
深度学习笔记(十九)HAMBox: Delving into Online High-quality Anchors Mining for Detecting Outer Faces
keyword
outer faces:异常人脸,由于人脸尺度过小或者人脸尺度与anchor尺度不匹配,造成训练时匹配不到足够多的Anchor(小于阈值K),影响了这些人脸的召回。
HAMBox:Online High-quality Anchor Mining Strategy, 在线高质量锚框挖掘策略。
high-quality anchor:如果某个 Anchor 经过网络回归后的框与人脸框的 GT 的i IoU 大于0.5,则称其为高质量 Anchor。
matched anchor:在训练时,与目标人脸的 $IoU \ge 0.35$ 的anchor。
unmatched anchor:在训练时,与目标人脸的 $IoU<0.35$ 的anchor。
PBB:represents ‘Predicted Bounding Boxes’,即匹配的 Anchor 经过回归后的框。
CPBB:Correctly Predicted Bounding Boxes,匹配的 Anchor 经过回归后能与 GT 的 $IoU \ge 0.5$,则称其为CPBB,即 matched high-quality anchor 回归后的框。
Abstract
However, we observe that more than 80% correctly predicted bounding boxes are regressed from the unmatched anchors (the IoUs between anchors and target faces are lower than a threshold) in the inference phase.
作者发现,在前向推理中,居然有 80% 的正确回归框(Pre vs GT $IoU \ge 0.5$)是来自于未匹配的 Anchors( Anchor vs GT $IoU < 0.5$),这一现象惊呆了小伙伴们!这表明那些我们在训练阶段忽略的 Anchor(不参与回归训练) 居然出色的回归能力。基于此,作者提出了 HAMBox 来提升 outer faces 的性能。同时,作者强调这是 a general strategy,适用于 anchor-based single stage face detection。至于代码,说是会放在度娘的 PaddlePaddle 里。
Introduction
Current state-of-the-art face detectors are usually based on anchor-based deep CNNs, inspired by their successes on the general object detection.
Different from general object detectors, face detectors often face smaller variations of aspect ratios (from 1:1 to 1:1.5) but much larger scale variations (face area, from several pixels to thousands of pixels).
主流的人脸检测器也是和通用目标检测一样,是基于 anchor 设计的(当然 Anchor Free 也在高速发展)。但不同于 general object detectors 的是,人脸往往 aspect ratios 变化较小,但是 scale variations 很大。针对这一问题,有的方案是采用 FPN + Dense Anchors 的策略,但这会极大的增加推理耗时。从效率上来说,你设计的 Anchor 越简单高效越好。$S^3FD$ 论文中采用单一尺度和高宽比的 Anchor,这看起来可能会比较简单高效,但实际用的时候选择合适的锚定尺度仍然是一个很大的挑战,这通常是由以下的失准现象造成的:
 |
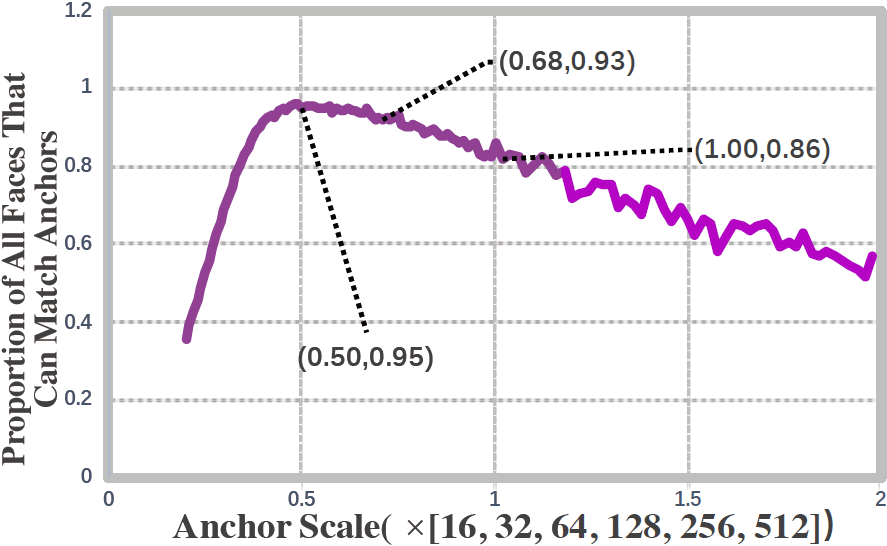 |
