
深度学习笔记(十三)YOLO V3 (PyTorch) + Model Prune
上次记录了下 TensorFlow 版本,这次由于剪枝需要,尝试下 PyTorch 版本。
源码目录总览
yolov3-ultralytics ├── cfg // 网络定义文件 │ ├── yolov3.cfg │ ├── yolov3-spp.cfg │ ├── yolov3-tiny.cfg ├── data // 数据配置 │ ├── samples // 示例图片,detect.py 检测的就是这里的图片 │ ├── coco.names // coco 用于检测的 80 个类别的名字 │ ├── coco_paper.names // coco 原始 91 个类别的名字 │ ├── coco2014.data // coco 2014 版本的训练测试路径配置 │ └── coco2017.data // coco 2017 版本的训练测试路径配置 ├── utils // 核心代码所在文件夹 │ ├── __init__.py │ ├── adabound.py │ ├── datasets.py │ ├── google_utils.py │ ├── layers.py │ ├── parse_config.py │ ├── torch_utils.py │ └── utils.py ├── weights // 模型所在路径 │ ├── yolov3-spp-ultralytics.weights // 原始 YOLOV3 模型格式 │ └── yolov3-spp-ultralytics.pt // PyTorch 模型格式 ├── detect.py // demo 代码 ├── models.py // 核心代码 ├── test.py // 测试数据集 mAP ├── train.py // 模型训练 └── tutorial.ipynb // 使用教程
接下来,我们从数据加载、网络定义、网络训练、mAP 测试等角度来仔细过一遍代码
Inference
入手的第一步是,运行作者提供的 detect.py 这个 demo 检测示例。代码的运行参数熟悉检测的应该很容易从字面上理解,需要强调的是 --source 这个参数如果是 '0' 则会调用摄像头模型,默认是会读取 'data/samples' 文件夹下的示例图片。
整个代码按照 网络初始化 -> 模型加载 -> 输入图片加载 -> 前向推理 -> NMS 后处理 -> 可视化检测结果 的顺序来执行的。
Initialize Model
model = Darknet(opt.cfg, imgsz)
这里会根据网络定义文件(本文以 'cfg/yolov3-spp.cfg' 为例) 来定义网络结构,这个和官方 Darknet 是保存一样的设计的,这也是为什么这份代码生成的 pytorch 模型能与官方 Darknet 的模型能够无缝转换的原因。
这里贴一张 'cfg/yolov3-spp.cfg' 网络结构示意图:
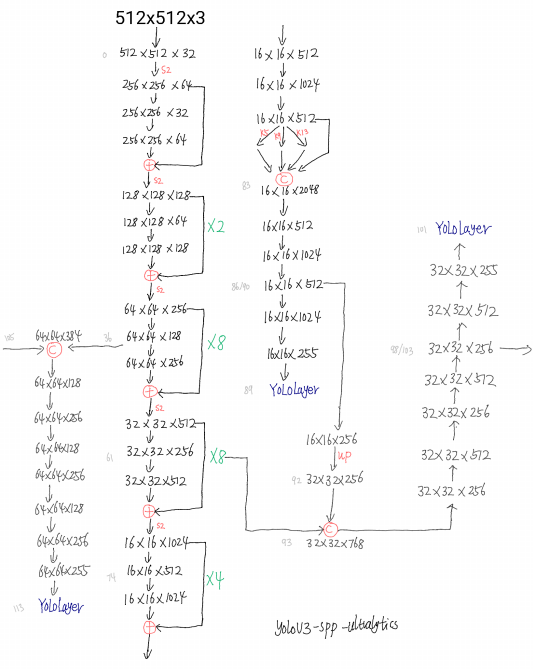
具体实现参考 models.py 这份代码。这里有个有意思的地方是默认会使用 thop 按照固定输入(1, 3, 480, 640)尺度统计参数量和计算量,看来在 pytorch 中 thop 的使用率还是挺高的。
imgsz 这个参数目的是为了 onnx 准备的,因为要固定输入尺寸。
Dataloader
dataset = LoadImages(source, img_size=imgsz)
这里的数据预处理包括 padding_resize 和 BGR2EGB,具体参考 utils/datasets.py。推理前图片还要经过 img /= 255.0 归一化操作,就是不知道为什么作者不把这个操作放到 datasets.py 里了。
Inference
除了常规的前向推理外,代码中还定义了一种 Augment images 推理方式,有兴趣的可以去瞅瞅。主要关注的是 YOLOLayer 层的推理,这基本上和 TensorFlow 版本 的差不多 。
YOLOV3 有三个尺度的预测输出,以上面图示 512x512 尺度的输入,coco 数据集训练的模型的第一个尺度(最小 feature map) 输出为例。YOLOLayer 前一层的输出维度为 16 x 16 x 255,16 x 16 对应的是 feature map size,255=3*(4+1+80),其中 3 是由于每个尺度上设计了 3 种 Anchor, 4 分别是中心点xy的偏移、宽高的偏移量,1 代表是否包含目标,80 则是具体类别的置信度。
流程上作者将 YOLOLayer 前一层的输出维度进行变换:
# p.view(bs, 255, 16, 16) -- > (bs, 3, 16, 16, 85) # (bs, anchors, grid, grid, xywh + classes) p = p.view(bs, self.na, self.no, self.ny, self.nx).permute(0, 1, 3, 4, 2).contiguous() # prediction
随后按照论文中的方式对预测结果进行 decode:
io = p.clone() # inference output io[..., :2] = torch.sigmoid(io[..., :2]) + self.grid # xy io[..., 2:4] = torch.exp(io[..., 2:4]) * self.anchor_wh # wh yolo method io[..., :4] *= self.stride torch.sigmoid_(io[..., 4:]) # 会改变 io return io.view(bs, -1, self.no), p # view [1, 3, 16, 16, 85] as [1, 768, 85]
最后三个尺度下的输出会 cancat 到一起,上面这个例子 pred 输出维度就应该是 1, 16128, 85
