
GAN Lecture 8 (2018)_Photo Editing
课程主页:提供作业相关
PS: 这里只是课程相关笔记
Photo Editing
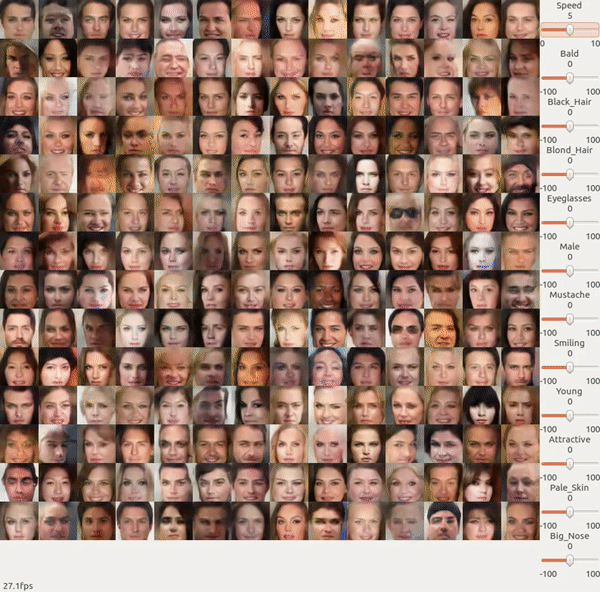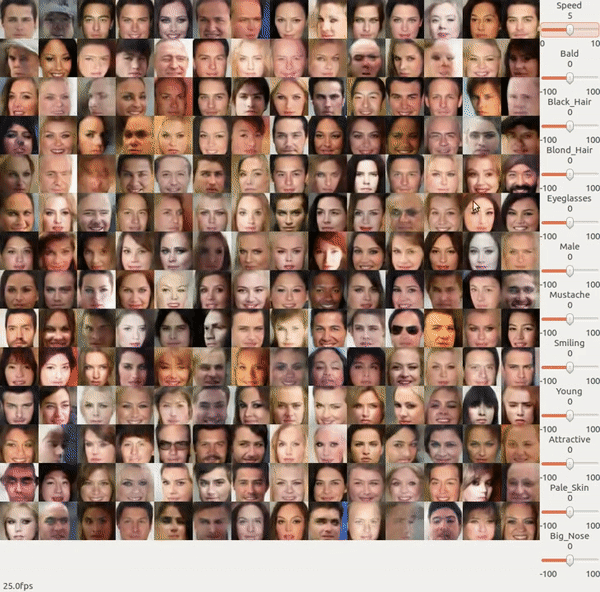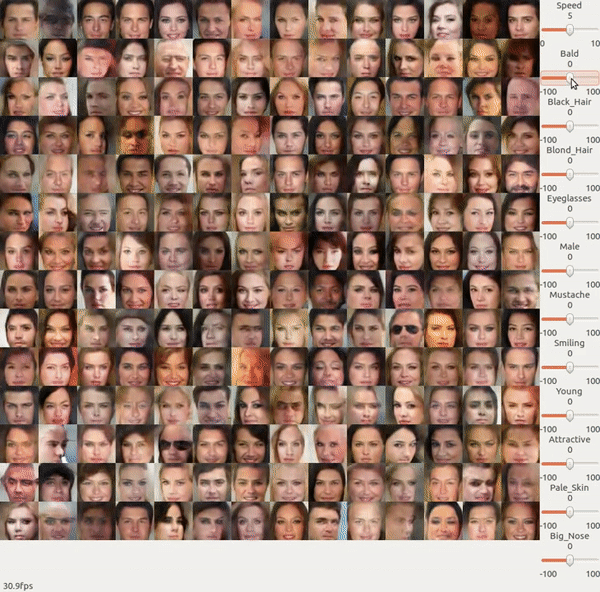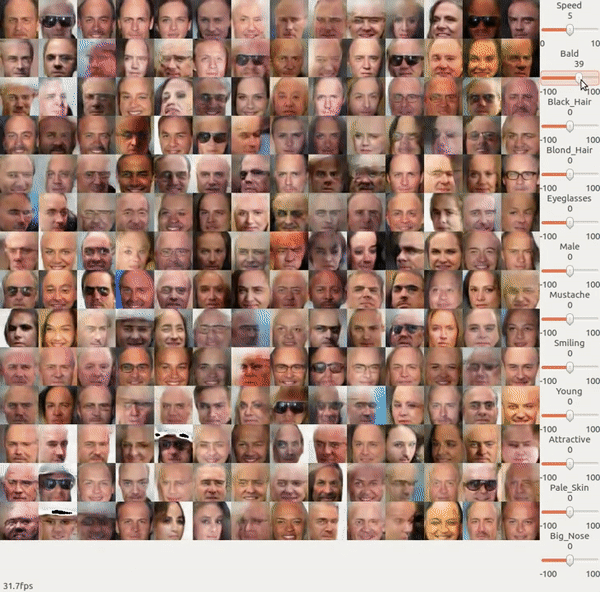
先来看一段 NVIDIA 展示的 GAN 的一个 demo,那这是怎么做的?
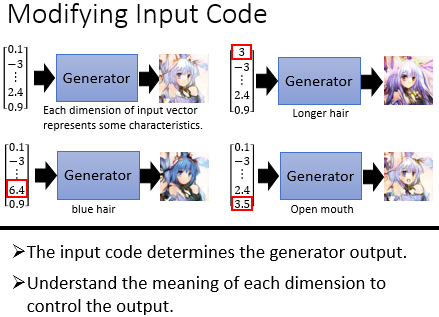
前面我们在做 GAN 的时候,回 input 一个 random vector,然后 output 一个人脸。前面我们说过,input vector 的每一个 dimension 其实可能对应了某一特征,这是我们并不知道这每一个 dimension 对应的特征到底是什么。
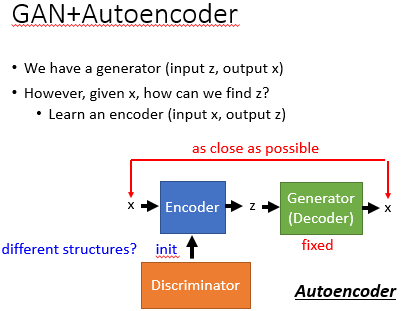
我们可以在一个训练好的 GAN 的基础上再 train 一个 Encoder 来反推出什么样的 z 能生成 x。即固定训练好的 Generator, 然后训练一个 Encoder 来使得输入 x 与其经过 Encoder 和 Generator 之后输出的 x 越接近越好。实际操作的时候我们可以让 Encoder 和 Discriminator 很像,然后用 Discriminator 的参数来初始化 Encoder。
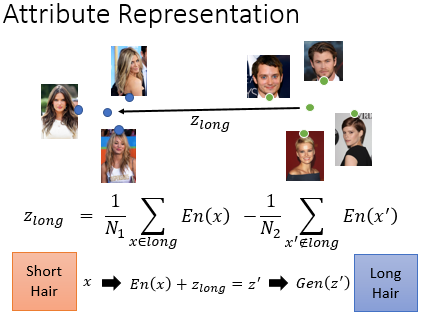
然后你就可以把长发人脸训练出来的 code 做平均后减去 短发人脸训练出来的 code 的平均向量,就可以知道怎样把短发人脸变成长发人脸了。
所以上面 NVIDIA 的 demo 里面它做的事情就是找出各种特性的人脸的 vector 是什么样子的,然后给它任何一张 image,它会先把那张 image 变成一个 code,再把这个 code 加上你要的特征的那个 vector 再丢到 Generator 里面去就好了。
再来看一个智能 PS 的 demo,视频太长就不贴出来了。这里来讲一下它是怎么做的:

