
深度学习笔记(二十四)Learning to Calibrate Straight Lines for Fisheye Image Rectification
Abstract
本文提出一种新颖的基于深度学习的方法来同时完成鱼眼镜头的内参标定和图像的畸变矫正。假定鱼眼图上的畸变线经过矫正后应该是直线,我们提出一种新颖的深度神经网络,在鱼眼镜头标定和图像矫正过程中施加显式几何约束 。同时,考虑到鱼眼图像畸变分布的非线性特性,提出的网络利用多尺度感知来平衡整幅图像的矫正效果。为了训练和评价所提出的方法,我们标注了一个大型数据集,包含了对应的畸变参数和扭曲曲线。相比于其它的 state-of-the-art 方法,我们的模型在大量合成和真实鱼眼图像上取得了最好的校正质量和最准确的畸变参数估计。
1. Introduction
鱼眼相机由于拥有大 FOV(fiekd of view) 而被广泛运用在一些计算机视觉任务中。然而鱼眼相机拍摄出来的图像往往同时伴随着严重的几何畸变。当对鱼眼镜头视觉系统做几何处理时,往往第一步是标定内参来矫正畸变图像。
1.1 Motivation and Objective
早期有关鱼眼相机标定的工作是作为一个优化问题,通过拟合 2D/3D 不同视角下之下的关系来进行的。但是这些方法通常需要预先准备好矫正模式和额外的手动操作,甚至经常涉及大量的离线评估,这严重限制了他们在实际场景中的应用。为了克服这些限制,并朝着自动自校准的解决方案迈步,后来的一些研究提出从单一图像中检测出的几何物体(如圆锥曲线和线条)并进一步利用它们在 3D 世界中的对应关系。这类方法在鱼眼相机标定中只有当特定的几何对象能被准备地检测出来时才有良好的性能。然而,值得注意的是鱼眼图像中涉及的几何对象检测问题本身就是计算机视觉中的另一个具有挑战性的问题。最近,一种利用 CNNs 的替代方法被提出(啥任务都可以用 DL 硬 train 一发![]() )。为了避免检测几何目标的难度,这类方法试图利用 CNNs 来学习出更具有表征能力的视觉特征来矫正畸变的图像。尽管上述方法在鱼眼图矫正上被曝出了 state-of-the-art performances,同时还避免掉了检测几何目标的风险,但在鱼眼相机标定任务中并没有利用 CNNs 将几何特征进行充分的利用。
)。为了避免检测几何目标的难度,这类方法试图利用 CNNs 来学习出更具有表征能力的视觉特征来矫正畸变的图像。尽管上述方法在鱼眼图矫正上被曝出了 state-of-the-art performances,同时还避免掉了检测几何目标的风险,但在鱼眼相机标定任务中并没有利用 CNNs 将几何特征进行充分的利用。
刨除掉在鱼眼图像中检测几何目标的难度,我们可以观察到,明确的场景几何图像对于图像的畸变矫正仍是一强大的约束。而如何在针孔相机模型下应用基本几何特征仍是一个非常有趣的问题,即从空间到相机的直线投影应该是一条直线,这一特性可以用于鱼眼图像标定网络。如 Fig.1 所示,针对利用 CNNs 同时解决鱼眼相机标定和图像矫正的难题,我们提出一种 novel networks 进一步利用这种显式场景几何特性。

Figure 1. 学习矫正鱼眼图的直线。第一行:原始的鱼眼图以及被检测到的畸变线,校准后应该是直线的;第二行:矫正后的直线;第三行:矫正后的图像。
1.2 Overview of Our Method
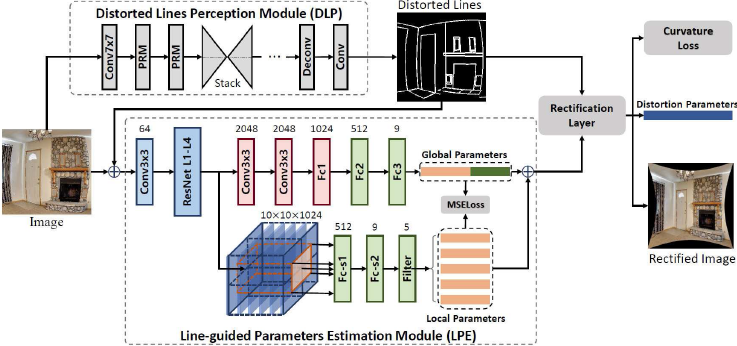
Figure 2. 整个系统的架构. 整个网络结构包括三个部分:line-guided 参数估计模块(LPE), distorted line 分割感知模块(DLP), 以及矫正层。其中 DLP 模块可以检测出在矫正图上应该是直线的 curve map, 然后将 DLP 的分割输出和鱼眼 RGB 图一起送给 LPE 来估计全局和局部鱼眼畸变参数。估计出来的畸变参数被用于矫正层来实施曲率约束。