pred = model(img, augment=opt.augment)[0] #
具体实现参考 models.py
后面就是一些后处理工作了
# Apply NMS pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, multi_label=False, classes=opt.classes, agnostic=opt.agnostic_nms)
Train
训练这块算是这个版本的亮点之处了,相比于官方 Darknet 改进点还是很多的。
Dataloader
# Dataset dataset = LoadImagesAndLabels(train_path, img_size, batch_size, augment=True, hyp=hyp, # augmentation hyperparameters rect=opt.rect, # rectangular training cache_images=opt.cache_images, single_cls=opt.single_cls) # Dataloader batch_size = min(batch_size, len(dataset)) nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, num_workers=nw, shuffle=not opt.rect, # Shuffle=True unless rectangular training is used pin_memory=True, collate_fn=dataset.collate_fn)
区别于推理环节只需要加载和处理图片,这里加载的是类似于 COO 的数据集。以训练 coco2017.data 为例,训练数据 train_path 保存的是训练集的图片路径,LoadImagesAndLabels 中会对应加载 txt 格式的标注文件。
以 train2017/000000391895.jpg 为例,标注文件格式如下 (cx, cy, w, h),cls 序号从 0 开始
3 0.6490546875000001 0.7026527777777778 0.17570312500000002 0.59325 0 0.65128125 0.47923611111111114 0.2404375 0.8353611111111112 0 0.765 0.5468611111111111 0.05612500000000001 0.13361111111111112 1 0.7833203125 0.5577777777777778 0.047859375 0.09716666666666667
该图片尺寸(HxW)为 360x640, 训练时如果设置的训练尺度为 512,那么这张图片需要先保持高宽比缩放到 288x512 然后再 padding 到 512x512,当然对应的 label(也是 (cx, cy, w, h) 的相对坐标格式) 也要有所调整,最后图片要 BGR2EGB 转换。
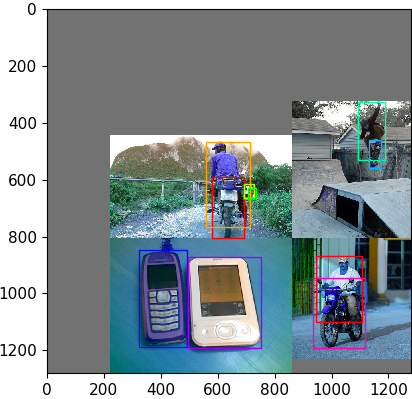
训练阶段如果不固定高宽比缩放则采用 load_mosaic 方式读取数据:
还是上面这个图片示例,记作 A,在随机挑选 3 张图片 B C D,先制作一个背景大图 img4。
对于图片 A, xc,yc 作为填充的原始图片右下角边界,
对于图片 B, xc,yc 作为填充的原始图片左下角边界,
对于图片 C, xc,yc 作为填充的原始图片右上角边界,
对于图片 D, xc,yc 作为填充的原始图片左上角边界。
最后再做个 random_affine:
 |
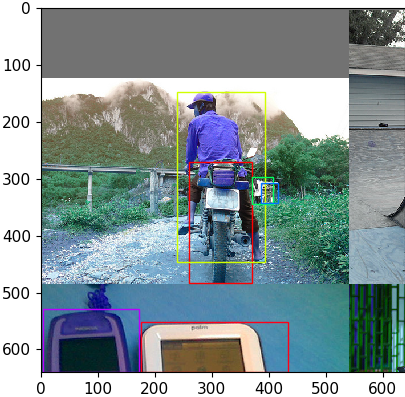 |
这里存在一个问题是目标可能被截断
数据增广包括:
- random_affine
- fliplr/flipud
- augment_hsv
- cutouts
具体参考 utils/datasets.py。
考虑到存在 crop 形式的数据增广,这里区别于 TensorFlow 版本 并没有在数据层就把 Anchor 匹配给做了,而是在训练中做了。无论数据层怎么操作 label,最后给到训练器的 label 是按照归一化的 [cx, cy, w, h] 的格式的!
Optimizer
比较有特点的是,代码中将可训练的参数划分为三组,卷积层权重为一组,bias 为一组,其它的参数为一组
pg0, pg1, pg2 = [], [], [] # optimizer parameter groups for k, v in dict(model.named_parameters()).items(): if '.bias' in k: pg2 += [v] # biases elif 'Conv2d.weight' in k: pg1 += [v] # apply weight_decay else: pg0 += [v] # all else
训练中,这三组参数设置不同学习速率
if opt.adam: # hyp['lr0'] *= 0.1 # reduce lr (i.e. SGD=5E-3, Adam=5E-4) optimizer = optim.Adam(pg0, lr=hyp['lr0']) # optimizer = AdaBound(pg0, lr=hyp['lr0'], final_lr=0.1) else: # momentum 一次设置后面都默认是这么多 optimizer = optim.SGD(pg0, lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True) optimizer.add_param_group({'params': pg1, 'weight_decay': hyp['weight_decay']}) # add pg1 with weight_decay optimizer.add_param_group({'params': pg2}) # add pg2 (biases)