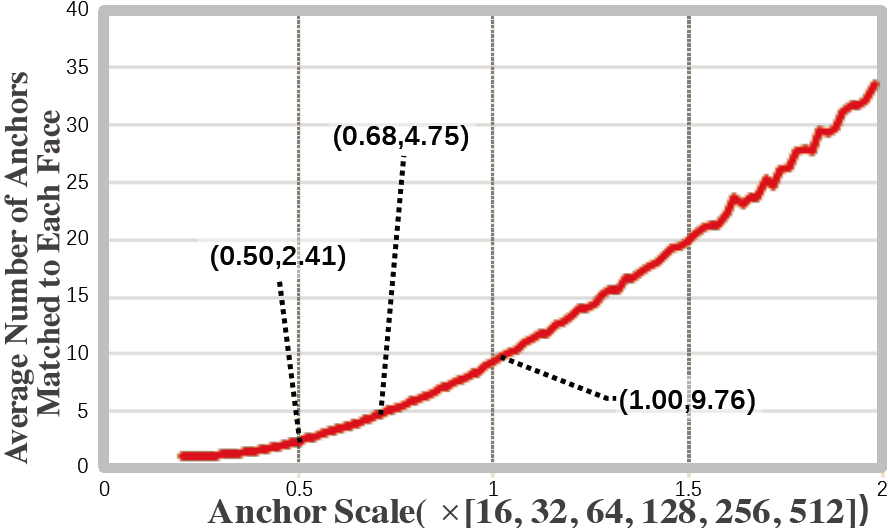
| (a) Average Number of Anchors Matched to Each Face | (b) Proportion of Faces that can Match with Anchors |
| Figure 1. Two crucial factors in designing anchor scales on the WIDER FACE dataset. (a) As the scale of anchor increases, the average number of anchors matched to each face also increases. (b) The proportion of faces that can match the anchors decreases significantly outside a specific interval ([0.43, 0.7]) | |
- the average number of anchors matched to each face:Figure 1(a) 表明可以通过增加 Anchor 的尺度来增加 GT 匹配的 Anchor 的数量,这其实和我自己做的实验是一致的(小目标匹配的 Anchor 数量少,大目标匹配的 Anchor 数量多)
- the proportion of all faces that can match the anchors:Figure 1(b) 则表明,单纯的增加 Anchor 的尺度到后期会导致匹配失败(一般是小目标无法匹配)的数量增加
因此,我们在设计 Anchor 的时候可以参考这两个方面。
$S^3FD$ 通过降低匹配阈值来强行为 outer face 匹配足够数目的 Anchor;EMO 论文中则通过 Expected Maximum Overlap 策略来获得合适的 anchor stride and receptive field。然而,通过实验观察到,这些补偿方法其实引入了大量低质量的anchor,其实表现也不是很好,见 Figure 2(b):
图中橄榄色表示的是训练过程中,传统的 Anchor 匹配策略下,这些匹配的 Anchor 回归后与 GT 的 IoU;紫色线则表示作者提出的 HAMBox 方法。可以看出,传统的匹配策略由于Anchor 的质量不高,平均回归 IoU 只有 0.4(而训练目标是要这些匹配 Anchor 都向着 GT 的方向去的);作者提出的 HAMBox 方法,平均回归 IoU 可以达到 0.8!
 |
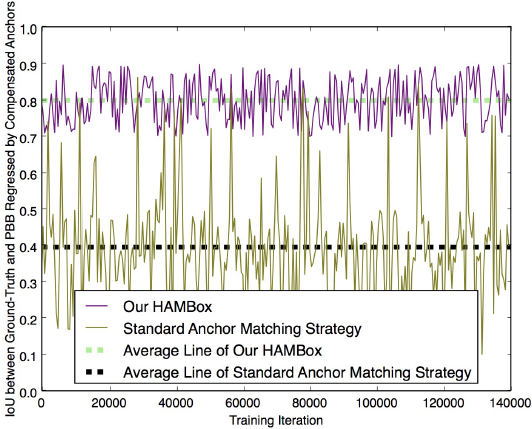 |
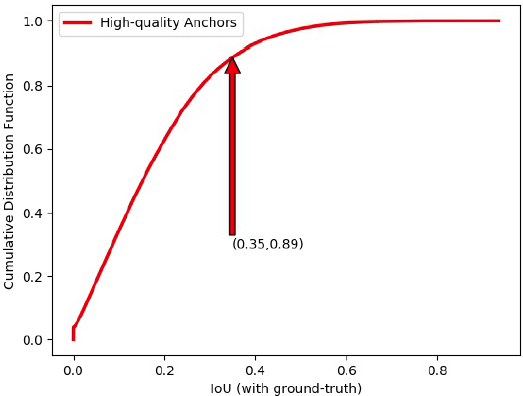
| (a) Cumulative Desity Curve of IoU | (b) Performance of Compensated Anchors |
 |
 |
| (c) Proportion of unmatched High-quality Anchors | (d) Performance of Matched High-quality Anchors |
|
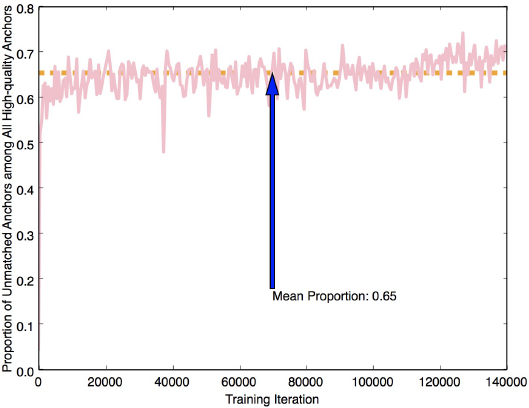
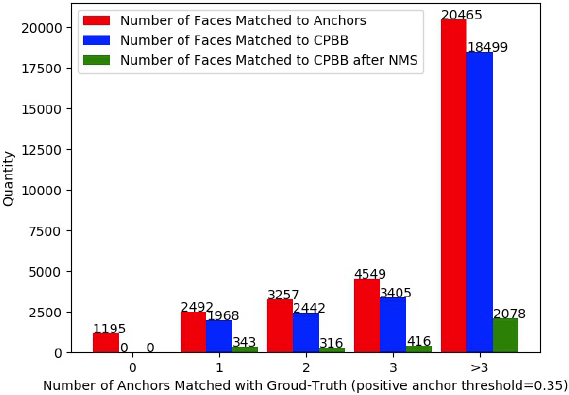
Figure 2. The problem of standard anchor matching strategy during training and inference (on the WIDER FACE dataset). (a) During inference, only 11% of all correctly predicted bounding boxes are regressed by matched anchors. (b) PBB represents ‘Predicted Bounding Boxes’. When using our HAMBox strategy, the IoUs between ground-truths and