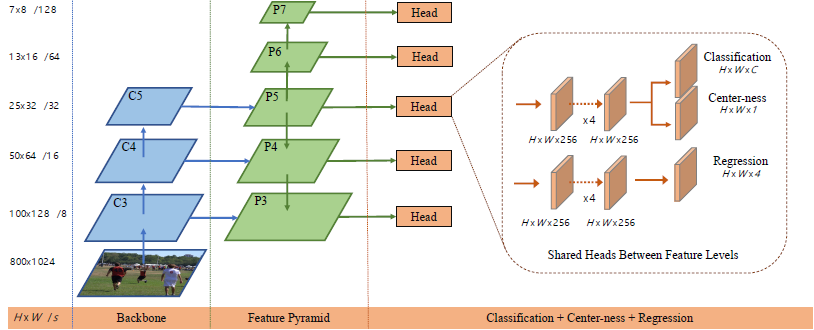
Figure 11
1. 网络结构上,如上图所示:FCOS 共 5 个尺度输出 {$P_3, P_4, P_5, P_6, P_7$},其中 $P_3, P_4, P_5$ 由 backbone 中的 feature map $C_3, C_4, C_5$ 经过一个1x1卷积横向连接得到。
2. 同 FPN、RetinaNet 一样,模型中共享 heads 部分的参数,这样不仅可以使检测器更参数高效,而且也可以提升检测性能。同时这里还采用了 GroupNorm 层代替了 BatchNorm。
3. 具体的,每个 feature map 先分别进入 cls_tower 和 bbox_tower 两个模块分离类别特征和位置特征。每个尺度分离出来的类别特征经过一个 3x3 卷积预测 classification score,区别于 yolov3 有一个区分前景背景的 score,这里换成了一个 3x3 卷积预测 score,目的都是为了抑制低质量的预测框,但分类目标的物理意义不同(yolov3 是全局做分类(有大量负样本),centerness 是同回归一样只在正样本集合里做分类)。在分类分支上加上一个 $1D$ 的分类分支,分类目标是个 smooth 形式:
\begin{equation}
\label{centerness}
centerness^* = \sqrt{\frac{min(l^*, r^*)}{max(l^*, r^*)} \times \frac{min(t^*, b^*)}{max(t^*, b^*)}}
\end{equation}
采用 BCE Loss, 该 loss 加到 3.4 节的 Eq.3 上。训练时 centerness target 作为权重项给予回归 loss,预测时,最终的分类 score 由分类分支的分数和 "centerness" 分支的分数相乘获得(训练时没有该操作)。目的是为了降低那些远离目标中心的检测框的分数,随后这些低质量检测框可以通过 NMS 去除。当然中心化操作也可以通过限定 GT 中心的附近的点/Anchor 作为正样本来达到。
4. 正常情况下分离出的位置特征则只需要经过一个 3x3 卷积来预测中心点到四边的距离。但考虑到不同尺度的回归范围不同,模型中考虑利用 $exp(s_i*x)$ 操作来标准化,对回归分支上$(0,+\infty)$的所有实数预测做映射,其中 $s_i$ 是学习出来的,这对提升模型性能很重要。
fcos_core/modeling/detector/generalized_rcnn.py
fcos_core/modeling/rpn/fcos/loss.py
4.2 Preprocess
1. feature map 上,所有落在 bbox 内的 (x,y) 都将被视为正样本,回归目标是该位置到 bbox 的四个边框(映射到 feature map 上)的距离, 这就相当于是一个框级别的实例分割了:
\begin{equation}
\label{regression target}
\begin{split}
& l^* = x - x_0^{(i)}, \ t^* = y - y_0^{(i)} , \\
& r^* = x_1^{(i)} - x, \ b^* = y_1^{(i)} - y . \\
\end{split}
\end{equation}
2. 对于落在重叠框里的点 (x,y) 则简单选择面积最小的那个作为回归目标/分类目标。
3. 区别于 Anchor based 检测器中,通过在不同尺度 feature map 中设置不同大小的 Anchor boxes 来完成多尺度,这里直接限制 bounding box regression。具体的,每个尺度分别限定它们的预测范围为 $P_3$ [0, 64], $P_4$ [64, 128], $P_5$ [128, 256], $P_6$ [256, 512], $P_7$ [512,$+\infty$]。因为不同尺寸的目标被分配到不同特征层上,而大部分重叠都发生在尺寸差异比较大的目标之间,所以 multi-level prediction 可以缓解上文提到的二义性问题,提高 FCN based 检测器的性能,使之接近 Anchor based 检测器。特别的,如果还存在对应多个 GT 的实例,就简单取面积最小的那个 GT 为目标就好了。 ps. 这种限制理论上有意义,但实际使用效果如何待验证。