基础学习率采用 cosine
lf = lambda x: (((1 + math.cos(x * math.pi / epochs)) / 2) ** 1.0) * 0.95 + 0.05 # cosine
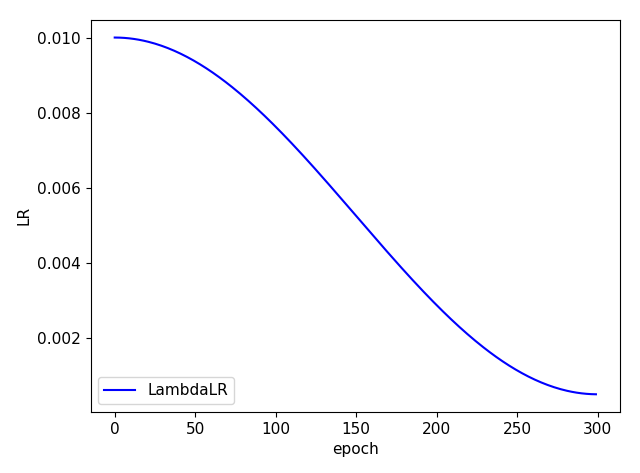
同时,代码中也设计了 warmup 训练方式:
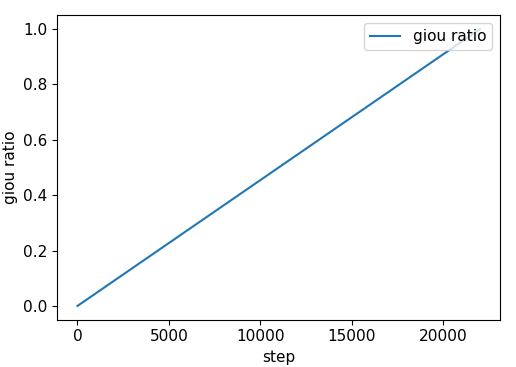
nb = len(dataloader) # number of batches n_burn = max(3 * nb, 500) # Burn-in if ni <= n_burn: xi = [0, n_burn] # x interp model.gr = np.interp(ni, xi, [0.0, 1.0]) # giou loss ratio (obj_loss = 1.0 or giou) accumulate = max(1, np.interp(ni, xi, [1, 64 / batch_size]).round()) for j, x in enumerate(optimizer.param_groups): # pg0 pg1 pg2 # bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0 x['lr'] = np.interp(ni, xi, [0.1 if j == 2 else 0.0, x['initial_lr'] * lf(epoch)]) x['weight_decay'] = np.interp(ni, xi, [0.0, hyp['weight_decay'] if j == 1 else 0.0]) if 'momentum' in x: x['momentum'] = np.interp(ni, xi, [0.9, hyp['momentum']])
| learning rate | weight decay |
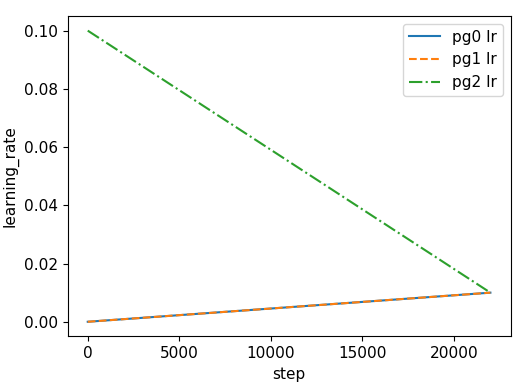 |
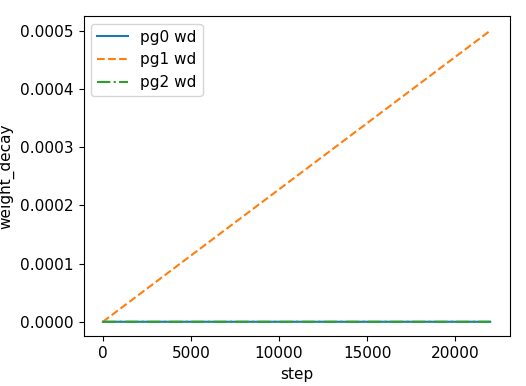 |
| momentum | accumulate |
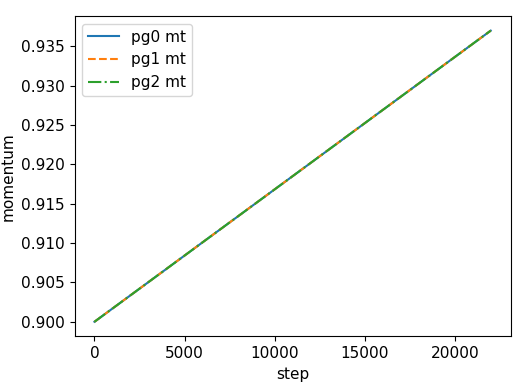 |
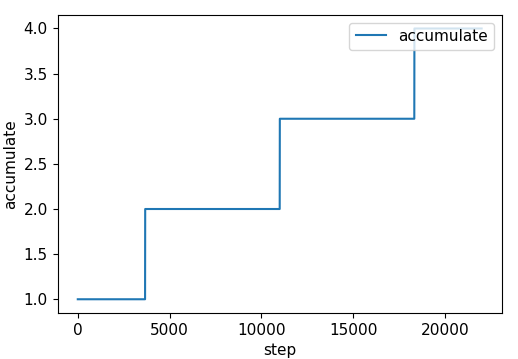 |
model.gr |
|
 |
值得注意的是:Optimize 是每隔 accumulate 个 batch 才更新模型的,也就是说不考虑 warmup 的情况下,训练的实际 batch_size = 64。
accumulate = max(round(64 / batch_size), 1)
Others
同其它版本一样,这份代码也支持多尺度训练,且是每 effective bs = batch_size * accumulate 更新一次训练尺度
训练还采用了 Model Exponential Moving Average 机制
ema = torch_utils.ModelEMA(model)
除了一些预定义的超参数外,还要关注下 model.gr 和 model.class_weights,同预定义的 cls, cls_pw, obj, obj_pw 一样这些都是计算 loss 所准备的一些权重项
model.gr = 1.0 # giou loss ratio (obj_loss = 1.0 or giou) model.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) # attach class weights
LOSS
loss, loss_items = compute_loss(pred, targets, model)
这部分定义在 utils/utils.py 文件中。
首先将回归后的 Anchor 和 GT 尝试进行匹配,匹配方式是中心点方式匹配,这里存在一个隐含的风险是有可能存在 GT 没有任何匹配 Anchor,其他版本中是会为该 GT 寻找一个最大匹配项,这里没有,默认舍弃了。
匹配函数 build_targets:


def build_targets(p, targets, model): # Build targets for compute_loss(), input targets(image,class,x,y,w,h) nt = targets.shape[0] tcls, tbox, indices, anch = [], [], [], [] gain = torch.ones(6, device=targets.device) # normalized to gridspace gain off = torch.tensor([[1, 0], [0, 1], [-1, 0], [0, -1]], device=targets.device).float() # overlap offsets style = None multi_gpu = type(model) in (nn.parallel.DataParallel, nn.parallel.DistributedDataParallel) for i, j in enumerate(model.yolo_layers): # 每个尺度输出 anchors = model.module.module_list[j].anchor_vec if multi_gpu else model.module_list[j].anchor_vec gain[2:] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gain na = anchors.shape[0] # number of anchors at = torch.arange(na).view(na, 1).repeat(1, nt) # anchor tensor, same