predicted bounding boxes regressed by compensated anchors are much higher than standard anchor matching strategy during training. (c) During training, the average number of unmatched high-quality anchors occupies a surprisingly 65% proportion of all high-quality anchors. (d) CPBB represents ‘Correctly Predicted Bounding Boxes’. During inference, the number of matched high-quality anchors dramatically decreases after NMS, representing some unmatched anchors have higher regression ability. All these results demonstrate that the standard anchor matching strategy can not utilize high-quality negative anchors effectively, which play essential roles whatever during training or inference. |
|
文中以 PyramidBox 为基准算法来研究了 Anchor Matching 的问题,如 Figure 2(a) 所示,横坐标是匹配阶段 high-quality anchor 与 GT 的 IoU,纵坐标是累计概率分布F(x)。可以看到匹配 $IoU \le 0.35$ 的 high-quality anchor 占所有 high-quality anchor 的 89%。也就是说,如果以 0.35 为匹配阈值,所有 Anchor 经过 regression 之后,high-quality-anchor 中只有 11% 的框是来源于匹配 Anchor,89% 的高质量 Anchor 竟然来源于负 Anchor(这些 Anchor 实际上并没有参与回归训练)!amazing!
而在训练阶段,如 Figure 2(c) ,所有 high-quanlity anchor 中,有65%是由 unmatched anchor 回归得到的。
Figure 2(d) 则进一步统计了 Matched Anchors 的表现:以横坐标为 1 的一组柱状图为例,以 0.35 为阈值的话,能匹配到 2 个 Anchor 的 GT 数量是 2492,这些匹配的 Anchor 经过回归后能与 GT $IoU \ge 0.5$,即 matched high-quality anchor 的数量变成了 1968,也就是说有 524 个 GT 由于原始匹配的框质量较差,难以通过回归网络来提升 IoU,因此无法召回。对于绿色柱状图我有点懵逼,我理解起来有两种解释。第一种解释是将所有的 matched high-quality anchor 经过 NMS 操作后却仅有 343 个 GT 被保留了下来,刨除掉目标相互遮挡的原因,这些 NMS 被丢掉的 GT 可能是由于分类得分低于阈值。这表明低质量的 Anchor 即使有可能回归好,最终还是会因为分类分数低而被干掉。第二种解释是 所有的 high-quality anchor(包括 matched high-quality anchor 和 unmatched high-quality anchor)经过NMS 操作后只剩下了 343 个 GT 被召回,其他 matched high-quality anchor 都被 unmatched high-quality anchor(分类分数比和它交叠的 matched high-quality anchor 还高) 给抑制掉了。估摸着第二种比较贴合论文,反正一句话就是,为了匹配 OuterFace 而增加的低质量的 Matched Anchors 大部分是个渣渣,并不能提升 OuterFace 的召回率!