上述挑战引发了两个问题:1)如何设计强大的 CNNs 来明确描述鱼眼图像中的场景几何特征。2)如何有效和高效的利用几何信息来训练一个深度网络。为了解决这个问题,我们提出首先训练一个神经网络来检测 distorted lines,该线条经过鱼眼图矫正后应该是一条直线;然后将这些 distorted lines 喂给另外一个深度子网络来预测鱼眼相机的畸变参数。如 Fig.2 所示,我们的网络包含三个部分:
- Module for detecting distorted straight lines: 这一模块用于在给定的鱼眼图中提取 distorted lines,这在矫正后的图像中应该是直的,参见 Fig.1 中第一行的示例。
- Module for recovering the distortion parameters: 输入检测到的 distorted lines 和 原始鱼眼图,这一模块试图预测出鱼眼镜头的畸变参数。特别的,multi-scale perceptron 被设计出来,结合局部学习和全局学习来去除鱼眼图像中的非线性畸变分布。
- Rectification module: 这一可微整流模块作为畸变参数和几何约束之间的连接器。如 Fig.1 第二行所示,为被扭曲的线条进行校正后的不失真的 line map。
通过最小化损失函数来训练这三个模块: 包含全局和局部感知的多尺度约束,以及检测到的 distorted lines 的曲率约束,用于预测畸变参数。由于所有的标定和矫正步骤都由一个深度神经网络来建模,用 end-to-end 的方式来训练是很自然的事。为了获得更好的成绩,在训练阶段每一张鱼眼图都要求标注好 end-to-end 和 distortion parameters。这样的话,我们创建了一个新的鱼眼镜头数据集,通过 convert the wireframe dataset to distorted Wireframe collections(D-Wireframe); the 3D model repository to fisheye SUNCG collections (Fish-SUNCG). 具体来说,D-wireframe 数据集是通过使用随机生成的畸变参数对透视图像进行畸变而创建的,the Fish-SUNCG 数据集则是通过在三维虚拟场景中渲染真实鱼眼镜头的形成的。
1.3 RelatedWork
在过去十年里,有很多研究致力于鱼眼矫正和畸变矫正的研究。。。
1.4 Our Contributions
本文提出 a novel end-to-end network 通过进一步利用几何约束来同时完成鱼眼镜头标定和图像畸变矫正。特别的,我们做了三大贡献:
- 我们提出了一种端到端的卷积神经网络,在鱼眼镜头标定和畸变图像矫正过程中施加的显式几何约束,实现了 state-of-the-art performance。
- 多尺度感知(Muti-scale perception) 被设计出来用于平衡在鱼眼图像中的非线性畸变分布。通过全局和局部学习方式获取更鲁棒的畸变参数,同时达到良好的矫正效果。
- 我们构建了一个新的大型鱼眼图像数据集来训练网络和评价矫正方法的有效性和效率。
2. General Fisheye Camera Model
给定一个焦距(focal length)为 $f$ 的针孔相机,透视投影模型(the perspective projection model)可以被描述为 $r = f*tan\theta$,这里 $r$ 代表主点(principal point)和图像中每个点的投影距离,$\theta$ 是入射光和相机光轴的角度。而鱼眼镜头则违背了这种透视投影模型,并且经常被一个一般的多项式投影模型所近似。
\begin{equation}
\label{projection distance}
r(\theta) = \sum_{i=1}^{n} k_i*\theta^{2i-1}, n=1,2,3,4,...