as .repeat_interleave(nt) # Match targets to anchors a, t, offsets = [], targets * gain, 0 if nt: # r = t[None, :, 4:6] / anchors[:, None] # wh ratio # j = torch.max(r, 1. / r).max(2)[0] < model.hyp['anchor_t'] # compare j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n) = wh_iou(anchors(3,2), gwh(n,2)) a, t = at[j], t.repeat(na, 1, 1)[j] # filter # overlaps gxy = t[:, 2:4] # grid xy z = torch.zeros_like(gxy) if style == 'rect2': g = 0.2 # offset j, k = ((gxy % 1. < g) & (gxy > 1.)).T a, t = torch.cat((a, a[j], a[k]), 0), torch.cat((t, t[j], t[k]), 0) offsets = torch.cat((z, z[j] + off[0], z[k] + off[1]), 0) * g elif style == 'rect4': g = 0.5 # offset j, k = ((gxy % 1. < g) & (gxy > 1.)).T l, m = ((gxy % 1. > (1 - g)) & (gxy < (gain[[2, 3]] - 1.))).T a, t = torch.cat((a, a[j], a[k], a[l], a[m]), 0), torch.cat((t, t[j], t[k], t[l], t[m]), 0) offsets = torch.cat((z, z[j] + off[0], z[k] + off[1], z[l] + off[2], z[m] + off[3]), 0) * g # Define b, c = t[:, :2].long().T # image, class gxy = t[:, 2:4] # grid xy gwh = t[:, 4:6] # grid wh gij = (gxy - offsets).long() gi, gj = gij.T # grid xy indices # Append indices.append((b, a, gj, gi)) # image, anchor, grid indices tbox.append(torch.cat((gxy - gij, gwh), 1)) # box anch.append(anchors[a]) # anchors tcls.append(c) # class if c.shape[0]: # if any targets assert c.max() < model.nc, 'Model accepts %g classes labeled from 0-%g, however you labelled a class %g. ' \ 'See https://github.com/ultralytics/yolov3/wiki/Train-Custom-Data' % ( model.nc, model.nc - 1, c.max()) return tcls, tbox, indices, anch
匹配函数返回四个变量 tcls, tbox, indices, anchors,还是以上面的示例 GT 同第一个尺度的 Anchor 匹配为例:
Anchor 预定义如下,标记部分是第一个尺度(最小 featuremap 用来检测大目标):
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
1. 将这个尺度的 Anchor 映射到该 featuremap 尺度得到 anchors
2. 将 GT 映射到该 featuremap 尺度得到 t

3. 中心点方式匹配 ($Anchor_{num} \times GT_{num}$)

这样的话匹配的 Anchor 索引 a=[0, 0,1,1, 2] 和 GT 为 下图 t,b 和 c 则分别代表匹配的 GT 在一个 batch 中的 index 和 类别 id:

b c
gij 计统计的是匹配的 GT 的中心点坐标,gi, gj 分别是 center_x 和 center_y

gi gj
最后输出的四个变量如下
tcls.append(c) # class tbox.append(torch.cat((gxy - gij, gwh), 1)) # box indices.append((b, a, gj, gi)) # image, anchor, grid indices anch.append(anchors[a]) # anchors
这里可以看出由 indices 和 anch 可以还原成匹配的 Anchor 所在的位置,而由 indices 和 tbox 可以还原出匹配的 GT 所在的位置
有了匹配结果我们就可以确定哪些作为正样本哪些作为负样本和每个正样本的回归目标了,继而可以计算出 分类和回归 Loss 了
是否包含目标 lobj 和目标类别分类 lcls 的 Loss 都采用 BCEWithLogitsLoss,如果超参数 fl_gamma 不为零,则采用 FocalLoss 加持,特别的 BCELoss 还分别有 cls_pw(1.0)、obj_pw(1.0) 两个权重加持。目标的回归 Loss 采用的 GIoU Loss,偶然在 CIoU 这篇论文开源的 github issue 里见到本代码作者询问 CIoU Loss 的一些实现细节,我想后期本代码作者应该也会加上 CIoU Loss 的吧。