基于这些问题,作者提出了 HAMBox 算法,旨在为 OuterFace 在线匹配更多的 high-quality-anchor,简而言之,该算法随着训练进行,逐渐为 OuterFace 挖掘 high-quality-anchor,从而获得更好的回归效果。在挖掘高质量 Anchor 之后,使用 regression-aware focal loss 来对新补偿得到的 high-quality anchor 的分类分支 loss 进行加权(based on IoU)。
 |
| Figure 3. Visualization of the quality of compensated anchors through two methods. In the early stage of training, our method does not compensate anchors for outer faces. Then with the increasing of training iteration, our method is gradually mining unmatched high-quality anchors for outer ones, which have higher IoU than anchors generated by standard anchor matching strategy. |
Figure 3 和 之前的 Figure 2(b) 表明了作者提出的 HAMBox 比标注的 Anchor Matching Strategy 要更流弊。Figure 3 中,当使用 standard anchor matching strategy 时,unmatched anchors 被标记为负样本,随着训练迭代的进行自身也能回归的不差。而但使用 Online High-quality Anchor Compensation Strategy 时,一开始并不对 OuterFace 进行补偿,随着迭代的深入才不断挖掘 unmatched high-quality anchors,这些被挖掘出来的 Anchor 比 standard anchor matching strategy 回归出来的更好。
Anchor-based Set
首先为了提高匹配效果,将原有的 Anchor Scales {16, 32, 64, 128, 256, 512} * 0.68
Online High-quality Anchor Mining
本文实验以 RetinaNet 作为 baseline。主干网络是 ResNet-50,按照 $S^3FD$ 论文中的设置 employ the feature map of conv2 layer to improve the performance of face detector. The reason is that around 40% faces are matched to conv2 anchors on the WIDER FACE benchmark. 同时,不同于 general object detection,作者每个检测尺度上仅设计 only one anchor scale and one aspect ratio Anchor。这么做的话好处就是大大降低了 Anchor 的数量,缺点是会降低模型的性能。作者称这个缺点会被后续的方案给弥补。
Online Highquality Anchor Compensation Strategy
 |
||
| (a) Face Matched to Anchor on the First Step of Standard Anchor Matching Strategy | (b) Face Matched to Anchor on the Second Step of Standard Anchor Matching Strategy | (c) Cummulative Density Curve of IoU |
| Figure 4. (a) (b) Two different stages on standard anchor matching strategy, the blue rectangle represents ground-truth and the red one is an anchor matched with it. (c) Cumulative Density Curve of IoU between ground-truth and its matched anchor on different stages. | ||
如 Figure 4 所示,通用的 Anchor 匹配过程(用来决定正负样本)分为两个 step:
step1. 同常规匹配一样,每个 GT 首先和 Anchor 按照 IoU threshold 的标准进行匹配。
step2. 如果 GT 找不到匹配则选择一个最大 IoU 的 Anchor 作为匹配。
Figure 4(c) 展示了一个问题:按照 IoU 强行补偿的 Anchor 会带低整体回归性能!
作者提出的 Online Highquality Anchor Compensation Strategy 是这么匹配的:
step1. 同上面第一步一样,用 IoU threshold 阈值作为匹配标准,如果匹配数量 $D$ 超过 $K$,该 GT 不需要补偿,否则需要补偿 $K - D$。
step2. 在前向传播完成后,将回归后的 Anchor($B_{reg}$)同所有需要补偿的 GT($F_{outer}$) 尝试匹配(之前某个 GT 已经匹配了 $D$ 个 Anchor 了)。具体的,首先按照 IoU阈值 $T$ 大小先选出 $N$ 个 unmatched anchor 并排序(从大到小) 作为候选。然后将这 $max{N, k-D}$ 个补偿 Anchor 作为正样本参与 loss 计算。作者通过实验对比出来,$T=0.8, K=3$ 效果最好。
Regressionaware Focal Loss
作者还为这些补偿 Anchor 加上了 IoU 相关的分类权重。
同时满足下面三个条件的 Anchor 不需要增加权重:
1. 属于 high-quality anchors,即经过回归和 GT 的 $IoU \ge 0.5$
2. 但是 step1 中被分配为负样本的 anchor(step1 中 IoU 不够格)
3. 最后也没有被补偿成正样本的 anchor(step2 也还是没能转正)
改进的 Focal Loss 定义为:
\begin{equation}
\label{conf loss}
\begin{split}
& L_{cls}(p_i) = \frac{1}{N_{com}} \sum_{i \in \psi} F_i L_{fl} (p_i, g_i^*) \\
& + \frac{1}{N_{com}} \sum_{i \in \Omega} (1_{(l_i^*=0)}1_{(F_i<0.5)} + 1_{(l_i^*=1)}) L_{fl} (p_i, l_i^*) \\
\end{split}
\end{equation}
意思就是,虽然你这个 Anchor 很吊,但是你没通过我们的考核也就不能转正,这种样本就不管了你死活了(不参与 Loss 计算),爱咋滴咋滴!
公式什么的最烦人了,这里 $F_i$ 是 IoU(回归后的)

