
学堂在线视频字幕抓取2_油猴脚本编写
正文
写在最前:互联网并非法外之地,爬虫仅供技术交流
运行环境
-
Tampermonkey 4.3.6
-
ECMAScript5(虽然选择了5,但是还是用了ES6的语法)
爬取目标
- 每个学堂在线的视频和导学资源下载
效果呈现
- 视频界面的下载按钮可以下载高清或标清的视频
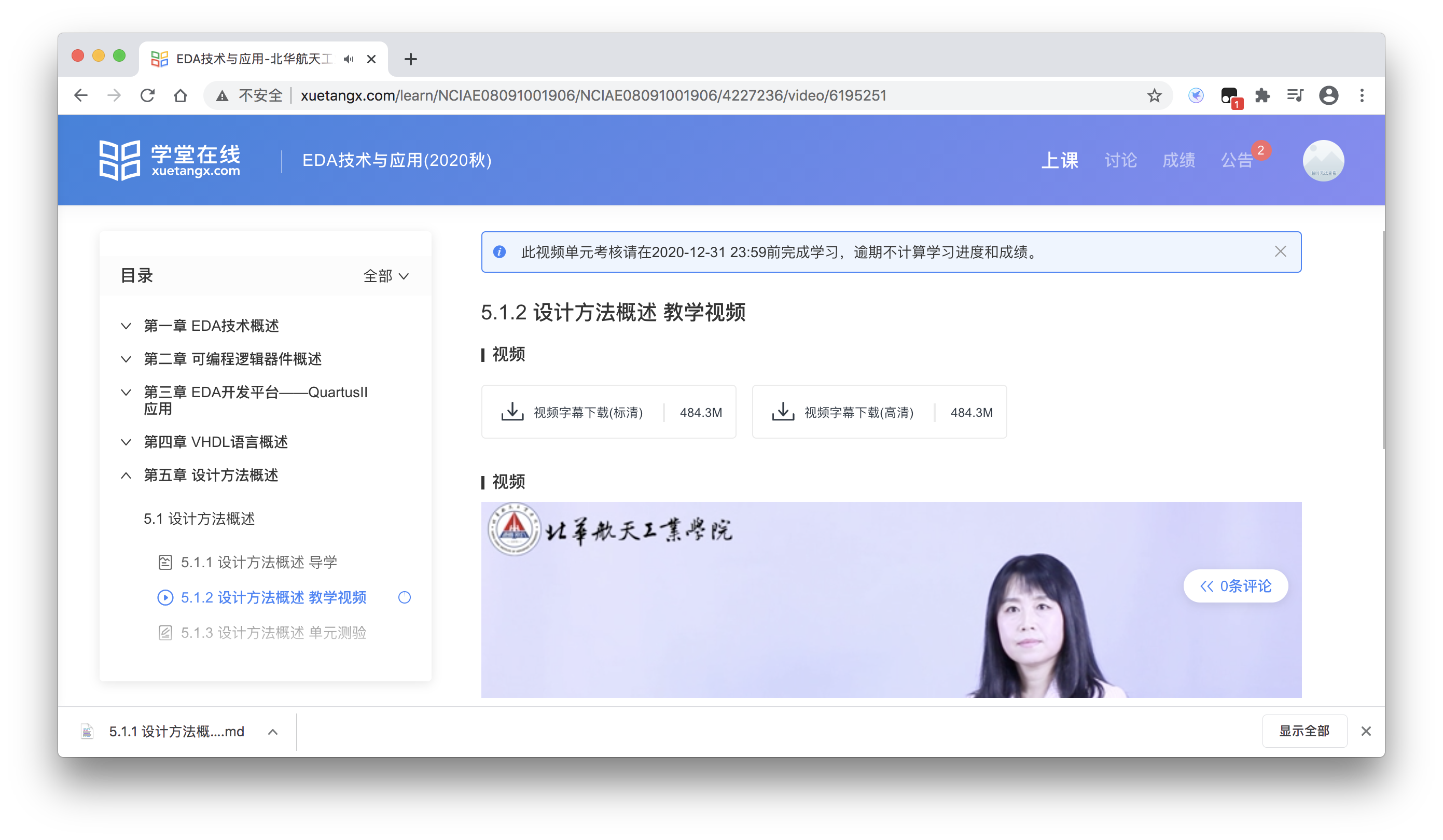
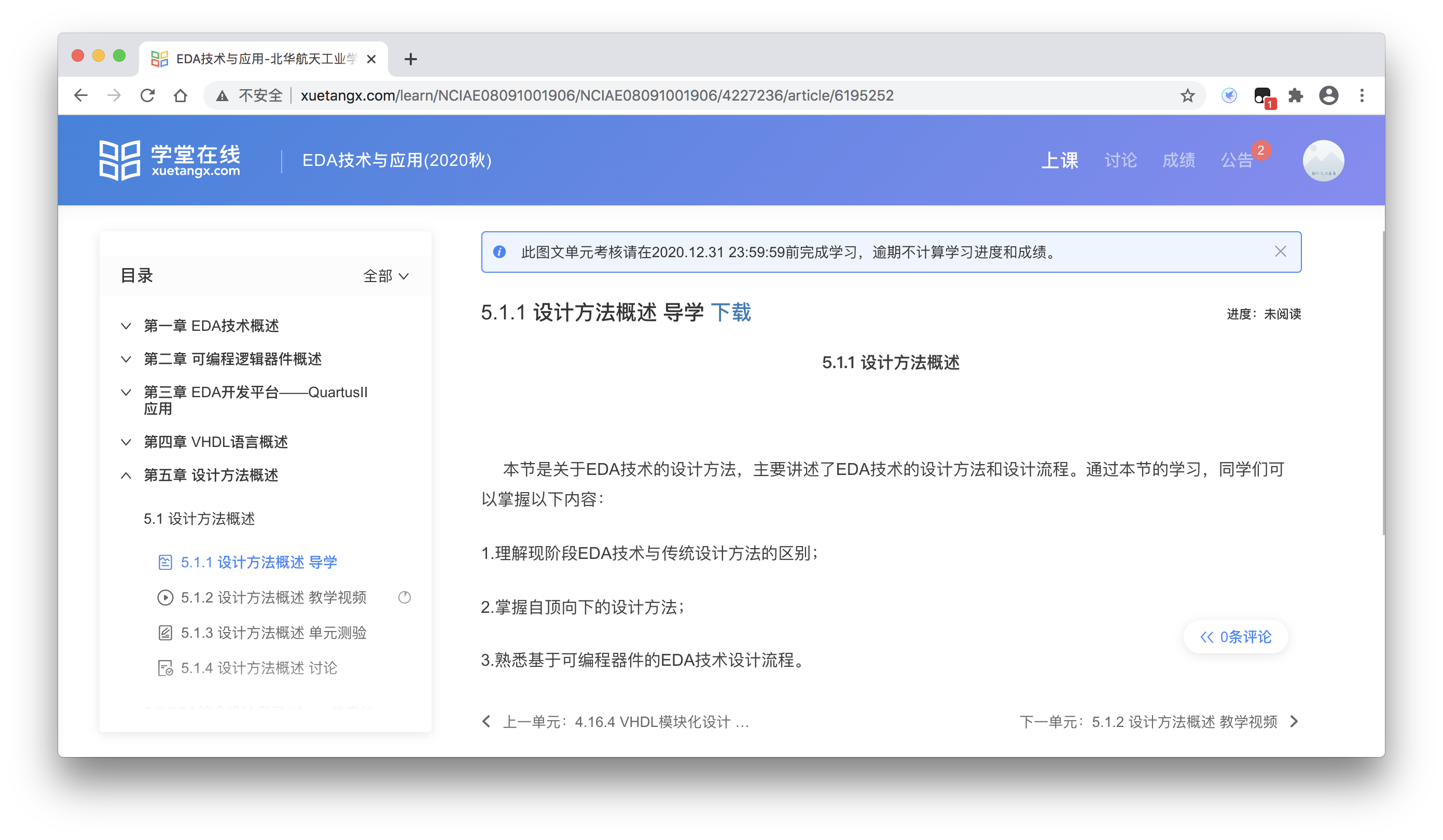
- 导学界面的下载按钮可以下载导学的markdown文件,这个用到了turndown这个第三方库
油猴脚本的编写
上次的文章已经介绍过怎么用python来编写爬取视频字幕。
但还没有做字幕转换,这次用油猴脚本来实现,并把字幕存成srt格式。
脚本的两个链接
脚本编写的核心逻辑
具体的就不细写了,可以看代码。
-
