

Modeling Video Evolution For Action Recognition - cvpr - 2015
论文题目Modeling Video Evolution For Action Recognition, 链接
该篇论文是CVPR 2015的, 文章的核心是feature descriptors的获取.
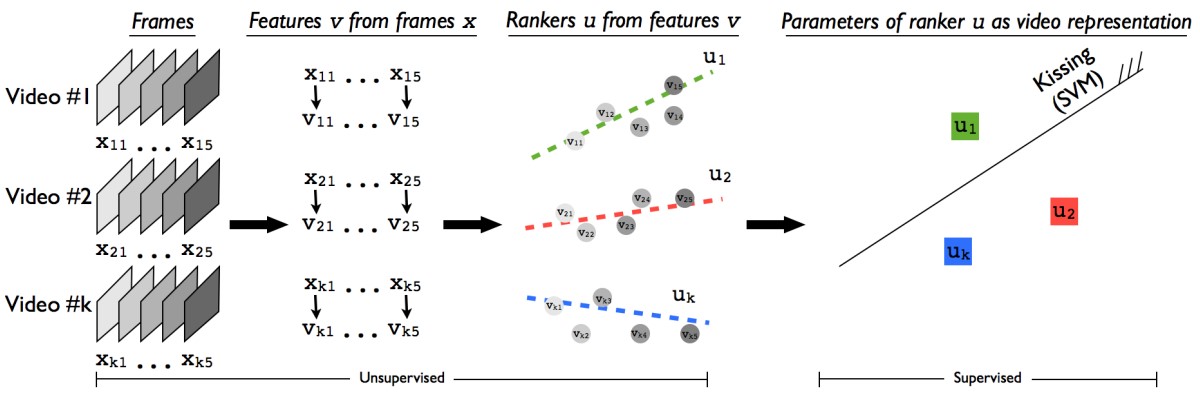
直接看图说话:
该论文的核心思想/步骤是:
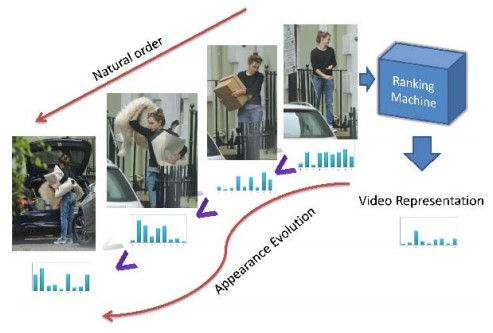
1 利用一些现有的feature来表征video每帧的, 如论文里的Xi, 利用时间因子t来进一步提取特征, 如论文里的Xt, 用来表征video的appearance和motion的evolution.
这里的Xt的计算比较有意思, 值得参考.
2 基于这样的假设: evolution over time t可以表征video的action信息, 也就是越往后的帧对于action来说, 越具有判别性. 训练一个ranking function.
即学习video里的{Xt}的order relationship.
论文里面提到ranking function是unsurpervised的, 也就是ranking的label是隐式给出的, 即上面的假设;
基于这样的数据, 训练一个rankSVM的ranking function/machine. (当然这里可以是任意线性的ranking function)
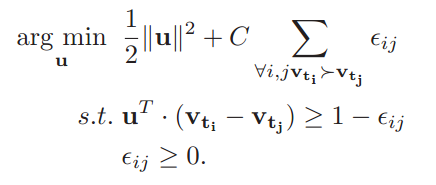
这些ranking function/machine学习到evolution如下图所示
3 将训练好的ranking function/machine的参数向量作为video的representation Ui.
4 {Ui, Yi}作为action classification的数据集, 训练non-linear svm的action classifiers, 对action进行分类.
总的来说, 个人觉得该论文的亮点是:
1 不同于以往的特征, 如HOG, HOF, MBH等, 用ranking function/machine的参数向量作为video的representation, 这个比较有意思.
2 不论是ranking funciton还是classification的svm, 都容易重现.
3 论文中的Xt的计算, 简单有效.
但是还是有不足之处的:
1 每个视频都需要单独训练一个ranking function/machine, 这个不适合online.
2 ranking的order label的假设是有缺陷的, 即
是不合理的. (大家想想为什么?)
3 整个流程还是非常pipeline的.
好吧, 不会吐槽, 莫怪, 莫怪.
欢迎前来骚扰...