\end{equation}
通常来说,当 $n=5$ 时,该模型可以准确地近视鱼眼镜头的成像。
给定一个摄像机坐标系中的 3D scene point $\textbf{P}_c := (x_c, y_c, z_c)^T \in \mathbb{R}^3$,它将被投影到像平面,被鱼眼镜头折射获得畸变图 $\textbf{p}_d := (x_d, y_d)^T \in \mathbb{R}^2$,通过透视镜头不失真 $\textbf{p} := (x, y)^T \in \mathbb{R}^2$。畸变图 $\textbf{p}_d$ 和 矫正图 $\textbf{p}$ 的关系可以表示为 $\textbf{p}_d = r(\theta)*(cos{\varphi}, sin{\varphi})^T$,其中 $\varphi = arctan((y_d-y)/(x_d-x))$ 表示连接投影点和图像中心的射线与图像坐标系的x轴之间的夹角。假设像素坐标系是正交的,我们可以通过转换畸变图像坐标 $\textbf{p}_d$ 得到矫正图主点坐标 $(u, v)$ :
\begin{equation}
\label{pixel coordinates}
\left(
\begin{array}{c}
u\\
v\\
\end{array}
\right)
=
\left(
\begin{array}{cc}
m_u & 0\\
0 & m_v\\
\end{array}
\right)
\left(
\begin{array}{c}
x_d\\
y_d\\
\end{array}
\right)
+
\left(
\begin{array}{c}
u_0\\
v_0\\
\end{array}
\right)
\end{equation}
鱼眼图像的主点表示为 $u_0, v_0$,$m_u, m_v$ 分别描述水平方向和垂直方向单位距离上的像素个数。
通过 Eq.(2),一旦得到了参数$K_d = (k_1, k_2, k_3, k_4, k_5, m_u, m_v, u_0, v_0)$,就可以对鱼眼图像的畸变进行校正。因此,本文将对每一幅给定的鱼眼图像,准确地估计参数 $K_d$ 的同时消除图像畸变。
3. Deep Calibration and Rectification Model
在本节中,我们主要利用 CNNs 来利用 distorted lines 的场景几何形状与相应的鱼眼图像畸变参数之间的关系,来学习从原始输入的鱼眼图像到校正后的图像的映射函数。
3.1 Network Architecture
如 Fig.2 所示,我们的网络由三个模块组成:distorted lines perception module (DLP) 模块用来检测 distorted lines;line-guided parameter estimation module (LPE) 从全局和局部角度来预测畸变参数 $K_d$;rectification module 作为几何形状和矫正参数之间的桥梁。给定一张大小为 $HxW$ 的图像 $I$,distorted lines map 记为 $h \in \mathbb{R}^{HxW}$ 从 DLP 模块获得,随后将 distorted lines map $h$ 和原始鱼眼图像 $I$ 一起送给 LPE 模块利用全局和局部感知来预测畸变参数。最后 rectification module 通过分析矫正后的 distorted lines map $\hat{h}^{'}$ 被用于验证学习到的畸变参数 $K_d$ 的准确性。然后,我们能够学习矫正参数和校正图像以端到端的方式。
网络中每个训练数据包含:1)一张鱼眼图像 $I$;2)the ground truth distortion parameters $\hat{K}_{gt}$;3)the ground truth of distorted lines map $\hat{h}$;4)the ground truth of the corresponding rectified line map $\hat{h}^{'}$;5)对应的矫正图里的线条分割 $L=\{x_i, x_{i}^{'}\}_{i=1}^K$,这里 $x_i \in \mathbb{R}^{2}$ 和 $ x_{i}^{'} \in \mathbb{R}^{2}$ 是一条线段的两个端点。
Distorted Line Perception Module.
