
深度学习笔记(十六)Faster RCNN + FPN (PyTorch)
之前虽然也了解一丢丢的 Faster RCNN,但却一直没用过,因此一直都是一知半解状态。这里结合书中描述和 PyTorch 官方代码来好好瞅瞅。
论文:
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Feature Pyramid Networks for Object Detection
一. 总览
Faster RCNN 从功能模块来看,可大致分为 特征提取,RPN,RoI Pooling,RCNN 四个模块,这里代码上选择了 ResNet50 + FPN 作为主干网络:
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=False)
1.1 特征提取
这里不用多说,就是选个合适的 Backbone 罢了,不过为了提升特征的判决性,一般会采用 FPN 的结构(自下而上、自上而下、横向连接、卷积融合)。
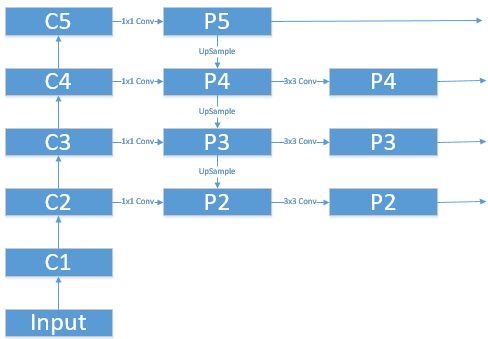
1.2 RPN
这部分其实可以看成 One-Stage 检测器的检测输出部分。实际上对于只检测一类目标来说,可以直接拿去用了。RPN 在 Faster RCNN 中的作用是,结合先验的 Anchor,将背景和前景区分开来(二分类),这样的话大量的先验 Anchor 就可以被筛选出来,并作些许的回归(使得 Anchor 更接近于真实目标)。
1.3 RoI Pooling
这部分将结合上一步得到的 refine 后的 Anchor 和特征提取网络中的 feature map。将这些 Anchor 映射到 feature map 上并通过 Pooling 操作将这些代表 anchor 的 feature 拉到同一维度。这样的话就可以拿去给 RCNN 做最后更细致的多分类和回归了。
1.4 RCNN
这里将 RoI Pooling 得到的特征送入后面的网络中,预测每一个 RoI 的分类和边界框回归。
二. RPN
2.1 Anchor Generator
以官方 PyTorch torchvision 里的 Faster RCNN 代码为例:输入图片尺度为 768x1344,5 个 feature map 分别经过了 stride=(4, 8, 16, 32, 64),得到了 5 个大小为 (192x336, 96x168, 48x84, 24x42, 12x21) 的 feature。
代码中预定义了 5 个尺度(32, 64, 128, 256, 512) ,3 种 aspect_ratio (0.5, 1.0, 2.0) 的 Anchor。这样的话我们可以得到 5 组 base_anchor, 每一组包含 3 个面积相同,宽高比不同的以原点为中心点的基础锚框。
[-23., -11., 23., 11.] [-45., -23., 45., 23.] [-91., -45., 91., 45.]
[-16., -16., 16., 16.] [-32., -32., 32., 32.] [-64., -64., 64., 64.]
[-11., -23., 11., 23.] [-23., -45., 23., 45.] [-45., -91., 45., 91.]
[-181., -91., 181., 91.] [-362., -181., 362., 181.]
[-128., -128., 128., 128.] [-256., -256., 256., 256.]
[ -91., -181., 91., 181.] [-181., -362., 181., 362.]
