
Heterogeneous Multi-task Learning for Human Pose Estimation with Deep Convolutional Neural Network
论文题目Heterogeneous Multi-task Learning for Human Pose Estimation with Deep Convolutional Neural Network, 链接
该篇论文是IJCV 2014的, 文章的核心multi-tasks的joint traning.
直接看图说话, 该论文的核心思想/步骤可以分为两个components:
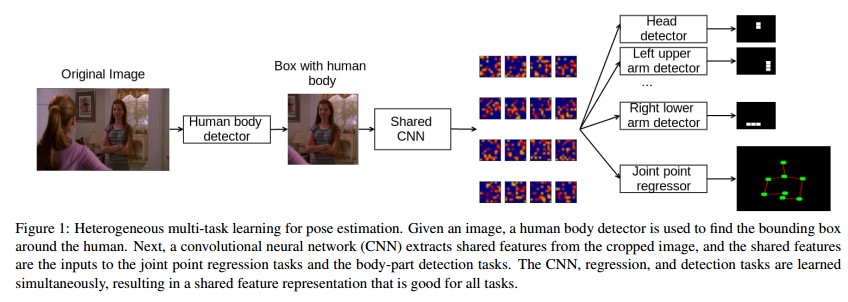
1对图像里面的person进行detection, 以便裁剪出图像里面的人.
这个显然是必要的, 尤其是图像大而person小, 或者图像里面的人较多时(>= 2 people)
由于这部分不是该论文里面的重点, 这点在此就不阐述了,
有兴趣的童鞋, 可以自行看一些person detection(或者行人检测)的论文之类的.
2该论文的重头戏, pose estimation in still image. 下面将详细阐述该部分
Pose Estimation:
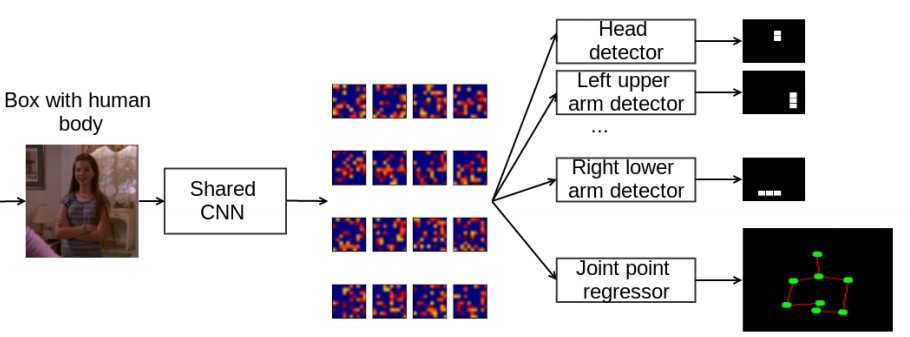
还是直接看图:
1上图中输入是裁剪好的图像(根据由human body detector得到的bounding box around the human来获取)
2 显然输入除了cropped image还需要对应的labels. 这里的labels就是对应cropped image的joints'/parts'的coordinates.
显然为了获得更好的perfomace, 往往需要对labels进行归一化. 论文里的归一化比较简单:
x = x / width, y = y / height. 这里的(width和height)是cropped image的高宽.
3 在继续讲解之前, 需要声明一点:
论文里面的joint是指人体关节点,
而part则是多个joints形成的一个更大的joint,
论文里面的part指相邻两个joints形成的stickmen, (简称火柴人), 如下图红色的线段(segment line).
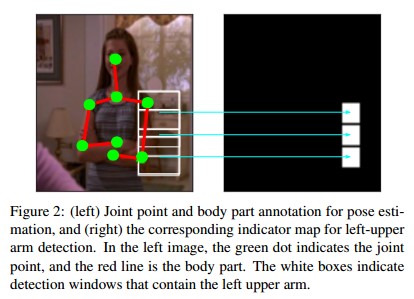
4 重头戏来了:
训练过程:
提到训练, 就必须提到训练的输入是啥了:
image: 根据person detection结果crop出来的image
label: 这里有两个:
joint regressor: 归一化后的joint的坐标(x1 y1 x2 y2 ...)
part detector: part heat map
主要说下ground-truth part heat map的产生:
论文里面假定heat map的大小为7 * 7, 总共8个parts.
heat map的每个pixel都可以通过network来找到对应的input image的感受野,
每个感受野都可以作为一个sliding window.
如果该感受野包括了该part的segment line的r%, 这里的r设为50.
这该pixel的值就设为1, 否则设为0.

对于每个part都这样做, 就可以产生其对应的ground-truth的heat maps.
那么对应的loss怎么确定?
joint regressor:
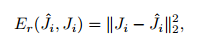
part detector:
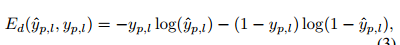
multi-tasks的loss为:
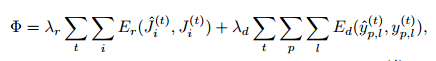
一旦输入(image & labels)弄好和loss fucntion定义好, 剩下的就是network的forward & backward了.
测试过程:
给定训练好的model和裁剪好的image, 其中在测试时, part detector是不要的.
将image作为model的输入, forward获取joint regressor的结果, 并进行反归一化,
得到image坐标系下的坐标, 作为最后的预测结果.
整体来说, 该论文的contribution: multi-tasks learning.
貌似这个已经给用烂了, 也没有什么好说的.
从效果上看, 还可以吧.
不足之处, 显然是通过网络将输入图像映射到pose空间上, 即通过全连接层直接回归pose的坐标.
至于为什么, 可以去看看google的"deeppose"论文,
以及lecun的"Efficient Object Localization Using Convolutional Networks"论文.
(请各位客官自行google这些论文, 后续会对它们进行详细的介绍的, 敬请下次更精彩...)