跟随边缘和线条检测的最新进展,我们使用 Pyramid Residual Modules (RPM) 和 Stacked Hourglass network 来从输入图像中学习 distorted lines $h \in \mathbb{R}^{HxW}$。具体来说,我们首先使用两个RPMs 从尺寸为 $HxWx3$ 输入图像中提取尺寸为 $\frac{H}{4} x \frac{W}{4} x 256$ 大小的 feature map。然后将 feature map 传递给 5 个 stacked hourglass modules。利用两个反卷积层对得到的特征进行放大,得到尺寸为 $HxWx16$ 的特征。最后使用 $1x1$ 大小的卷积核来预测 distorted lines map $h$。除预测层外,每个卷积/反卷积层均采用 BN 和 ReLU 处理。line segment map $\hat{h}$ 定义为:
\begin{equation}
\label{line segment map}
\hat{h}(p) = \begin{cases}
\ d(l) & if\ p \ is \ (nearly) \ on \ l \in L, \\
\ 0 & \ otherwise
\end{cases}
\end{equation}
这里 $d(l_i) = {\lVert {x_i - x_i^{'}} \rVert}_2$。预测的 map $h$ 不仅表示了像素点 $p$ 是否在线段上,而且预测的经过畸变矫正后的线段长短也隐含了畸变参数的信息。
Line-guided Parameters Estimation Module.
这个模块的目的是从图像中估计畸变参数。如上所述,预测的 distorted lines map 可以在一定程度上表征鱼眼图像的畸变。基于此,对于上个 DLP 模块预测得到的 distorted lines map $h$ 作为一种 geometric guidance,为 LPE 提供高层次的结构信息,然后 concat 上原始输入作为 LPE 的输入来估计多尺度畸变参数,输入维度是 $HxWx4$。如 Fig.2 所示,我们采用 ResNet-50 的 level 1 to 4 部分作为 LPE 模块的 backbone,考虑到鱼眼图像域内畸变分布的非线性还设计了一个全局和局部信息流分岔结构来实现多尺度感知。
全局预测通过 2 个 Conv 和 3 个 FC 来处理整个 feature map 以估计畸变参数。在全局预测的第一个 FC 层之前,使用全局平均池化操作来从图像提取全局特征信息。最后一个 FC 层输出一个 9-D 的向量代表畸变参数,用 $K_g$ 来表示。
考虑到扭曲的非线性分布,我们显式地使用 backbone 输出的裁剪 feature map 来局部估计畸变参数。我们把这个侧输出分成五个小块:中间区域 feature map 尺寸为 $6x6x1024$, 四周 feature map 尺寸为 $5x5x1024$,然后将这 5 组 sub-feature map 分别加上两个 FC 层和一个线性滤波器来预测局部参数,用 $\{ K_{loc}^k \}_{k=1}^5$ 来表示。这两个 FC 层的参数设置与全局预测中的相同,同时在这五组子特征图中共享它们的权重。由于参数 $m_u, m_v$ 和 $u_0, v_0$ 与整个图像有关,线性滤波器只更新在之前的输出中前5个失真参数 $k_1, k_2, ...k_5$,这样的话每个 $\{ K_{loc}^k \}$ 是一个 5-D 向量。在训练阶段,预测的参数 $\{ K_{loc}^k \}$ 用于约束全局预测输出。DLP 的输出是全局和局部参数的平均畸变参数,记为 $K_d$。
Rectification Module.