除此之外,本代码作者还考虑将是否包含目标的 lobj Loss 用 giou ratio 加持,即 GIoU 越大,目标 label 越接近于 1(原本是固定值 1),目的应该是为了给匹配不好的 GT 弱一点的监督信号,降低训练难度。
tobj[b, a, gj, gi] = (1.0 - model.gr) + model.gr * giou.detach().clamp(0).type(tobj.dtype) # giou ratio smooth lobj += BCEobj(pi[..., 4], tobj) # obj loss
最后,这三个 Loss 再分别由 giou(3.54)、obj(64.3) 、cls(37.4) 这三个权重值加持,至于这三个值是怎么来的,后面有时间我再研究下。
那么最后整个检测的 loss = lbox + lobj + lcls,如果你用过 TensorFlow 版本 的代码你会发现,相同的还是很多的,改进点就是这些权重项和 giou ratio 了。
回过头一看你会发现 model.class_weights 这一个权重项代码中并没有使用。
有关训练的部分就到此差不多,后面有时间再有坑填坑吧。
Evaluate COCO
这部分一般也都是工具性的调用,我就没仔细看了。反正你如果要对比不同的框架或者代码训练的模型的性能,选择其中一种然后按照对应的格式准备数据就好了。
Q1
有关这份代码的简单理解就到此为止了,剩下一些要填的坑等后面有时间再补吧。待填坑包括:
1. 数据增广
2. 权重值设定的依据
3. 可以试验下 HAMBox 中用回归后的 Anchor 替换初始 Anchor 来匹配的思想所加持的效果
4. 替换 GIoU Loss 为 CIoU Loss
接下来就是以此代码训练的模型,试试 剪枝 了
模型裁剪
这里仅记录下自己的模型在自己的数据集上的剪枝过程,参考代码
PS: 参考代码基于的 yolov3-ultralytics 代码版本较老,而我用的版本较新,因此我是把参考代码里涉及到的代码移植并修改了过来。涉及的代码文件主要包括:
yolov3-ultralytics ├── train_prune.py # 合并自己的 train.py 和 裁剪代码中的 train.py 中涉及 BN 层压缩部分 ├── models.py ├── utils │ └── prune_utils.py └── layer_channel_prune.py
BN 层
这里展示的模型裁剪,都是通过压缩 BN 层的 gamma 参数来降低通道或层的重要性,最终实现裁剪网络的
BN: 目的是防止过拟合。对于卷积层来说,批量归一化一般发生在卷积计算之后、应用激活函数之前。BN 层对每个通道的输出分别做归一化操作,每个通道拥有独立的拉伸和偏移参数(标量)。
BN 层的计算过程参考下面:
# 参与求梯度和迭代的拉伸和偏移参数,分别初始化为 1 和 0 self.gamma = self.params.get('gamma', shape=shape, init=init.One()) self.beta = self.params.get('beta', shape=shape, init=init.Zero()) # 不参与求梯度和迭代的变量,全初始化成 0 self.moving_mean = nd.zeros(shape) self.moving_var = nd.zeros(shape) eps = 1e-5, momentum = 0.9 # tf/mxnet def batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum): # 通过autograd来判断当前模式是训练模式还是预测模式 if not autograd.is_training(): # 如果是在预测模式下,直接使用传入的移动平均所得的均值和方差 X_hat = (X - moving_mean) / nd.sqrt(moving_var + eps) else: if len(X.shape) == 2: mean = X.mean(axis=0) var = ((X - mean) ** 2).mean(axis=0) else: mean = X.mean(axis=(0, 2, 3), keepdims=True) var = ((X - mean) ** 2).mean(axis=(0, 2, 3), keepdims=True) # 训练模式下用当前的均值和方差做标准化 X_hat = (X - mean) / nd.sqrt(var + eps) # 更新移动平均的均值和方差 moving_mean = momentum * moving_mean + (1.0 - momentum) * mean moving_var = momentum * moving_var + (1.0 - momentum) * var Y = gamma * X_hat + beat # 拉伸和偏移 return Y, moving_mean, moving_var
Stage1 常规训练
backbone 是 MobileNetV2,测试尺度是 320x480,训练使用多尺度训练(保持高宽比),PyTorch 统计的计算量为 3.6 GFLOPs, mAP=0.955
Stage2 稀疏化训练
使用 0.01 的学习率,迭代了 300 epoch,稀疏化训练的超参数为 --sr --s 0.0001 --prune 1
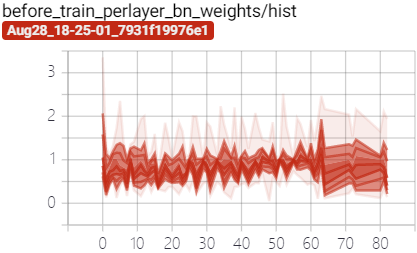
 较大的 s 会导致性能下降太快,加大学习率可以加快通道稀疏化,如下图所示,红色是最终选取的(lr0=0.01, s=0.0001)超参数,对比蓝色(lr0=0.001, s=0.001)的稀疏化训练:
较大的 s 会导致性能下降太快,加大学习率可以加快通道稀疏化,如下图所示,红色是最终选取的(lr0=0.01, s=0.0001)超参数,对比蓝色(lr0=0.001, s=0.001)的稀疏化训练:

对比常规训练发现,稀疏化的模型比常规训练还高一丢丢,同时对比训练 loss 和测试 loss 不难发现,稀疏化的模型泛化性能有所提升!