然后将这些 base_anchor 撒到对应的 feature map 上(起点是 [0,0])。这样的话共有:
(192*336*3=193536) + (96x168*3=48384) + (48*84*3=12096) + (24*42*3=3024) + (12*21*3=756) = 257796 个 Anchor
具体参考 torchvision/models/detection/rpn.py
anchors = self.anchor_generator(images, features)
2.2 RPN Head
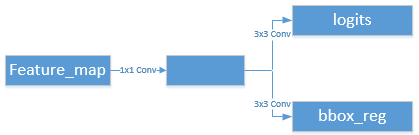
这部分很简单,就是将特征提取网络获得的 feature map 先经过一个 1x1 的卷积操作,然后分别用两个 3x3 的卷积进行分类和回归操作。以大小是 256x48x84 的 feature map 为例,经过 1x1 的卷积操作(不改变特征图尺寸),假定 feature map 上的宽高平面上每个点有 3 个 Anchor (宽高比分别是 0.5, 1.0, 2.0),那个分类支路上的 3x3 卷积输出维度是 3x48x84,而回归支路上的 3x3 卷积输出维度是 12x48x84。
有多少 Anchor 就有多少分类和回归结果,最终多个尺度(FPN 5 个尺度)cancat 后的分类维度为 257796x1, 回归维度为 257796x4。值得注意的是这里的回归结果是基于编码后的 Anchor 的偏移量。说道这里就要将下 Faster RCNN 里的 encode 和 decode 过程。区别于之前的 SSD 和 YOLOV3 两个检测算法的编解码方式:
记 $x, y, w, h$ 是检测框的中心点坐标和宽高,$x, x_a, x^*$ 分别代表检测框、Anchor 和 GT 的对象坐标, $t_x$ 是检测偏移量。
解码:
参考 torchvision/models/detection/rpn.py
proposals = self.box_coder.decode(pred_bbox_deltas.detach(), anchors)
\begin{equation}
\label{decode}
\begin{split}
& x = t_x * w_a + x_a \\
& y = t_y * h_a + y_a \\
& w = e^{t_w} * w_a \\
& h = e^{t_h} * h_a \\
\end{split}
\end{equation}
同理,在计算 loss 时我们需要将 GT 进行编码
编码:
参考 torchvision/models/detection/rpn.py
regression_targets = self.box_coder.encode(matched_gt_boxes, anchors)
\begin{equation}
\label{encode}
\begin{split}
& t_x^* = (x^* - x_a) / w_a \\
& t_y^* = (y^* - y_a) / h_a \\
& t_w^* = log(\frac{w^*}{w_a}) \\
& t_h^* = log(\frac{h^*}{h_a}) \\
\end{split}
\end{equation}
解码后就将 Anchor + BBox_reg 转换成了 Proposal 了, 注意每个 Proposal 的物理意义是输入图片上的(xmin, ymin, xmax, ymax) 。
2.3 筛选 Proposal
首先每个检测尺度上筛选出前 min(pre_nms_top_n, num_anchors) 个 anchor(上面 257796 个 Proposal 就会筛选出 4756 个),用 scale_level 来标记每个 Proposal 的尺度等级,值域集合为 {0, 1, 2, 3, 4};
随后对这些筛选出来的 Proposal, 按照 clip, remove_small_boxes, 每个尺度上分别做 nms(具体实现时是把所有的 Proposal + (scale_level * Proposal.max()) 来加速操作的)至多保留 post_nms_top_n 个 Proposal。
具体参考 torchvision/models/detection/rpn.py
boxes, scores = self.filter_proposals(proposals, objectness, images.image_sizes, num_anchors_per_level)
三. RoI Pooling
有了筛选出来的 Proposal,我们就可以将映射到某个 feature map 上然后利用 RoI Pooling 提取每个 Proposal 的特征供后续的 rcnn 细致的分类和回归了。
参考 torchvision/models/detection/roi_heads.py
box_features = self.box_roi_pool(features, proposals, image_shapes)
代码中只选择了其中 4 个尺度来进行操作(最小的那个 feature map 没有用到)。
因为是多尺度特征,把每个 Proposal 映射到哪个 feature_map 上是个问题,代码是用 LevelMapper 这玩意来操作的, 理论参考 RPN 论文 。
\begin{equation}
\label{level}
k = \lfloor k_0 + log2(\sqrt{wh}/224) \rfloor
\end{equation}
其中 $k_0$ 是一个面积为 224*224 的 Proposal 应该处于的 feature map level。其他尺度的 Proposal 按照上面的公式安排 feature map level。
代码中选择的 256x48x84 这个尺度的 feature map 为 $k_0$, 对应 224*224 这个大小范围的 Proposal。
随后使用 roi_align 提取每个 Proposal 的特征
参考 torchvision/ops/poolers.py
result_idx_in_level = roi_align( per_level_feature, rois_per_level, output_size=self.output_size, spatial_scale=scale, sampling_ratio=self.sampling_ratio)
这样的话 我们就可以获得 post_nms_top_n 个 256 x 7 x7 维度的前景框的特征。最后 flatten 特征维度接上两个全连接层获得 post_nms_top_n 个 1024 维度的特征。
四. RCNN
这部分很简单,就是两个全连接层,一个用于分类,一个用于回归。
参考 torchvision/models/detection/faster_rcnn.py 里的 class FastRCNNPredictor(nn.Module)
self.cls_score = nn.Linear(in_channels, num_classes)
self.bbox_pred = nn.Linear(in_channels, num_classes * 4)