在这个模块中,我们取 LPE 模块预测的畸变参数 $K_d$ 作为输入来矫正输入图像和对应的 DLP 预测的 distorted lines segments map。假定矫正图像和鱼眼图像中的像素坐标分别为 $p=(x, y)$ 和 $p_d=(x_d, y_d)$, 那么他们的关系可以表示为:
\begin{equation}
\label{relationship}
p_d = \tau (p, K_d) =
\left(
\begin{array}{c}
u_0\\
v_0\\
\end{array}
\right)
+ \frac{r(\theta)p}{{\lVert {p} \rVert}_2}
\end{equation}
这样的话,利用双线性插值可以对 distorted lines map 和鱼眼图像进行矫正。
上述 rectification layer 的意义是明确连接畸变参数和几何结构之间的关系。估计的畸变参数越精确,distorted lines map 的校正效果越好。
3.2. Loss Function and Training Scheme
在我们网络中,我们可以 end-to-end 的输出 distorted lines map $h$、估计的畸变参数 $K_g$ 和 $K_{loc}^k, k=1,...,5$ 以及每个输入图像 $I$ 的 the rectified line segment map。受深度学习的启发,每个模块都设计为有监督学习。
Loss of Distorted Lines Map Learning.
考虑到图像中 distorted lines segments 在 Eq.3 中大部分均为 0(类别不平衡)。为了简化表示,将不位于任何 distorted lines segments 的像素集合记为负类别 $\Omega^{-}$,其它记为正类别 $\Omega^{+}$,即 $\Omega^{+} = \Omega - \Omega^{-}$。随后给予每个类别权重,定义损失函数为:
\begin{equation}
\label{DLM Loss}
L{line} = \frac{|\Omega^{-}|}{|\Omega|} \sum_{p \in \Omega^{+}}D(p) + \frac{|\Omega^{+}|}{|\Omega|} \sum_{p \in \Omega^{-}}D(p)
\end{equation}
当然,这是一个常规操作,其中 $D(p) = {\lVert {h(p) - \hat{h}(p)} \rVert}_2^2$。
Loss of Distortion Parameter Estimation.
在 LPE 模块中,我们尝试用一个分叉结构来预测畸变参数 $K_g$ 和 $\{K_{loc}^k\}_{k=1}^5$。 理想情况下,我们希望 LPE 模块的输出接近 ground-truth distortion parameters。全局预测 $K_g$ 时的 loss 函数为:
\begin{equation}
\label{DPE Loss1}
L_g = \frac{1}{9} \sum_{i=1}^9 w_i(K_g(i) - K_{gt}(i))^2
\end{equation}
这里 $K_g(i)$ 和 $K_{gt}(i)$ 分别代表预测扭曲参数 $K_g$ 和 ground-truth $K_{gt}$ 中第 $i$ 个值。权重 $w_i$ 用于缩放扭曲参数中不同分量之间的大小(用来归一化的)。局部预测时,将 sub feature map 预测部分扭曲参数的 loss 函数定义为:
\begin{equation}
\label{DPE Loss2}
L_{loc}^k = \frac{1}{5} \sum_{i=1}^5 w_i(K_{loc}^k(i) - K_{gt}^k(i))^2
\end{equation}
这里 $K_{loc}^k(i)$ 是扭曲参数 $K_{loc}^k$ 中第 $i$ 个值。
Global Curvature Constraint Loss.
$L_g$ 和 $L_{loc}$ 强制网络去拟合扭曲参数,然而仅仅优化它们是不够的,而且容易陷入局部最小值。同时,矫正后的图像中应是直线的 distorted lines 的几何形状与扭曲参数之间的关系为优化提供了更强的约束。如果 distorted lines 没有完全校正成直线,则估计的畸变参数不够精确,反之亦然。因此,我们通过 LPE 预测得到的参数 $K_d$ 来矫正 line map 后与 the ground truth of line map 计算之间的像素误差 $L_c$:
\begin{equation}
\label{RM Loss}
L_{c} = \frac{1}{N} \sum_{p_d \in \Omega^+} (F(p_d, K_d) - F(p_d, K_{gt}))^2
\end{equation}
这里 $F$ 是 Eq.4 中 $\tau$ 的 the inverse function,$N$ 则是 distorted line segment 中像素点数量。
Training Scheme.
