
GAN Lecture 7 (2018)_ Info GAN, VAE-GAN, BiGAN
课程主页:提供作业相关
PS: 这里只是课程相关笔记
上一节我们学习了 GAN 的一些具体的例子,这里继续学习下一些 Unsupervised Conditional Generation 可能需要用到的一些技术。
1. InforGAN
在训练 GAN 的时候,我们通常比较期待 input 的那个 vector 它的每一个 dimension 代表了某种 specific 的 characteristic,然后你改了 input 的某个 dimension,output 就会有一个对应的变化,然后你可以知道每一个 dimension 它做的事情是神马。但是实际上往往 input 的 dimension 和 output 有时候观察不到有什么关系。
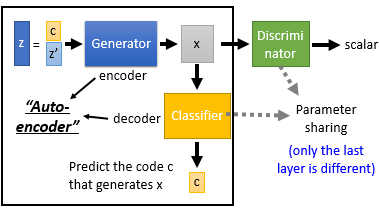
InforGAN 想要解决的就是这样的问题。区别于传统的 GAN,输入 vector 划分为两部分组成: $c$, $z^{'}$, 同时还增加了一个 classifier。这里你可以把 Generator 和 Classifier 看成是一个 "Auto-encoder", 只不过它和传统的 Auto-encoder 相反(Encoder 输入是 code 输出是图片,Decoder 输入时图片输出是 code。
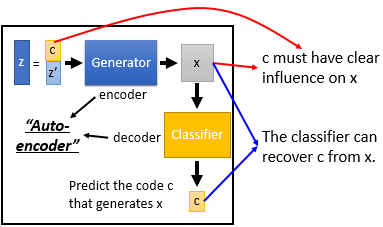
这里的理论依据是,如果今天 Generator 可以学到 input $c$ 的每一个维度对 output $x$ 都有一个明确的影响,那么 Classifier 就可以轻易捕捉到这种影响从而反推出原来的 $c$ 是什么。特别的 $z^{'}$ 代表的则是那些无法解释的部分。
2. VAE-GAN
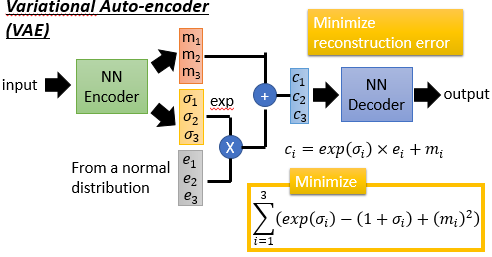
VAE-GAN 是 GAN 和 VAE 的结合体,现在主流的貌似有很多将 GAN 和 VAE 结合起来用。
| VAE | VAE-GAN |
 |
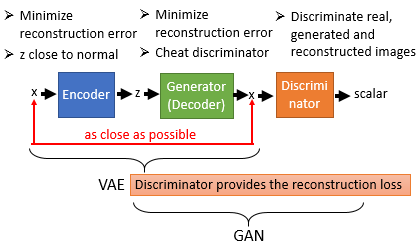 |
可以看出 VAE-GAN 是在 VAE 的基础上再加一个 Discriminator,这个 Discriminator 的工作就是 check 这个 decoder 的 output $x$ 看起来像不像是真的。在训练 VAE-GAN 的时候,一方面 Encoder-Decoder 想要让 Reconstruction Error 越小越好,另一方面 Decoder(Generator) 希望它的 output x 越 realistic 越好。从 VAE 的角度来看,Discriminator 的加入让 VAE 生成的图像更真实,从 GAN 角度来看,传统的 GAN 中 Generator 从来没见过真正的 image 长什么样子,那么它要花很多力气和时间去调参数才能让 Generator 真正学会产生更真实的 image,Encoder 的则可以让 Generator 见到真实的图片长什么样子,这就使得 VAE-GAN 学起来会更稳一点。