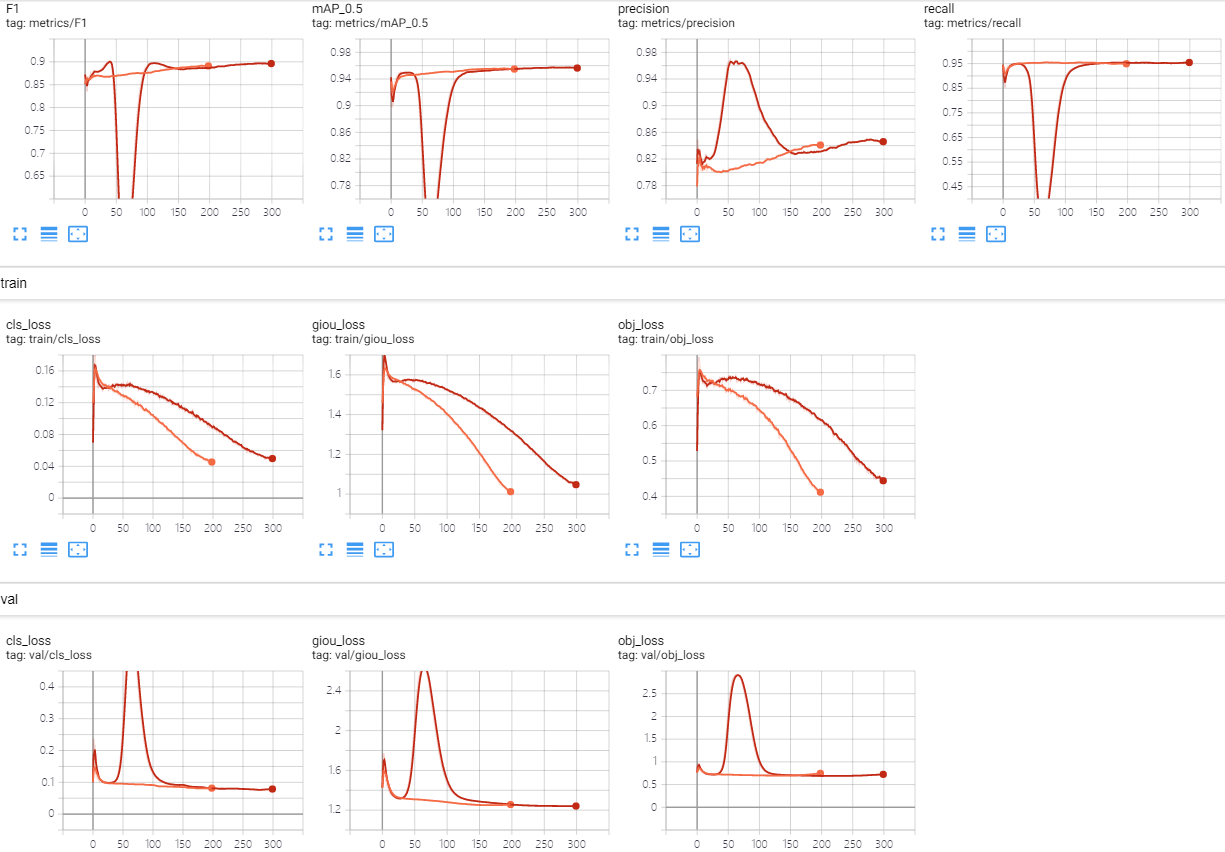
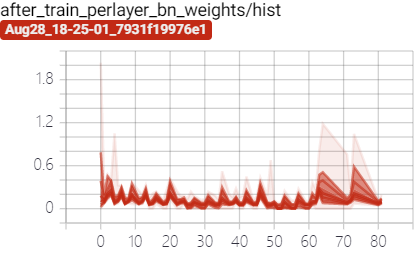
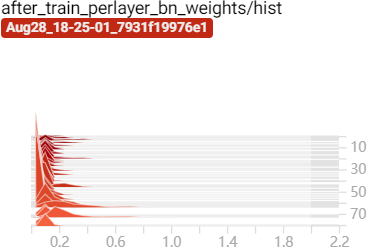
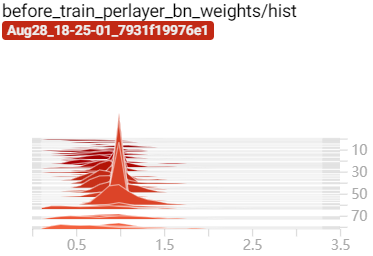
经过稀疏化训练后 BN 层的 $\gamma$ 参数向 0 压缩:
 |
 |
 |
 |
训练过程中 BN 层 $\gamma$ 参数变化:
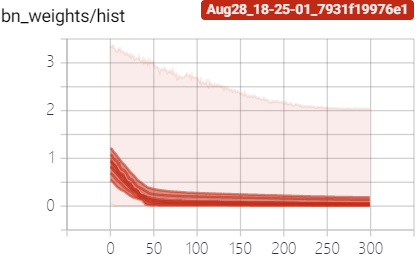 |
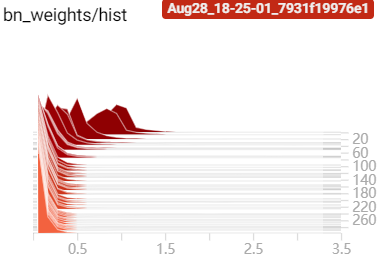 |
而受 BN 层 参数变化的影响,BN 层的权重在训练过程中也在不断的调整:
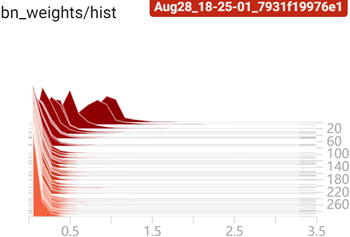
这里选择迭代 259 epoch mAP=0.957 的模型作为待裁剪模型
Stage3-1 通道裁剪
- 将所有允许被裁剪的层中 BN 层的 gamma 参数搜集后排序,按照 global_percent 超参数计算裁剪阈值 thresh
- 根据 裁剪阈值 thresh 将每一层中 BN 层 gamma 参数小于裁剪阈值 thresh 的通道标记为待裁剪,如果待裁剪通道数大于 min_channel_num=channels * layer_keep,则排序只保留 min_channel_num 个通道为待裁剪
obtain_filters_mask
- 涉及 shortcut(eltwise) 关联的层,只有对应的通道都裁剪时才裁剪
merge_mask
- 去除待裁剪通道中 BN 层 beat 的影响(通过更新待裁剪层下一层的 conv-bias 或者 bn-running_mean 来实现)
prune_model_keep_size2
- 根据裁剪情况,定义新的网络,并复制权重
参考代码中还有一个层裁剪,我还没时间改通,因此先不管了。
注意,由于我使用的是 MobileNetV2 作为 backbone,原始代码并不支持 group conv 的裁剪工作(因为通道裁剪的原理是根据 BN 层的权重情况按阈值裁剪的,裁剪的通道数不固定,而 group conv 的输入和输出是成倍数对应关系的,裁剪代码没法保证 group conv 成对裁剪),这里需要修改 layer_channel_prune.py, 修改方案我想到了两种
1. 对于 group conv 输入输出保留相同数量的通道数(取两者按阈值裁剪后保留的通道数的最大值)
2. 对于 group conv 输入输出待裁剪通道取二者按阈值裁剪的交集
方案一
shortcuts=0, global_percent=0.2, layer_keep=0.7
""" global_percent=0.2, layer_keep=0.7, shortcuts=0, weights='weights/sparse_last_29_0.94.pt') Model Summary: 195 layers, 2.48115e+06 parameters, 2.48115e+06 gradients, 3.6 GFLOPS Global Threshold should be less than 0.2980. layer index: 0 total channel: 32 remaining channel: 29 layer index: 1 total channel: 32 remaining channel: 22 layer index: 2 total channel: 32 remaining channel: 22 layer index: 3 total channel: 16 remaining channel: 12 layer index: 4 total channel: 72 remaining channel: 50 layer index: 5 total channel: 72 remaining channel: 50 layer index: 6 total channel: 24 remaining channel: 18 layer index: 7 total channel: 72 remaining channel: 50 layer index: 8 total channel: 72 remaining channel: 50 layer index: 9 total channel: 24 remaining channel: 16 layer index: 11 total channel: 108 remaining channel: 82 layer index: 12 total channel: 108 remaining channel: 82 layer index: 13 total channel: 32 remaining channel: 22 layer index: 14 total channel: 144 remaining channel: 100 layer index: 15 total channel: 144 remaining channel: 100 layer index: 16 total channel: 32 remaining channel: 22 layer index: 18 total channel: 144 remaining channel: 111 layer index: 19 total channel: 144 remaining channel: 111 layer index: 20 total channel: 32 remaining channel: 22 layer index: 22 total channel: 144 remaining channel: 100 layer index: 23 total channel: 144 remaining channel: 100 layer index: 24 total channel: 64 remaining channel: 44 layer index: 25 total channel: 288 remaining channel: 276 layer index: 26 total channel: 288 remaining channel: 276 layer index: 27 total channel: 64 remaining channel: 44 layer index: 29 total channel: 288 remaining channel: 276 layer index: 30 total channel: 288 remaining channel: 276 layer index: 31 total channel: 64 remaining channel: 44 layer index: 33 total channel: 288 remaining channel: 276 layer index: 34 total channel: 288 remaining channel: 276 layer index: 35 total channel: 64 remaining channel: 44 layer index: 37 total channel: 288 remaining channel: 267 layer index: 38 total channel: 288 remaining channel: 267 layer index: 39 total channel: 96 remaining channel: 67 layer index: 40 total channel: 432 remaining channel: 414 layer index: 41 total channel: 432 remaining channel: 414 layer index: 42 total channel: 96 remaining channel: 67 layer index: 44 total channel: 432 remaining channel: 416 layer index: 45 total channel: 432 remaining channel: 416 layer index: 46 total channel: 96 remaining channel: 96 layer index: 48 total channel: 432 remaining channel: 391 layer index: 49 total channel: 432 remaining channel: 391 layer index: 50 total channel: 160 remaining channel: 112 layer index: 51 total channel: 720 remaining channel: 719 layer index: 52 total channel: 720 remaining channel: 719 layer index: 53 total