说起来上面的各个部分的 loss 其实就只是加权的 L2 loss。网络培训过程分为两个阶段。在第一阶段中,我们使用 Eq.5 中定义的损失函数从头开始训练 distorted line 感知模块。第二阶段,当 DLP 模块收敛好了后,我们固定这些网络参数,学习畸变参数,这一阶段的损失函数为:
\begin{equation}
\label{Loss}
L = \lambda_g L_g + \lambda_{loc} \sum_{k=1}^5 L_{loc}^k + \lambda_c L_c
\end{equation}
目的是在训练中拟合参数模拟鱼眼图的畸变效果。Eq.9 中的 $\lambda_g, \lambda_{loc}, \lambda_c$ 是权重超参数用来平衡不同项。
4. Synthetic Dataset for Calibration
该神经网络的训练仍然存在一个关键问题,即需要真实的畸变参数以及注释良好的畸变和矫正线图。然而,据我们所知,还没有满足上述所有要求的大规模数据集。感谢最近发布的标注由直线的线框数据集和大型 3D 场景数据集 SUNCG 提供了不同语义的 3D 场景,我们建立了一个新的数据集,带有注释良好的 2D/3D 线段 $L$ 以及相应的畸变参数 $K_{gt}$ 用来训练。我们的两个数据集子集,来自线框数据集的变形线框集合(D-Wireframe)和来自 3D 模型库的鱼眼 SUNCG 集合(Fish-SUNCG),Fig.3 所示。

Figure 3. 样本数据从到到下分别来自 distorted wireframe 和 fisheye SUNCG collection 数据子集。
Distorted Wireframe Collection (D-Wireframe).
the wireframes datase 包含了 5462 张标注了分割直线的 perspective image,我们随机生成四组不同的畸变参数 $K_i$,按照 Eq.1 将图片转换为具有不同畸变效果的 fisheye image,这样的话 perspective image 及其对应的线段标注就可以被变形为具有 distorted line segment 段的 fisheye image。最终,我们生成了包含 20000 张训练图片和 1848 张测试图片的数据子集 $D_{wf}$。
Fisheye SUNCG Collection (Fish-SUNCG).

Figure 4. Fish-SUNCG生成示意图。每个相机分别配备透视镜头和鱼眼镜头。
在鱼眼畸变类型的多样性和灵活性方面,Dwireframe 数据集可以为网络训练提供更好的支持。然而,artificially distorting 的透视相机拍摄的图像不能完全表征真实场景中的鱼眼变形。我们从SUNCG 三维模型中,通过模拟图像形成的视角和鱼眼相机在相同的观察位置来解决这个问题,它包含 45K 不同的虚拟 3D 场景,手工创建逼真的房间和家具布局。在细节上,我们使用 Blender 通过指定摄像机姿态和成像形成模型来渲染图像。绘制协议 Fig.4 所示。对于线段的生成,我们去除三维模型的纹理,得到三维对象的线框模型。在此之后,我们手动移除线框的边缘,以得到物体边界上的线段。由于我们能够在没有度量误差的情况下控制图像的形成,数据样本可以用来训练我们的网络而不会丢失信息。最后,我们从 1000 个场景中生成 6000 对图像用于训练,从 125 个场景中生成 300 对图像用于测试。该数据子集记为 $D_{sun$。
5. Experiments
5.1. Implementation Details
我们遵循 3.2 节描述的训练方案。使用 $D_{wf}$ 数据子集中畸变图像和对应的 distorted lines segment map 来训练第一步的 DLP 模块。之后,我们固定 DLP 模块的权重,用 $D_{wf}$ 和 $D_{sun}$ 数据子集去训练其他部分的网络。训练和测试时的输入图片尺寸为 $320x320x3$。