算法流程上,每次迭代:先 sample M 个 real image $x$,经过 Encoder 后得到 $\tilde{z}$,经过 Decoder 得到 reconstruct image $\tilde{x}$;再从某个 distribution 里 sample M 个 vector $z$,经过 Decoder 得到 生成图片 $\hat{x}$。然后先训练 Encoder,它要 minimize Autoencoder Reconstruction Error;再训练 Decoder,它一方面也是要 minimize Autoencoder Reconstruction Error,另一方面它还想要能骗过 Discriminator;最后训练 Discriminator,如果是个 real image 给高分,fake image 给低分,这里 fake image 有两种,一种是 reconstruct 出来的一种是 random code generat 出来的。还有一种做法是 Discriminator 不是一个二分类而是三分类,即将 reconstruct image 和 random code generat image 区别开来。
3. BiGAN
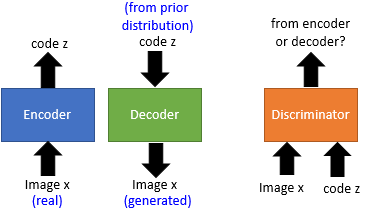
BiGAN 也是修改了 Autoencoder。我们知道,在 Autoencoder 里面是把 encoder 的 output 丢给 decoder 去做 reconstruction,但在 BiGAN 中 Encoder 和 Decoder 是相对独立工作的,如图所示它们的 output 和 input 不是接在一起的。Encoder 输入 real image 输出 code, Decoder 输入 code 输出 generated image, 随后一个 Discriminator 输入的是一对 image & code pair 来鉴别这对 pair 是从 Encoder 来的还是 Decoder 来的。

算法流程上,每次迭代:先 sample M 个 real image $x$,经过 Encoder 后得到 $\tilde{z}$; 从某个 distribution 里 sample M 个 vector $z$,经过 Decoder 得到 生成图片 $\tilde{x}$。然后先更新 Discriminator 使得真实 pair 分数高,生成 pair 的分数低;再更新 Encoder-Decoder 让 Discriminator 给真实 pair 低分,给生成 pair 高分。也就是说 Discriminator 想要做什么事, Encoder-Decoder 就要反着干就是了!
那么 BiGAN 这么做到底是有什么道理呢?
 |
 |
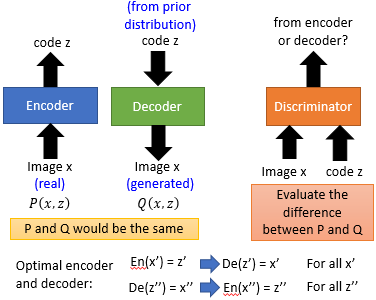
在 GAN 中 Discriminator 做的事情就是在衡量 real image 和 generated image 的某种 divergence 到底接不接近,那么今天我们在 BiGAN 中将 Encoder 的 input & output 合起来有一个 Joint Distribution $P(x, z)$,将 Decoder 的 input & output 合起来有一个 Joint Distribution $Q(x, z)$,今天 Discriminator 所要做的事情就是衡量着两个 Joint Distribution 之间的差异,然后我们希望通过 Discriminator 使得这两个 Distribution 越接近越好。理想情况下 BiGAN 中 Encoder 和 Decoder 是两个可以完全互逆的运算,尽管在训练中 Encoder 和 Decoder 没有连接在一起。从目的上来看 BiGAN 其实和 学习右图两个 AutoEncoder 是一样的(二者的 optimal solution 是一样的),但是实际上二者的 Error Surface 是不一样的。实验中会发现 AutoEncoder 生成的图片可能会和真实图片很像但是不清晰,而 BiGAN 相反,它生成的图像很清晰但是有可能非常不像,这可能是由于 BiGAN 比较容易抓到语义信息。