channel: 160 remaining channel: 112 layer index: 55 total channel: 720 remaining channel: 720 layer index: 56 total channel: 720 remaining channel: 720 layer index: 57 total channel: 160 remaining channel: 149 layer index: 59 total channel: 720 remaining channel: 697 layer index: 60 total channel: 720 remaining channel: 697 layer index: 61 total channel: 320 remaining channel: 224 layer index: 62 total channel: 128 remaining channel: 102 layer index: 63 total channel: 128 remaining channel: 102 layer index: 64 total channel: 256 remaining channel: 179 layer index: 71 total channel: 128 remaining channel: 95 layer index: 72 total channel: 128 remaining channel: 95 layer index: 73 total channel: 256 remaining channel: 179 layer index: 80 total channel: 128 remaining channel: 93 layer index: 81 total channel: 128 remaining channel: 93 layer index: 82 total channel: 256 remaining channel: 179 Prune channels: 1525 Prune ratio: 0.108 Model Summary: 195 layers, 1.86416e+06 parameters, 1.86416e+06 gradients, 2.3 GFLOPS """
裁剪完了计算量变成了 2.3 GFLOPs
方案二
考虑到 BN 层压缩的程度并不大,因此尝试的裁剪幅度并不大 shortcuts=0, global_percent=0.19, layer_keep=0.5
global_percent=0.19, layer_keep=0.5, shortcuts=0, weights='weights/sparse_stage1_last_259_0.9574.pt' Model Summary: 195 layers, 2.48115e+06 parameters, 2.48115e+06 gradients, 3.6 GFLOPS original model mAP of the model is 0.9569 Global Threshold should be less than 0.00013. layer index: 0 total channel: 32 remaining channel: 29 layer index: 1 total channel: 32 remaining channel: 32 rectify_layer index: 1 total channel: 32 remaining channel: 32 layer index: 2 total channel: 32 remaining channel: 32 layer index: 3 total channel: 16 remaining channel: 16 layer index: 4 total channel: 72 remaining channel: 72 rectify_layer index: 4 total channel: 72 remaining channel: 72 layer index: 5 total channel: 72 remaining channel: 72 layer index: 6 total channel: 24 remaining channel: 24 layer index: 7 total channel: 72 remaining channel: 72 rectify_layer index: 7 total channel: 72 remaining channel: 72 layer index: 8 total channel: 72 remaining channel: 72 layer index: 9 total channel: 24 remaining channel: 24 layer index: 11 total channel: 108 remaining channel: 108 rectify_layer index: 11 total channel: 108 remaining channel: 108 layer index: 12 total channel: 108 remaining channel: 108 layer index: 13 total channel: 32 remaining channel: 32 layer index: 14 total channel: 144 remaining channel: 143 rectify_layer index: 14 total channel: 144 remaining channel: 143 layer index: 15 total channel: 144 remaining channel: 143 layer index: 16 total channel: 32 remaining channel: 32 layer index: 18 total channel: 144 remaining channel: 143 rectify_layer index: 18 total channel: 144 remaining channel: 143 layer index: 19 total channel: 144 remaining channel: 143 layer index: 20 total channel: 32 remaining channel: 32 layer index: 22 total channel: 144 remaining channel: 138 rectify_layer index: 22 total channel: 144 remaining channel: 138 layer index: 23 total channel: 144 remaining channel: 138 layer index: 24 total channel: 64 remaining channel: 64 layer index: 25 total channel: 288 remaining channel: 227 rectify_layer index: 25 total channel: 288 remaining channel: 227 layer index: 26 total channel: 288 remaining channel: 227 layer index: 27 total channel: 64 remaining channel: 61 layer index: 29 total channel: 288 remaining channel: 229 rectify_layer index: 29 total channel: 288 remaining channel: 229 layer index: 30 total channel: 288 remaining channel: 229 layer index: 31 total channel: 64 remaining channel: 61 layer index: 33 total channel: 288 remaining channel: 259 rectify_layer index: 33 total channel: 288 remaining channel: 259 layer index: 34 total channel: 288 remaining channel: 259 layer index: 35 total channel: 64 remaining channel: 62 layer index: 37 total channel: 288 remaining channel: 283 rectify_layer index: 37 total channel: 288 remaining channel: 283 layer index: 38 total channel: 288 remaining channel: 283 layer index: 39 total channel: 96 