第一个关键主要就是上一篇文章推导出来的爬取步骤
-
第二个关键就是字幕的转换,把它从json格式的文件转成srt
json文件里面提供了他的开始时间、结束时间和文本。
对应到srt的文件就是
1 hh:mm:ss.uuu(开始时间) --> hh:mm:ss.uuu(结束时间) text(文本) -
第三个关键就是文件的下载
由于视频和网站的域名不一样,利用a标签设置download属性无效。所以利用url跳转来实现。
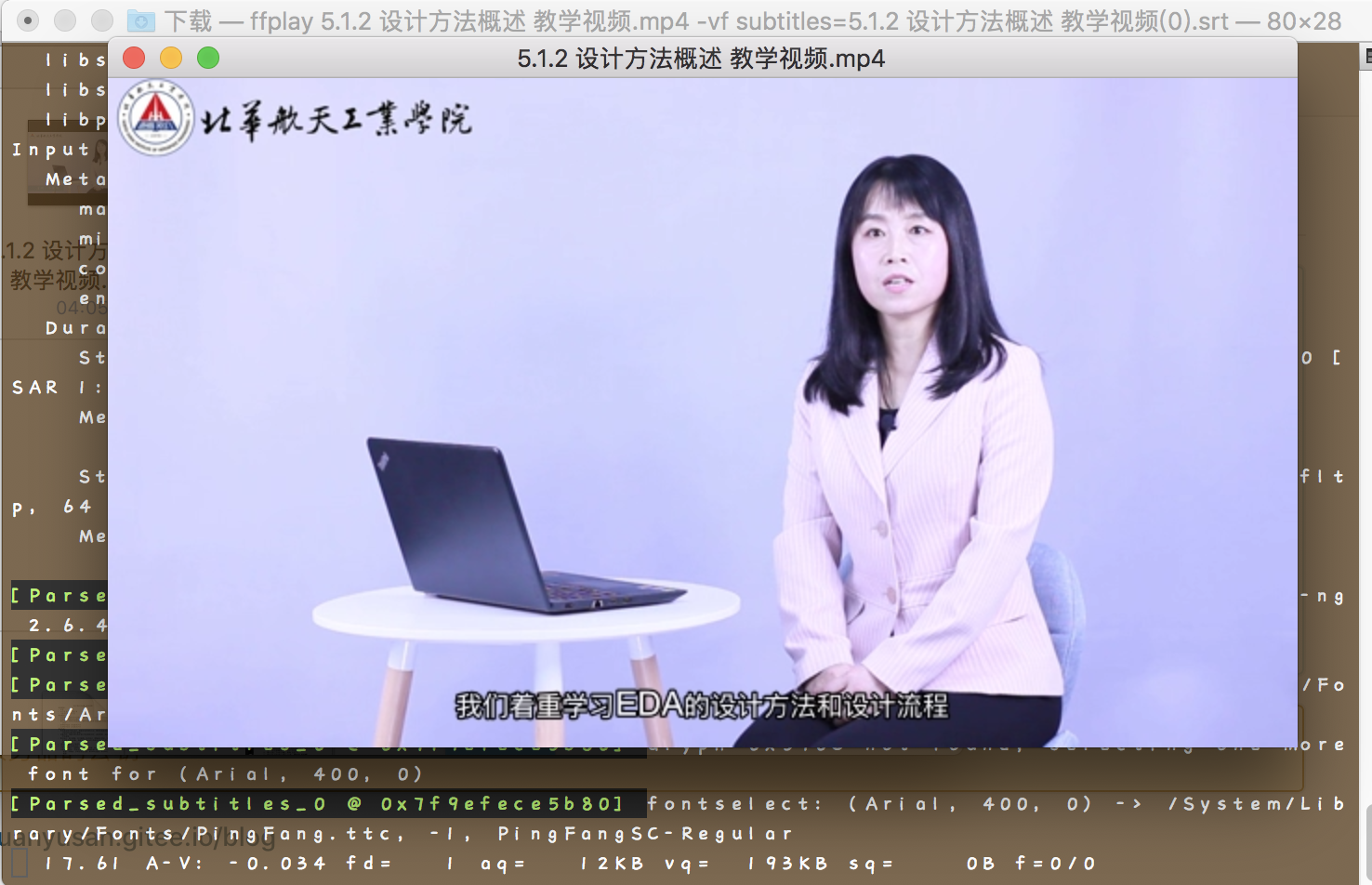
苹果电脑的播放测试
ffplay 5.1.2\ 设计方法概述\ 教学视频.mp4 -vf subtitles=5.1.2\ 设计方法概述\ 教学视频\(0\).srt
另外提供的一种方案
给不需要字幕的,也不希望下载油猴插件的人提供一种简便的视频下载方法。
右键视频 => 检查元素 => 找到mp4资源连接 => 新窗口打开 => 右键另存为
一键下载的方案
以现在的爬取经验来说,是可以做到在python中输入课程名字,选择学期,然后就爬取该课程的所有视频的。后期如果完成会接着更新。
试探性地留下名字



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 托管堆内存泄露/CPU异常的常见思路
· PostgreSQL 和 SQL Server 在统计信息维护中的关键差异
· C++代码改造为UTF-8编码问题的总结
· DeepSeek 解答了困扰我五年的技术问题
· 为什么说在企业级应用开发中,后端往往是效率杀手?
· 清华大学推出第四讲使用 DeepSeek + DeepResearch 让科研像聊天一样简单!
· 推荐几款开源且免费的 .NET MAUI 组件库
· 实操Deepseek接入个人知识库
· 易语言 —— 开山篇
· Trae初体验