4. Triple GAN
Triple GAN 本身是一个 Conditional GAN。
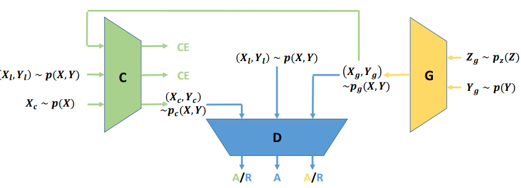
这里 Generator 吃一个随机向量 z 和一个 condition y,生成一个 x,将 x 和 y 的 pair 丢到 Discriminator 里面来分辨是 real 还是 fake。Triple GAN 是一个 Semi-Supervised Learning 的做法,假设你有少量的 labeled data,但是你有大量的 unlabeled data。今天 Classifier 的作用是输入一个 x,输出一个 y,在训练 Classifier 的时候你可以用 labeled real x/y pair 来训练,你也可以用 Generator 生成的 pair 来训练,目的是增加 training data,随后 Discriminator 会去鉴别 Classifier 的 input 跟 output 直接的关系。
5. Domain-adversarial training
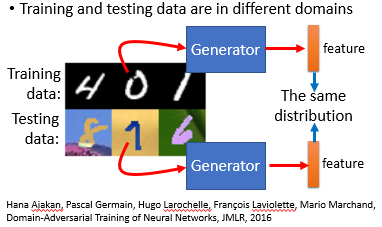
Domain-adversarial training 要做的就是我们要 learning 一个 Generator, 这个 Generator 的工作就是抽 feature。但是我们往往会遇到训练集和测试集的 domain 不一样的情况,这里我们可以用 GAN 的思路来抽取一个无关 domain 的 feature。

我们的做法是,训练一个 Generator作为 feature extractor, 训练一个 Discriminator 作为 domain classifier 来判断抽取的 feature 来自于哪个 domain,最后才是训练一个原先的 classifier 任务。原则上几个任务同时 train 是可以的,实际上会比较不稳,可以 iterative 的去 train.
这样的技术可以用在 Feature Disentangle 里面。假设你现在 learn 一个 sequence to sequence 的 Auto-Encoder。这个 Auto-Encoder 设计的目的可能是为了抽取一个代表发音资讯的 latent representation,但你这么做可能未必能抽取这样的 feature。
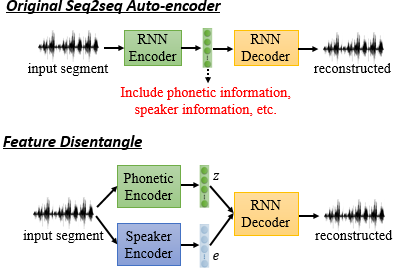
这是因为这个提取的 feature 包含很多的信息,而如果我们想要确定这个 feature 的哪些维度代表发音资讯,这就需要用到一个叫 Feature Disentangle 的技术。假设你现在要 learn 两个 Encoder,一个输出代表发音的资讯,一个输出代表语者的资讯,然后 Decoder 接收这两个讯息来还原出原来的声音讯号。这样的话我们就可以分别把抽取的发音资讯送给发音辨识系统,把抽取的语者资讯送给声纹辨识系统。当然你直接这么 learn 是没法保证结果的,这里你需要一些额外的 constrain。
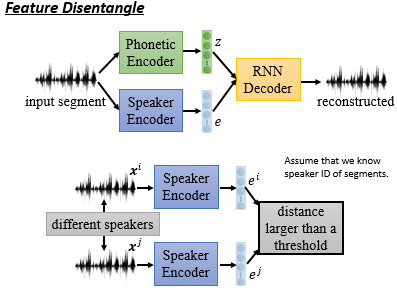
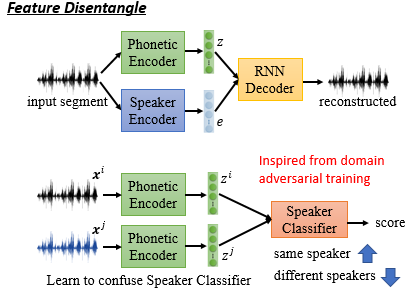
我们可以这么做:
 |
 |
对于语者资讯提取,我们很容易按照:如果是同一个人说的,那 output 的 embedding 尽可能相同;如果不是同一个人说的,那 output 的 embedding 尽可能不同。
对于发音资讯提取,则可以考虑按照 GAN 的思想,让 Phonetic Encoder 抽取出与语者无关的资讯!