remaining channel: 96 layer index: 40 total channel: 432 remaining channel: 411 rectify_layer index: 40 total channel: 432 remaining channel: 411 layer index: 41 total channel: 432 remaining channel: 411 layer index: 42 total channel: 96 remaining channel: 96 layer index: 44 total channel: 432 remaining channel: 417 rectify_layer index: 44 total channel: 432 remaining channel: 417 layer index: 45 total channel: 432 remaining channel: 417 layer index: 46 total channel: 96 remaining channel: 96 layer index: 48 total channel: 432 remaining channel: 372 rectify_layer index: 48 total channel: 432 remaining channel: 374 layer index: 49 total channel: 432 remaining channel: 374 layer index: 50 total channel: 160 remaining channel: 149 layer index: 51 total channel: 720 remaining channel: 360 rectify_layer index: 51 total channel: 720 remaining channel: 389 layer index: 52 total channel: 720 remaining channel: 389 layer index: 53 total channel: 160 remaining channel: 129 layer index: 55 total channel: 720 remaining channel: 360 rectify_layer index: 55 total channel: 720 remaining channel: 366 layer index: 56 total channel: 720 remaining channel: 366 layer index: 57 total channel: 160 remaining channel: 146 layer index: 59 total channel: 720 remaining channel: 587 rectify_layer index: 59 total channel: 720 remaining channel: 587 layer index: 60 total channel: 720 remaining channel: 587 layer index: 61 total channel: 320 remaining channel: 320 layer index: 62 total channel: 128 remaining channel: 123 rectify_layer index: 62 total channel: 128 remaining channel: 123 layer index: 63 total channel: 128 remaining channel: 123 layer index: 64 total channel: 256 remaining channel: 254 layer index: 71 total channel: 128 remaining channel: 127 rectify_layer index: 71 total channel: 128 remaining channel: 127 layer index: 72 total channel: 128 remaining channel: 127 layer index: 73 total channel: 256 remaining channel: 256 layer index: 80 total channel: 128 remaining channel: 128 rectify_layer index: 80 total channel: 128 remaining channel: 128 layer index: 81 total channel: 128 remaining channel: 128 layer index: 82 total channel: 256 remaining channel: 227 Prune channels: 2258 Prune ratio: 0.160 Model Summary: 195 layers, 2.08856e+06 parameters, 2.08856e+06 gradients, 3.2 GFLOPS
经过裁剪后,计算量从 3.6 GFLOPs 降到了 3.2 GFLOPs,性能却没有下降,mAP 仍为 0.957
+------------+----------+----------------------+
| Metric | Before | After prune channels |
+------------+----------+----------------------+
| mAP | 0.956695 | 0.956708 |
| Parameters | 2481151 | 2088557 |
| Inference | 0.0635 | 0.0621 |
+------------+----------+----------------------+
通道裁剪方案一
这里我使用 0.001 的学习率微调训练了 200 epoch,最终恢复到了 mAP=0.948
通道裁剪方案二
这里不需要 finetune 了
Stage3-2 层裁剪
这里仅考虑裁剪 shortcut 残差连接层的裁剪:
- 将每个残差模块最后一个卷积层(灰色)的 BN 层 gamma 参数求平均后排序,选择前 shortcuts 个模块来裁剪
- 去除待裁剪通道中 BN 层 beat 的影响(通过更新待裁剪层下一层的 conv-bias 或者 bn-running_mean 来实现)
prune_model_keep_size2
- 根据裁剪情况,定义新的网络(要注意 cancat 此类连接层索引连接的变化),并复制权重
裁剪一个残差连接试试手:
+------------+----------+----------------------+---------------------------+
| Metric | Before | After prune channels | After prune layers(final) |
+------------+----------+----------------------+---------------------------+
| mAP | 0.956695 | 0.956708 | 0.947334 |
| Parameters | 2481151 | 2088557 | 1958700 |
| Inference | 0.0277 | 0.0275 | 0.0257 |
+------------+----------+----------------------+---------------------------+
Stage4 微调网络
+------------+----------+----------------------+---------------------------+---------------------------+
| Metric | Before | After prune channels | After prune layers(final) | After finetune |
+------------+----------+----------------------+---------------------------+---------------------------+
| mAP | 0.956695 | 0.956708 | 0.947334 | 0.958092 |
| Parameters | 2481151 | 2088557 | 1958700 | 1958700 |
| Inference | 0.0277 | 0.0275 | 0.0257 | 0.0257 |
+------------+----------+----------------------+---------------------------+---------------------------+
Q2
裁剪工作属于循环进行的工作,套路就是先拿完整模型训练,然后再不断裁剪到合适性能为止。