fcos_core/data/datasets/coco.py
fcos_core/data/build.py
fcos_core/modeling/rpn/fcos/loss.py
4.3 Loss
1. 用训练 $C$ 个 binary classifiers 代替训练一个 multi-class classifier。
2. $L_{cls}$ 是有 focal loss 加成的,$L_{reg}$ 是 IoU loss。$N_{pos}$ 代表正样本的数量,$\lambda$ 是一个权重因子(论文中设为1)。$\textbf{1}_{c_i^*>0}$ 是一个指标函数,当 $c_i^*>0$ 值为1,否则为0:
\begin{equation}
\label{loss function}
L(\{p_{x,y}\},\{t_{x,y}\}) = \frac{1}{N_{pos}}\sum_{x,y}{L_{cls}(p_{x,y}, x_{x,y}^*)} + \frac{\lambda}{N_{pos}}\sum_{x,y}{\textbf{1}_{\{c_i^*>0\}} L_{reg}(t_{x,y}, t_{x,y}^*)}
\end{equation}
当然,还有一个 3.1 节描述的 centerness 分类loss,代码中发现,回归 Loss 不是用 $N_{pos}$ 作归一化的,而是用 $\sum{centerness}$。
fcos_core/modeling/rpn/fcos/loss.py
4.4 Postprocess
- 先用 pre_nms_thresh 阈值过滤掉低 cls_score 框
- 将 classification scores 和 centerness scores 相乘来更新 classification scores
- 按照 classification scores 排序获得前 per_pre_nms_top_n = min(pre_nms_top_n, sum(cls_remain)) 个预测框
- 将 box_regression 预测结果和中心点位置 meshgrid 结合,将坐标映射到原图,获得 (xmin, ymin, xmax, ymax) 回归框
- 过滤掉特别小的框(min_size)
- 最后,由于是多尺度预测,因此 NMS 还是少不了的
fcos_core/modeling/rpn/fcos/fcos.py
fcos_core/modeling/rpn/fcos/inference.py
5. Summary
1. 从我个人的理解来看,这三篇论文其实都是从分割角度来解决目标检测这一问题的。CornerNet 和 CenterNet 分别在两个顶点和一个中心点处设计一个高斯热力图 GT,两个算法通过 CxHxW 维度的 heatmap 完成 C 个类别的语义分割, 而由于 CornerNet 用两个顶点描述一个框,因此需要通过 Embedding 来完成两个顶点的配对。区别于前两个算法用点扩散成的热力图作为 GT,FCOS 则是将最后的 feature map 里所有落在 GT 内的点都作为正样本。
2. CornerNet 通过两个顶点预测定位目标位置,CenterNet 则通过中心点和宽高预测来定位目标位置,但考虑到下采样取整此类的操作,理论上就是 stride(4)-1 个像素误差存在,因此 CornerNet 和 CenterNet 网络还预测了一个 offsets(2xHxW)。区别于前两个算法 FCOS 则是通过预测点(不一定是中心点)到框四个边界的距离来完成目标定位。
3. CornerNet 引入的 Embedding 预测如果不准那会带来额外的误差问题。
4. CornerNet 和 CenterNet 都用最大池化操作来代替 NMS 操作,效率更高
5. FCOS 用到了多尺度,同时通过直接限制 bounding box regression 将不同尺寸的目标被分配到不同特征层上来解决重叠目标检测的问题(作者认为大部分重叠都发生在尺寸差异比较大的目标之间)
6. FCOS 这里引入了 Center-ness 分类器(smooth 形式),预测时加权到类别分数上(类似于 YOLOV3 这种有一个预测是前景还是背景的分类器),训练时则加权到回归器上,目的是为了去掉远离目标中心的重叠框。
Reference
1. 深度学习之 PyTorch 物体检测实战