首先我们用商品的例子来训练一个 Generator,上面的 Demo 中我们看到,给一张图片,然后你在这个图片上稍微做一些修改,结果就会产生一个新的商品。实现这个效果的做法大致是:先把这张图片反推出它在 code space 上面的哪一个位置,然后你把这个 code 小小的移动下就可以产生一张新的图,然后这张新的图要符合使用者给你的 constrain。
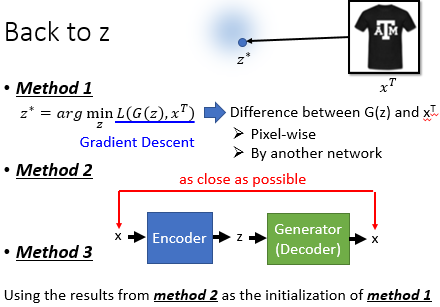
如何反推出图片在 code space 上面的哪一个位置大致有三种方法:第一种就是找到有个 z 使得它经过 Generator 之后与该图片越接近越好;第二种就是前一个 demo 中的方法;第三种方法就是用第二种方法得到的 z 来初始化第一种方法。

要实现智能 PS,我们要找到这样一个 $z^*$ 使得他一方面要符合使用者的 constrain,一方面还要保证新的 z 和原来的 $z_0$ 越接近越好,最后还要保证这个 z 丢到 Generator 里面产生额图片是好还是不好的。
Image super resolution

最后一个 demo 是一个图像超分辨率,它其实就是一个 Conditional GAN 的问题。
Image Completion

还有一个应用就是 Image Completion,这也是一个 Conditional GAN 的问题。