Eq.9 中提到的超参数设置如下:$\lambda_c=50$, $\lambda_{loc} = \lambda_g = 1$,平衡参数 $W = \{w_1=0.1, w_2=0.1, w_3=0.5, w_4=1, w_5=1, w_6=0.1, w_7=0.1, w_8=0.1, w_9=0.1\}$。训练中的优化器为 the stochastic steepest descent method (SGD)。初始学习率设置为 0.01,每隔 100 个 epochs 乘以 0.1。网络一共迭代 300 个 epochs。我们的网络是在 PyTorch 平台上实现的,使用一台 Titan-X GPU 设备。
5.2. Evaluation Metrics
受益于我们提出的方法中的 DLP 模块,我们能够通过衡量 rectification module 输出的矫正后的 distorted lines map $\hat{h}^{'}$ 和 the ground truth $\hat{h}$ 来比较消除畸变的效果和恢复 line geometry 的性能。同时,我们重新定义了 Precision and Recall 来定量的衡量 $\hat{h}^{'}$ 和 $\hat{h}^{'}$ 之间的误差。进一步提出了用重投影误差(RPE)来评估矫正图像与鱼眼图像之间的像素偏差。另一方面,我们也采用了之前的评估指标,利用峰值信噪比(peak signal to noise ratio, PSNR)和结构相似度指数(structure similarity index, SSIM)对校正后的图像进行评估。
5.3. Comparison with State-of-the-art Methods
5.4. Ablation Study
在本节中,我们主要分析了我们所设计的包含几何学习的网络结构的有效性,包括 concat 后的四维输入图像和 LPE 中检测到的 distorted lines map,曲率约束(CSV)以及多尺度感知(MSP)用于局部和全局估计畸变参数。如 Fig.10 所示,一旦缺少 CSV 或者 MSP, 网络的矫正效果会变得不稳定,这意味着 over-rectified and under-rectified 会出现,其中以 RGB 鱼眼图加一维 line map 作为输入的矫正效果最好。
对于定性评价,我们通过 PSNR、SSIM 和 RPE 对校正后的图像进行质量评价,如 Tab.2 。更直观地展示了校正能力水平的差异,证明了 CVC、MSP 以及四维输入(RGB+Line)在我们的网络中发挥了关键作用。根据我们的分析,这可能是因为 network 从增强效应的 distorted lines 中获得了高层结构信息。此外,在这个实验中,最坏的结果仍然比最先进的方法要好,这也证明了我们网络的科学性和合理性。
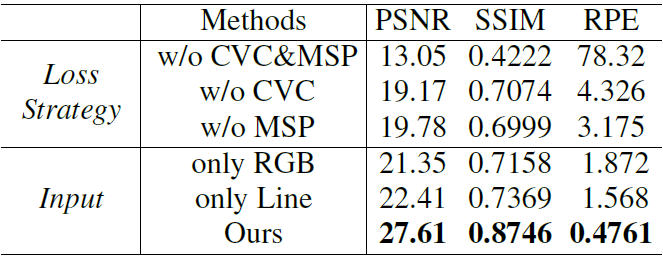
Table 2. 消融实验 to evaluate the rectified image quality of PSNR, SSIM and reprojection error (RPE).
6. Conclusion
本文提出了一种利用线约束对鱼眼镜头进行标定并自动消除单幅图像畸变的网络方法。为了训练网络,我们重用现有的具有丰富的二维和三维几何信息的数据集,生成用于鱼眼定标的合成数据集。该方法利用了几何感知深度特征、曲率约束和多尺度感知块的优点,在定性和定量两方面均优于现有方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号